Introduction
In the rapidly evolving landscape of Artificial Intelligence (AI) and data-intensive workloads, selecting the appropriate processor plays a major role. There are many processors available in the market, varying on different parameters. This article provides a comprehensive analysis of two prominent Graphics Processing Units (GPUs): the L4 Graphics Processor and the A100 PCIe Graphics Processor (in both 40GB and 80GB variants). Selecting the right graphics processor can significantly impact the efficiency and accuracy of tasks ranging from deep learning and machine learning to data analytics and scientific simulations. Selecting the appropriate GPU becomes essential for optimizing performance, reducing processing times, and enabling the execution of intricate AI algorithms. By understanding the specifications and capabilities of the L4 and A100 PCIe GPUs, readers will be better equipped to evaluate which solution aligns with their AI workload demands.
Specifications
This section discusses the detailed technical specifications of the L4 and the A100 PCIe GPUs (both 40GB and 80GB variants).
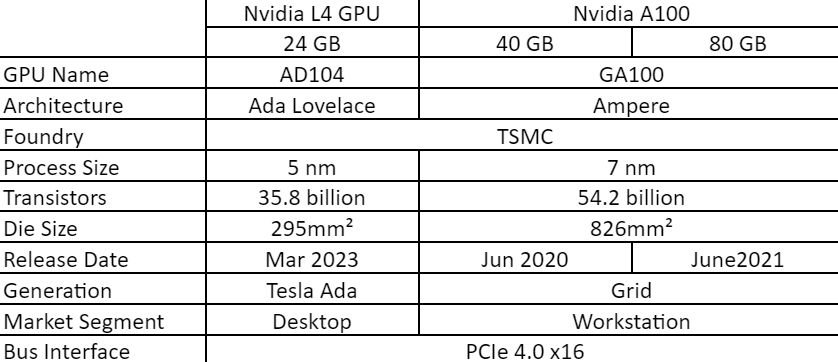
The technical specifications provided above offer a snapshot of the key differences between the L4 Graphics Processor and the A100 PCIe Graphics Processor variants. The L4, featuring the Ada Lovelace architecture and a 5 nm process size, is designed for desktop applications. On the other hand, the A100 PCIe Graphics Processor, built on the Ampere architecture and available in both 40GB and 80GB variants, caters to workstation demands. The A100 has higher transistors count, larger die size. They both have the same bus interface. L4 is the new version, howeverA100 is superior in every way. It is worth noting that L4 has reduced performance since it is sufficient for desktop applications, when compared to A100, that can be used for workstation capabilities, which is the main application and criteria for decision. We will explore the remaining details in the upcoming sections to reach a decision.
Render Configuration and Performance
This section discussed the render configurations and performance metrics of the L4 Graphics Processor and the A100 PCIe Graphics Processor (both 40GB and 80GB variants). These specifications play a crucial role in determining how well each graphics processor handles AI workloads, including tasks such as deep learning training, inference, and complex simulations.

These render configurations and performance metrics showcase the distinct capabilities of each graphics processor. The L4 offers an impressive number of shading units, tensor cores, and ray tracing cores, making it well-suited for tasks that demand substantial parallelism and AI-specific capabilities. On the other hand, the A100 PCIe Graphics Processor variants excel in areas such as memory bandwidth, cache size, and memory capacity, making them ideal choices for AI training and complex simulations.
Graphic Feature Specification
In this section, we will compare the graphic feature specifications of the L4 Graphics Processor and the A100 PCIe Graphics Processor (both 40GB and 80GB variants). These features have a significant impact on the compatibility and performance of AI workloads, ensuring seamless execution of graphics-intensive tasks and AI-driven simulations.

