Get ₹2,000 free credits to test your AI workloads
Sign up and complete ID verification to unlock free credits. Deploy on NVIDIA H200, H100, and L40S GPUs—no commitment required.
Apache Spark with NVIDIA RAPIDS Framework: Quick Overview
In the age of big data, efficiently processing massive datasets isn’t just important—it’s a game-changer. Apache Spark has been a trusted powerhouse for large-scale data processing, but as datasets grow at lightning speed, even Spark can use a performance boost. Enter NVIDIA RAPIDS—a suite of GPU-accelerated libraries that takes Spark’s capabilities to the next level. In this blog, we’ll show you how you, as a data scientist or big data engineer, can leverage NVIDIA RAPIDS to supercharge your Spark workflows and achieve jaw-dropping speed-ups. Ready to unlock a new level of performance? Let’s get started!
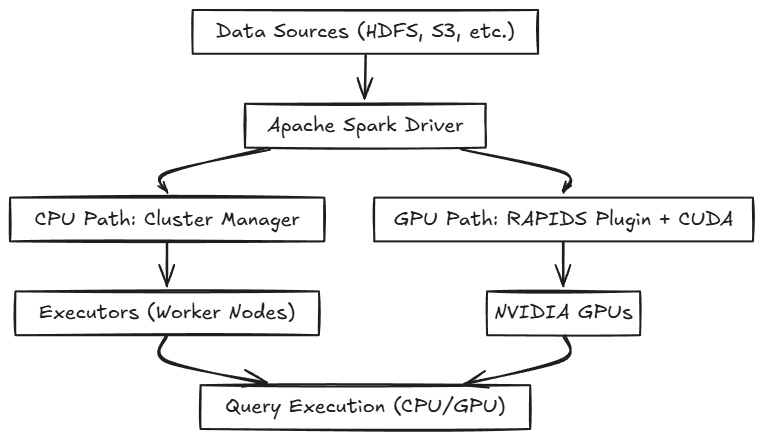
Apache Spark is your go-to open-source, distributed computing system, famous for its lightning-fast, in-memory processing capabilities that make tackling big data workloads a breeze. Whether you’re crunching massive datasets or running complex analytics, Spark delivers speed and simplicity like no other.
Now, meet NVIDIA RAPIDS—a suite of open-source libraries designed to revolutionize data science and analytics by running entire pipelines on GPUs. When you pair RAPIDS with Spark, you unlock a powerhouse combination. RAPIDS seamlessly offloads computationally heavy tasks to GPUs, drastically speeding up data processing and taking your workflows to a whole new level.
Let’s Code
Prerequisites and Environment Setup
Before we roll up our sleeves and jump into implementation, let’s take a moment to lay the groundwork. Here's what you'll need to set up the perfect environment for this project:
- Platform: For this demonstration, we’ll harness the power of E2E Cloud, a cutting-edge platform offering seamless access to high-performance GPUs. Whether you’re experimenting with machine learning models or crunching massive datasets, E2E Cloud delivers the muscle you need.
- GPU: E2E Cloud provides a versatile range of NVIDIA GPUs, from the Tesla T4 to the more advanced V100, A100, and even the trailblazing H100 and H200. For this demo, we’ll work with the reliable NVIDIA Tesla T4, perfectly suited for high-performance data processing.
- Operating System: E2E Cloud instances run on a Linux-based OS, typically Ubuntu, offering a robust and flexible environment for GPU computing. Even better, these instances come with CUDA pre-installed (usually CUDA 11.x or later). A quick terminal command—nvcc --version—will confirm the exact version on your instance..
- Python Version: E2E Cloud supports Python 3.x, giving you access to the latest libraries and features. Run python --version in your terminal to double-check the version.
- Apache Spark: We’ll use Apache Spark 3.5.3 for blazing-fast data processing and distributed computing capabilities.
- NVIDIA RAPIDS: To supercharge performance, we’ll install NVIDIA RAPIDS libraries that align with the CUDA version on your instance. RAPIDS unlocks GPU-accelerated processing, significantly cutting down runtime for heavy data tasks.
Pro Tip: While we’re using E2E Cloud for its powerful GPU capabilities, the concepts and code in this guide are flexible. You can adapt them to any Linux-based system equipped with NVIDIA GPUs, the right CUDA setup, and the necessary software dependencies.
Setting Up Apache Spark (Without RAPIDS)
To kick things off, we’ll configure Apache Spark and demonstrate data processing using CPU-only resources. This baseline setup will give us a clear understanding of the performance gains when we switch to GPU acceleration later on. Let’s get started.
