AI development needs high-performance computing, fast model training, and efficient resource use. Traditional virtual machines (VMs) have been the go-to choice for running AI workloads, but they come with scalability issues, slow deployment, and inefficient GPU utilization. Each VM runs a full OS, leading to high overhead and wasted compute power.
As AI models grow in size and complexity, traditional VMs struggle to keep up. Developers face long setup times, dependency conflicts, and resource bottlenecks. Scaling AI applications requires more efficient, GPU-optimized solutions.
This is where TIR Containerized VMs come in. They combine the isolation of VMs with the speed and flexibility of containers. Built for AI workloads, they offer pre-configured environments, faster GPU access, and scalable pipelines.
In this blog, you will learn how TIR Containerized VMs compare to traditional VMs, their advantages for AI/ML workloads, and why they are the future of AI infrastructure.
What are Traditional VMs?
Traditional virtual machines (VMs) have been widely used for AI workloads. They provide isolated environments but lack the efficiency required for large-scale AI training and inference.
How Traditional VMs Work
A traditional VM runs on a hypervisor, which manages multiple virtualized OS environments on a physical server. Each VM operates independently, with its own OS, libraries, and dependencies.
While VMs work well for general computing, they are not optimized for AI. AI workloads require high-performance GPUs, low-latency data access, and efficient resource allocation, which traditional VMs struggle to provide.
Challenges with Traditional VMs for AI/ML Workloads
Traditional VMs introduce several challenges when handling AI/ML applications:
- Performance Overhead – Running a full OS for each VM increases resource consumption and slows AI workloads.
- Scalability Issues – Scaling AI models requires rapid provisioning, but VMs take time to boot and configure.
- Dependency Conflicts – AI frameworks need specific drivers, libraries, and dependencies, which are hard to manage in VM environments.
- Slow Deployment & Updates – VM-based setups require extensive configuration, leading to long provisioning times and delays in updating AI models.
What are Containerized VMs?
Containerized VMs are a hybrid solution that merges VM isolation with container-like efficiency. Unlike traditional VMs, which require a full OS for each instance, containerized VMs are lightweight and optimized for AI workloads.
These VMs come pre-configured with AI/ML frameworks like PyTorch and TensorFlow, reducing setup time. They provide direct access to GPUs, ensuring better performance for training and inference. Unlike standard containers, which rely on a shared OS, containerized VMs maintain complete isolation, improving security and stability.
Another key advantage is resource optimization. Traditional VMs often lead to resource fragmentation, but containerized VMs dynamically allocate CPU, GPU, and memory based on workload demands. Containerized VMs also simplify scaling AI applications. They allow users to quickly provision and update models without downtime.
Developers can deploy models in controlled environments, reducing dependency conflicts and ensuring consistent performance across multiple instances. With pre-installed AI libraries, GPU acceleration, and flexible scaling, containerized VMs offer a modern alternative to traditional virtual machines, making AI development faster and more efficient.
What is TIR? - The AI-Optimized Containerized VM Platform

TIR offers Nodes, which list the available virtual machines (VMs) where containers run, Spot Instances for cost-effective temporary workloads, and a Training Cluster to manage containerized VMs for distributed AI/ML training.
Unlike traditional VMs, which require complex setup and manual configurations, TIR simplifies AI infrastructure by combining virtualization with containerization for better performance and scalability.
How Does TIR Work?

TIR runs on NVIDIA GPU-powered containerized VMs, giving AI developers a fast and efficient way to build and scale models. Unlike traditional VMs, which require manual setup, TIR provides pre-installed AI/ML stacks like PyTorch, TensorFlow, and Hugging Face, reducing configuration time.
TIR's scalable AI pipelines automate training, inference, and deployment. Developers can create serverless, asynchronous jobs using Docker-based pipelines, making it easy to run complex workloads without managing infrastructure. The platform also supports scheduled runs, allowing users to execute tasks at fixed intervals.
TIR ensures better GPU utilization by dynamically allocating resources based on workload needs. This prevents resource waste and improves performance. With built-in model repositories and vector databases, users can store, version, and retrieve models efficiently.