The graphic feature specifications highlight the compatibility of each graphics processor with various graphics and AI frameworks. The L4 Graphics Processor exhibits support for the latest versions of DirectX, OpenGL, OpenCL, Vulkan, CUDA, and shader models, enabling it to handle a wide range of applications.
DirectX support is used for multimedia, gaming, and Video, while OpenGL is used for embedded video and graphics. Similarly, Vulkan is used for better image processing. Shader model is an integrated part of DirectX. L4 supports all these making it well suitable for gaming, video processing, image processing, and real time multimedia.
A100 supports only OpenCL and CUDA, which make it good enough for complex coding applications involving Deep Learning. These are supported by L4 as well. While comparing L4 and A100 with respect to graphics, L4 is superior in every way. These specifications underline the versatile nature of the L4 Graphics Processor for tasks that involve both AI and graphics processing, while the A100 PCIe Graphics Processor variants excel in pure AI applications.
Capabilities
This section highlights the capabilities of both the GPUs when it comes to AI workloads. These capabilities span various domains, including deep learning, machine learning, data analytics, and scientific computing.
- Deep Learning: L4 has a substantial number of shading units, tensor cores, and ray tracing cores, hence L4 can efficiently accelerate deep learning tasks, including training and inference, by parallelization computations and optimizing model performance. On the other hand, A100 has higher Tensor cores, TMU ROs, and memory size, making it excel in AI model training and large-scale deep learning tasks, offering accelerated convergence and performance improvements.
- Machine Learning: Both L4 and A100 have great architectural features, including their tensor cores and CUDA support, enable fast matrix calculations and optimization, making them suitable for machine learning tasks that require iterative computations and model tuning.
- Data Analytics: Both GPUs have high memory bandwidth and cache sizes, which facilitate rapid data access and processing, supporting data-intensive analytics tasks for real-time insights from vast datasets quickly. Comparitively, A100 has a higher capacity for data analytics due to its larger memory size.
- Scientific Computing: The L4's parallel processing capabilities, combined with its robust memory subsystem, contribute to accelerating scientific simulations and computations, enhancing research and simulations in various scientific fields.
Both the L4 and A100 PCIe Graphics Processor variants bring significant capabilities to the table when it comes to AI workloads. The choice between them largely depends on the specific AI mode, use case, and requirements of the task at hand. In the next section, we will explore the types of AI modes that each graphics processor is ideally suited for, providing a roadmap for decision-makers to determine the best fit for their projects.
AI Modes
In this section, we will explore the AI modes and how the GPU would align with different AI workload requirements.
- Training: Both the L4 and A100 variants offer capabilities for AI model training, with the A100 variants excelling in this aspect due to their substantial tensor core count and memory bandwidth. The A100 GPUs are especially well-suited for training large neural network architectures and handling extensive datasets.
- Inference: All three graphics processors are adept at AI inference tasks, making them suitable for real-time applications such as image recognition, natural language processing, and recommendation systems. The efficient execution of AI models during inference enables quick responses and seamless user experiences.
- Mixed Precision Training: The A100 variants, with their optimized tensor cores, stand out in mixed precision training. They provide significant speed-ups in training times while maintaining model accuracy by leveraging lower-precision calculations. However, L4 would also work well to a certain extent for smaller data.
- AI-Driven Simulations: The L4 and A100 variants can both be utilized for AI-driven simulations. Their parallel processing capabilities, combined with specialized AI cores in the A100 GPUs, make them suitable for simulations in scientific research, engineering, gaming environments, and more.
The choice between the L4 and A100 PCIe Graphics Processor variants will depend on the specific requirements of AI modes, use cases, and performance expectations. The subsequent section will guide readers on how to make an informed decision when choosing between these GPUs.
Choosing the Right Graphics Processor
Selecting between the L4 and A100 PCIe Graphics Processor variants (40GB/80GB) involves a strategic evaluation of your specific requirements, budget constraints, and the performance demands of your AI workloads. Here's a customized guide based on cost considerations to help you make an informed decision:
Workload Requirements
- It is necessary to estimate the proportion of your AI tasks that involve model training versus real-time inference. If the training involves multimedia or images, L4 would suit better, while A100 can be used for large data and for deep learning applications.
- If mixed precision training is a priority, the A100's optimized tensor cores can expedite training without sacrificing accuracy.
- Complexity and data size is another major factor. Larger models can make use of A100's enhanced memory capacity and tensor core count.
Budget Constraints
- The initial investment must be compared. The upfront costs of the L4 are the most budget-friendly, while the A100 variants are expensive. L4 costs Rs.2,50,000 in India, while the A100 costs Rs.7,00,000 and Rs.11,50,000 respectively for the 40 GB and 80 GB variants.
- Operating or rental costs can also be considered if opting for cloud GPU service providers like E2E Networks.
- Nvidia L4 costs Rs.50/hr, while the A100 costs Rs.170/hr and Rs.220/hr respectively for the 40 GB and 80 GB variants.
- It must be balanced between the performance and affordability based on the AI workload requirements. If budget permits, the A100 variants offer superior tensor core count and memory bandwidth, potentially leading to significant performance gains for deep learning applications.
Use Cases and Scalability
- The industry and application must be identified to deploy the GPU. Both L4 and A100 variants have applications across various sectors.
- As discussed in the earlier sections, L4 would suit better for the applications where multimedia, image and video processing would be used, while A100 would be more suitable for deep learning and large dataset applications.
- The growth trajectory for the AI applications must be forecasted. If expansion and workload complexity are expected, the A100 variants may offer better scalability.
By utilizing the provided cost data and following this cost-centric guide, you'll be equipped to make an informed decision that aligns with your budget and ensures the most cost-effective solution for your organization's AI workload needs. This data-driven approach will guide you toward a graphics processor that optimally balances performance and affordability for your AI projects.
Conclusion
In conclusion, the comparison between the L4 and A100 PCIe GPU highlights different capabilities and benefits that cater to diverse AI workloads and use cases.
Which Is Better?

The NVIDIA L4 serves as a cost-effective solution for entry-level AI tasks, Multimedia processing, and real-time inference. Meanwhile, the A100 variants stand as the go-to choice for advanced AI research, deep learning, simulations, and industries demanding superior processing power. Ultimately, the choice between the L4 and A100 PCIe Graphics Processor variants depends on your organization's unique needs and long-term AI objectives.
On E2E Cloud, you can utilize both L4 and A100 GPUs for a nominal price. Get started today by signing up. You may also explore the wide variety of other available GPUs on E2E Cloud.