Performance Without RAPIDS
In this section, we’ll rely on Spark’s default CPU processing capabilities to perform a series of operations: data loading, aggregation, filtering, and logistic regression. For each operation, we’ll measure the execution time to establish a baseline for performance. Let’s see how Spark handles the workload without the added boost of GPU acceleration
1. Data Loading (Without RAPIDS)
Our first step is to load the dataset into a Spark DataFrame, which provides a flexible and distributed way to manipulate large datasets. This process involves parsing the CSV file and loading it into memory, setting the stage for the transformations and analyses to come.
Key highlights of this step:
- Efficiently reads structured data from CSV files.
- Automatically infers schema and optimizes storage in memory for downstream operations.
By the end of this step, our dataset will be prepped and ready for action, sitting neatly in a distributed format for parallel processing.
Let’s dive in and put Spark to work! As we go through each operation, we’ll carefully record the execution times to identify potential bottlenecks and highlight areas where RAPIDS can make a difference.
Execution Time: Approximately 23.34 seconds.
2. Aggregation
Aggregation helps summarize datasets with key metrics like mean and sum. Here, we calculate these statistics for a column (var_0), a typical operation during exploratory data analysis.
Why It Matters: Aggregation provides insights into dataset distributions and helps in feature engineering.
What We Measure: The time it takes to compute these statistics.
3. Filtering
Filtering is essential for narrowing down datasets based on specific criteria. For this task, we’ll filter rows where the target column equals 1.
Use Case: Focus on rows of interest for targeted analyses or model training.
What We Measure: The time required to apply and execute the filtering operation.
4. Logistic Regression
Finally, we’ll train a logistic regression model to classify data based on the dataset’s features. This involves:
- Assembling the feature columns into a vector.
- Fitting a logistic regression model.
Key Steps: Feature assembly and model fitting.
What We Measure: The time it takes to complete these steps using Spark’s CPU-based processing.
Installing and Configuring RAPIDS
Let’s shift gears and supercharge our performance with RAPIDS. RAPIDS enables GPU-accelerated data processing by offloading Spark SQL operations to the GPU. This is a game-changer for handling larger datasets.
Installing RAPIDS
To get started, clone the RAPIDS repository and install the necessary dependencies:
Setting Up Spark with RAPIDS
Once installed, we configure Spark with NVIDIA’s RAPIDS plugin to enable GPU support. This setup optimizes Spark’s performance by allocating GPU resources.
Configuration Highlights:
- spark.rapids.memory.pinnedPool.size: Allocates GPU memory for efficient data transfers. Adjust based on your GPU’s capacity.
- spark.executor.resource.gpu.amount: Sets the number of GPUs available per executor.
- spark.task.resource.gpu.amount: Determines the fraction of GPU resources each task can use.
Note: The spark.rapids.memory.pinnedPool.size is set to 2G to allocate GPU memory for smooth and efficient data transfers between the CPU and GPU. Think of it as a dedicated highway for your data. Feel free to adjust this value based on your GPU's memory capacity to ensure optimal performance.
Performance with RAPIDS
Now, let’s unleash the power of GPU acceleration and see how enabling RAPIDS transforms the performance of the same dataset and operations. This is where the magic of parallel processing and optimized data structures comes to life.
1. Data Loading (With RAPIDS)
With RAPIDS enabled, the dataset is loaded into a Spark DataFrame using GPU acceleration. Here, the GPU takes charge, dramatically reducing the time required for this step.
- Execution Time: Approximately 12.77 seconds
- Impact: Nearly half the time compared to CPU processing, thanks to RAPIDS offloading the workload to the GPU.
The result? Faster data preparation, setting the stage for efficient downstream processing.
2. Aggregation, Filtering, and Logistic Regression
Next, we’ll repeat the same aggregation, filtering, and logistic regression steps as before, this time with RAPIDS enabled. The difference in execution time is striking:
- Aggregation: Summarizing data with GPU-optimized operations cuts execution time significantly.
- Filtering: Targeted queries become lightning-fast with GPU parallelism.
- Logistic Regression: Model training benefits from RAPIDS’ GPU-friendly algorithms.
Execution Time Comparison
The table below compares execution times for key operations, showing the dramatic improvements with RAPIDS:

The results speak for themselves—RAPIDS slashes execution times across the board, making GPU-accelerated data processing a game-changer.
Get ₹2,000 free credits to test your AI workloads
Sign up and complete ID verification to unlock free credits. Deploy on NVIDIA H200, H100, and L40S GPUs—no commitment required.
Why Is RAPIDS Faster?