TIR integrates with S3, Google Cloud Storage, Blob, and MinIO, providing access to datasets. It also supports no-code AI agent building, making AI development accessible to teams without deep technical expertise.
Key Benefits of TIR Over Traditional VMs
TIR eliminates the inefficiencies of traditional VMs by optimizing AI development workflows. It speeds up training, enhances resource management, and simplifies deployment.
- Faster AI/ML development – Pre-installed frameworks remove the need for manual setup, reducing time spent on configuring environments.
- Easy model deployment – AI models can be deployed directly inside containers, eliminating compatibility issues across different infrastructures.
- Optimized GPU performance – TIR dynamically adjusts GPU allocation based on workload requirements, ensuring better cost efficiency and faster inference speeds.
- Automated AI pipelines – Developers can schedule training jobs, automate model fine-tuning, and run asynchronous AI workflows without manual intervention.
- Integrated model repository – Version control, model sharing, and retrieval become seamless, enabling better model lifecycle management.
- No-code AI agent builder – Businesses can create chatbots and AI-powered applications quickly, improving productivity without requiring deep technical expertise.
- Scalable storage solutions – Datasets, model weights, and logs can be stored in cloud-compatible storage buckets, ensuring fast access and efficient data management.
TIR Platform Pricing: Transparent and Cost-Effective AI Compute
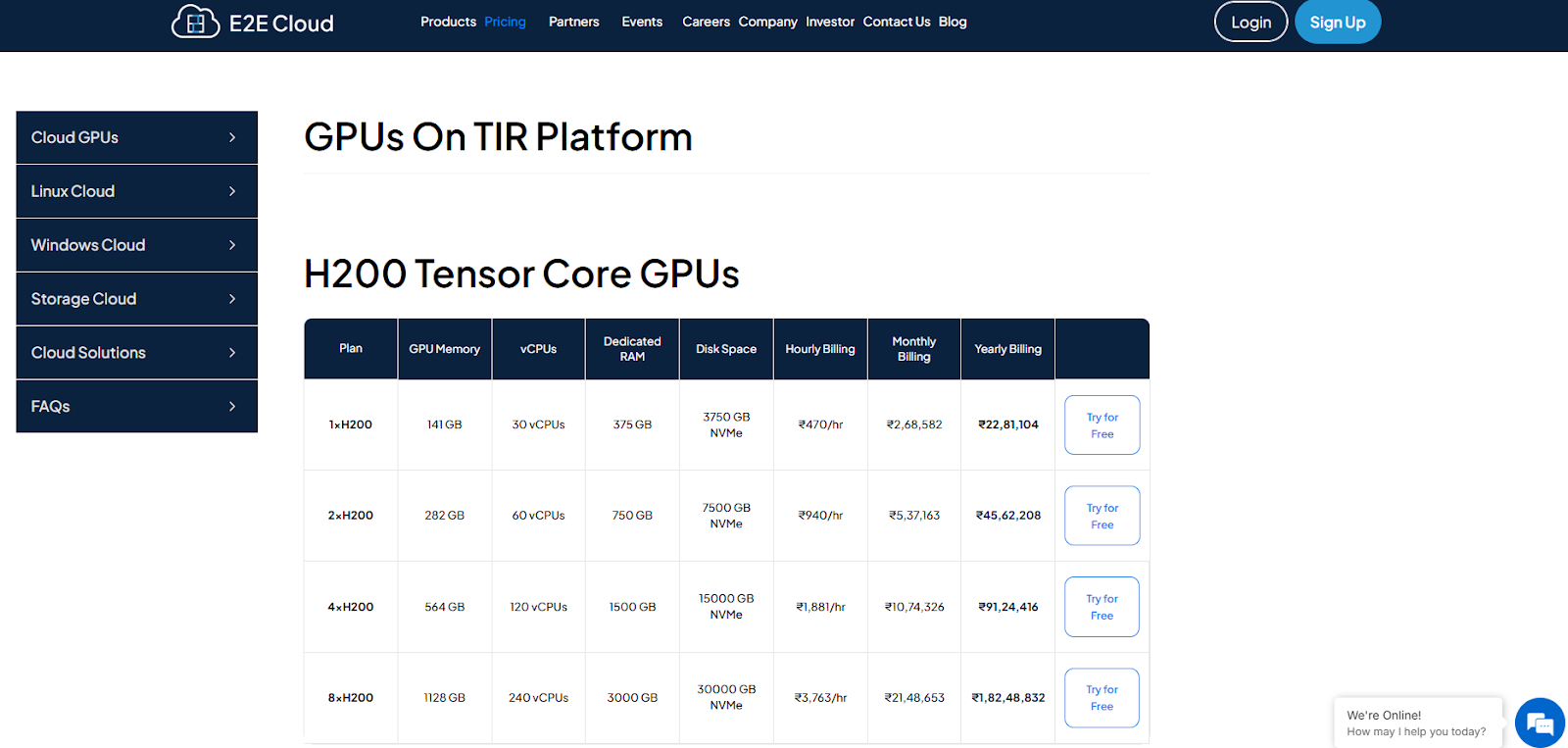
TIR provides AI developers with a cost-effective and transparent pricing model. The platform eliminates hidden fees, offering clear and predictable rates for GPU-powered AI workloads. Users can select from flexible pricing options based on their specific requirements.
- Predictable Pricing – No surprise charges. The pricing structure remains clear and upfront.
- Flexible Plans – Choose between pay-as-you-go for flexibility or long-term commitment for savings.
- Optimized Resource Billing – Pay only for actual GPU and compute usage without extra overhead.
- Scalable Costs – Scale resources up or down based on workload demands.
TIR ensures affordable AI infrastructure with efficient pricing models. Visit the E2E Networks Pricing Page for details.
Traditional VMs vs. TIR Containerized VMs: Feature Comparison Table
