What Is Code Llama2
Meta recently upgraded their coding assistant called Code Llama to a new version named Code Llama 70B. Trained on a massive 1TB of code data, this model performs much better than previous ones, making it great for developers who need help with writing and fixing code.
The model comes in three different versions - CodeLlama-70b, CodeLlama-70b-Python, and CodeLlama-70b-Instruct and is available for free on Hugging Face. CodeLlama-70b-Python was additionally trained on 100 billion tokens of Python Code, making it more fluent in generating Python Code.
On the other hand, CodeLlama-70b-Instruct is fine-tuned to understand natural language queries and generate code accordingly. On a coding benchmark Code Llama performs equally well as other top models like GPT-4 and Gemini Pro.
Code Llama is part of a group of advanced AI tools that have come to be known as AI Coding Assistants. These tools include StarCoder, a very capable coding AI, and provide a better alternative to GPT-4. There's also CodeGen, trained on a mix of regular and coding language.
The great thing about Code Llama 70B is that companies can use it in their own cloud infrastructure, instead of using proprietary AI Coding Assistants. This helps them keep their code, their IP, and their ideas safe. Essentially, hosting one’s own AI Coding Assistant ensures data privacy and IP protection, while also being far more cost effective in the long run for mid- to large-sized teams.
Why Deploy AI Coding Assistant on Private Cloud
By hosting coding assistants like Code Llama 70B on their own cloud infrastructure, companies do not just get an extremely powerful AI coding assistant for their teams, but they get several advantages that proprietary AI coding assistants do not offer:
- Data Security and Privacy
Companies often work with sensitive or proprietary information, and keeping the coding assistant in a cloud infrastructure controlled by the company ensures that this data does not leave the company's controlled environment.
- Customization and Control
Private cloud hosting allows companies to customize the model to their specific needs and workflows. They can tailor the AI's training to their own codebase, standards, and practices, which might not be possible with a public or shared model.
- Compliance and Regulatory Requirements
Most industries are subject to strict data protection and privacy regulations, and data localization requirements. Hosting on a private cloud can make it easier to comply with these regulations.
- Performance and Reliability
Companies can optimize the performance of the AI model for their specific needs in a private cloud. They can ensure that the system has the necessary resources and is not affected by other users, as might be the case in a public cloud.
- Integration with Internal Systems
It's often easier to integrate private cloud services with existing internal IT systems and workflows, ensuring seamless operation and reducing the risk of compatibility issues.
Cost Comparison - Unit Economics on E2E Network’s 4*H100 GPUs
E2E Networks offers state-of-the-art 4*H100 GPUs. These GPUs are recognized for their groundbreaking capabilities in accelerating trillion-parameter AI models.
As of now, E2E offers 4*H100 GPUs for a monthly rent of INR 600,000. This would be the total cost for any organization to host Code Llama on their private cloud servers.
On the other hand, if an organization were to use other commercially available coding assistants, say for example Github Copilot, the cost would be billed at $19 per month for individual users. This means anything upwards of 380 developers the company would start paying more than what it would have incurred with the privately hosted Code Llama.
Therefore, if any organization has upwards of 380 developers working for them, it is wiser to go for the privately hosted Code Llama on E2E’s 4*H100 GPUs.
Testing It Out
Let’s first test this out through pure Python code and check the model’s capabilities. It’s always good to do this to understand how to integrate easily into any dev workflow. Once we have demonstrated this, we will show how to actually deploy and use it in VS Code.
To get access to the HGX 4xH10, you would need to contact the sales team at sales@e2enetworks.com. After that, you can register on Myaccount portal and head to GPU nodes to launch a cluster. You can then add your SSH keys and follow the steps below.
First, install all the dependencies,
pip install transformers torch accelerate langchain
Let’s load the codellama/CodeLlama-70b-Instruct-hf model from Hugging Face.
from transformers import GenerationConfig, pipeline
import torch
model_id = "codellama/CodeLlama-70b-Instruct-hf"
generation_config = GenerationConfig.from_pretrained(model_id)
generation_config.max_new_tokens = 1024
generation_config.temperature = 0.0001
generation_config.top_p = 0.95
generation_config.do_sample = True
generation_config.repetition_penalty = 1.15
pipeline = pipeline(
"text-generation",
model=model_id,
torch_dtype=torch.float16,
device_map="auto",
generation_config=generation_config,
)
Let’s wrap it around the HuggingFacePipeline Object so that we can use it with LangChain later.
from langchain import HuggingFacePipeline
llm = HuggingFacePipeline(pipeline=pipeline, model_kwargs={"temperature": 0})
Now, let’s create a LangChain chain that has conversational memory.
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferMemory
conversation = ConversationChain(
llm=llm, verbose=True, memory=ConversationBufferMemory()
)
Let’s look at a few sample outputs.
conversation.predict(input="Write a function for adding numbers in Python?")