The remarkable speedup with RAPIDS comes down to a combination of cutting-edge technology and smart optimizations:
1. GPU Acceleration
GPUs are built for parallelism, allowing thousands of computations to run simultaneously. This makes them ideal for data-heavy tasks like aggregation and model training.
2. Optimized Data Structures
RAPIDS uses GPU-optimized data structures that minimize overhead and improve communication between the CPU and GPU. The result? Faster data transfer and processing.
3. Columnar Processing
RAPIDS works with columnar data formats, which are inherently more efficient for analytical queries. By processing data in columns rather than rows, RAPIDS maximizes memory and computational efficiency.
RAPIDS doesn’t just accelerate data processing—it redefines it. With execution times slashed by nearly half in some cases, you’ll save time, reduce costs, and unlock new possibilities for tackling large datasets.
Real-World Applications
RAPIDS is a revolutionary suite of open-source libraries that harness GPU acceleration to supercharge data science and analytics workflows. From speeding up financial analysis to transforming genomics research, RAPIDS is redefining how industries handle massive datasets. Let’s explore some key domains where RAPIDS is making a massive impact:
1. Financial Analysis: Reacting at the Speed of the Market
In the high-stakes world of finance, speed equals success. RAPIDS allows analysts and traders to process vast amounts of market data in mere seconds, delivering insights faster than ever.
- With cuDF, a RAPIDS library offering a pandas-like API, data manipulation tasks are up to 150x faster.
- Impact: Traders can execute high-frequency strategies in real time, responding to market fluctuations with precision and speed that was previously unimaginable.
Imagine turning hours-long analysis into instant decision-making—that’s the magic of RAPIDS.
2. IoT Data Processing: Turbocharging Real-Time Streams
For industries reliant on IoT, RAPIDS is a game-changer for processing torrents of real-time sensor data. Picture millions of devices transmitting data every second—RAPIDS turns that deluge into actionable insights with ease.
- Combined with Apache Spark, RAPIDS minimizes latency for analyzing massive IoT datasets.
- Applications: Predictive maintenance, operational efficiency, and real-time monitoring in sectors like manufacturing and transportation.
When seconds matter, RAPIDS ensures that decisions happen at lightning speed.
- Genomics Research: Accelerating Breakthroughs
Handling colossal genetic datasets has always been a bottleneck in genomics research—until RAPIDS entered the scene. Its GPU-accelerated capabilities empower scientists to analyze complex genetic information in record time.
- Tools like cuGraph enable faster graph-based analyses, helping researchers uncover genetic variations with unprecedented efficiency.
- Impact: More iterations in less time, paving the way for breakthroughs in medicine and life sciences.
With RAPIDS, lifesaving innovations in genetics are just around the corner.
4. Recommendation Systems: Real-Time Personalization
In e-commerce, delivering personalized recommendations instantly is critical for user engagement and sales. RAPIDS supercharges recommendation systems by leveraging GPU acceleration to analyze behavior and preferences on the fly.
- Integrating RAPIDS with machine learning frameworks enables faster training and deployment of recommendation models.
- Result: Tailored suggestions that delight users and drive conversion rates.
Happier customers, increased loyalty, and soaring revenues—RAPIDS takes personalization to the next level.
Apache Spark + NVIDIA RAPIDS: The Ultimate Big Data Duo
When paired with Apache Spark, RAPIDS doesn’t just improve speed—it unlocks a new level of performance and scalability for massive datasets.
- Key Benefits: GPU-accelerated Spark workflows enable you to tackle larger datasets, cut computation times, and streamline complex data-intensive tasks.
- Who It’s For: From crunching numbers to real-time trend analysis, this duo is the go-to solution for redefining big data workflows.
With GPU-accelerated Spark and RAPIDS, the impossible becomes possible.
Why Choose E2E Cloud?
This guide has shown how RAPIDS can transform your Apache Spark workflows, but the real power lies in the cloud infrastructure you choose. That’s where E2E Cloud shines.
- Unbeatable GPU Performance: Access top-tier GPUs like H200, H100, and A100—ideal for state-of-the-art AI and big data projects.
- India’s Best Price-to-Performance Cloud: Whether you’re a developer, data scientist, or AI enthusiast, E2E Cloud delivers affordable, high-performance solutions tailored to your needs.
Get Started Today
Ready to supercharge your projects with cutting-edge GPU technology?
- Launch a cloud GPU node tailored to your project needs.
- Experience the future of big data processing with RAPIDS and Apache Spark.
E2E Cloud is your partner for bringing ambitious ideas to life, offering unmatched speed, efficiency, and scalability. Don’t wait—start your journey today and harness the power of GPUs to elevate your projects.