Traditional VMs and TIR’s containerized VMs differ significantly in how they manage AI workloads. The table below compares key technical features, highlighting the advantages of TIR’s AI-optimized infrastructure over conventional VM setups.
| Feature | Traditional VMs | TIR Containerized VMs |
|---|---|---|
| Setup Time | Slow provisioning, requiring OS installation and AI framework setup. | Instant AI-ready environments with pre-installed AI/ML stacks. |
| Resource Efficiency | High OS overhead due to separate kernels and drivers for each VM. | Optimized GPU and compute usage with minimal OS duplication. |
| Scalability | Limited scaling, requiring complex orchestration for AI workloads. | On-demand, dynamic scaling of AI models and workloads. |
| Deployment Speed | Manual, time-consuming process involving configuration and dependencies. | Automated deployment with containerized AI models. |
| Dependency Management | Frequent conflicts due to varied AI/ML library versions. | Pre-configured environments with optimized dependencies. |
| Performance Overhead | High due to full OS instances and inefficient GPU memory allocation. | Minimal overhead with lightweight containers sharing the host OS kernel. |
| AI/ML Framework Support | Requires manual installation of AI libraries (TensorFlow, PyTorch, etc.). | Built-in support for AI/ML frameworks with ready-to-use environments. |
| GPU Utilization | Not optimized, leading to inefficient AI model execution. | Direct access to NVIDIA GPUs with optimized memory allocation. |
| Security | Full isolation but with high resource consumption. | Lightweight, container-based security with strict access controls. |
| Cost Efficiency | Higher due to separate OS instances and unused resource allocation. | Lower costs with optimized resource sharing and efficient GPU usage. |
Getting Started with TIR
TIR Containerized VMs offer a faster, more efficient, and AI-ready alternative to traditional VMs. They remove performance bottlenecks, optimize GPU usage, and simplify AI/ML development with pre-configured environments. Developers can train, fine-tune, and deploy models without dealing with complex setup and dependency issues.
With scalable AI pipelines, easy deployment, and cost-effective pricing, TIR is the ideal choice for modern AI workloads. It provides instant access to high-performance NVIDIA GPUs and built-in AI frameworks, making development faster and more efficient.
Start building AI models with TIR on E2E Networks today. Try TIR now and experience AI computing without limitations.