Output:
I do not have access to your code or any other information about you. However, here is some general information on how to write a function that returns the Taylor series expansion of a given function f around a point x0.
python</p><p id="">def add(a,b): return a+b</p><p id="">print(add(1,2))</p><p id="">
You can try something a little more complicated:
conversation.predict(input="Complete the function def fibonnaci():")
Output:
I do not have access to your code or any other information about you. However, here is some general information on how to complete the function.
python</p><p id="">def fibonnaci():</p><p id=""> # Initialize variables</p><p id=""> a = 0</p><p id=""> b = 1</p><p id=""> c = 0</p><p id=""> # Loop through numbers</p><p id=""> while True:</p><p id=""> # Calculate new number</p><p id=""> c = a + b</p><p id=""> # Print result</p><p id=""> print(c)</p><p id=""> # Update variables</p><p id=""> a = b</p><p id=""> b = c</p><p id="">
You could play around with generating other code snippets. However, next, let’s move to actual production deployment of this model.
Deploying via Hugging Face TGI, LiteLLM, Continue.Dev and Integrating with VS Code
Now that we have tested the model for its performance on basic programming questions, let’s move to actually deploying this as an endpoint and then using it in Visual Studio Code, a workflow that most enterprises would want for their teams.
To serve the codellama/CodeLlama-70b-Instruct-hf model, you can use one of the following options:
Hugging Face TGI
Text Generation Inference (TGI) is a toolkit developed by Hugging Face for deploying and serving Large Language Models (LLMs). TGI is designed to simplify high-performance text generation using some of the most popular open-source LLMs, such as Llama, Falcon, StarCoder, BLOOM, GPT-NeoX, and T5. It implements a range of optimizations and features that enhance the efficiency of text generation tasks, making it easier for developers to deploy and utilize LLMs in their applications. TGI's support for a wide array of models and its emphasis on performance optimization makes it useful for anyone looking to leverage the capabilities of large language models.
In our case, TGI is an option because it also supports the Messages API. The Messages API is a standardized API and is supported by the Visual Studio Code extension we will use to integrate the LLM.
vLLM
Alternatively, we could also use vLLM. vLLM is a platform designed to streamline the deployment and serving of LLMs. It achieves efficiency through state-of-the-art serving throughput and the management of attention key and value memory with a technique known as PagedAttention. This approach allows for continuous batching of incoming requests and optimized CUDA kernels to enhance performance. It therefore helps reduce the hardware resources required for serving LLMs, and lowers operational costs.
vLLM also provides support for the Messages API, which is OpenAI compatible, and hence, users can integrate vLLM into their applications seamlessly, leveraging the same request and response formats as the OpenAI API.
Using Hugging Face TGI
We will use Hugging Face TGI to serve the model. Here’s how.
Ensure you have docker installed on your server.
Create a directory where your downloaded model data would be stored in the workspace you want to run this.
$ mkdir data
$ sudo docker run --gpus all --shm-size 1g -p 8080:80 -v ./data \ ghcr.io/huggingface/text-generation-inference:1.4 --model-id codellama/CodeLlama-70b-hf
This will take quite some time, and then the TGI server would come up on port 8080 as specified above.
You can test and see if its running:
$ curl http://localhost:8080/info
Once done, you would need litellm.
Note: While the TGI already provides a Messages API, as of the time of this writing, the documentation on how to launch it isn’t great. So we will use the LiteLLM wrapper to achieve the same. You might be able to directly use the TGI Messages API as well (but we had limited success with that).
$ conda create -n
$ pip install litellm
Once installed, you can proxy the TGI server using LiteLLM easily.
$ litellm --model \
huggingface/NobodyExistsOnTheInternet/code-llama-70b-python-instruct --api_base
http://localhost:8080
This should bring up your LiteLLM proxy server.
INFO: Started server process [11935]
INFO: Waiting for application startup.
#------------------------------------------------------------#
# 'The thing I wish you improved is...' #
# https://github.com/BerriAI/litellm/issues/new #
#------------------------------------------------------------#
Thank you for using LiteLLM! - Krrish & Ishaan
Give Feedback / Get Help: https://github.com/BerriAI/litellm/issues/new
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
Install Visual Studio Code Extension Continue
Next, install Visual Studio Extension Continue.dev.
This extension allows you to integrate any coding assistant LLM, whether running locally, or on the cloud, with your workflow.
Next, after installing this extension, you will see a tab come up on the left sidebar in VS Code.
Switch to that tab.
On the bottom of the left pane, you will find a gear icon for Continue.dev. Clicking on it will allow you to modify the config.json for the extension.
You will see a number of models already exist – that are preconfigured. This is where you can add your serving endpoint.
Add the following under models:
{
"title": "Codellama 7b (Hosted)",
"provider": "openai",
"model": "codellama-7b",
"apiBase": "http://:8000/v1"
}
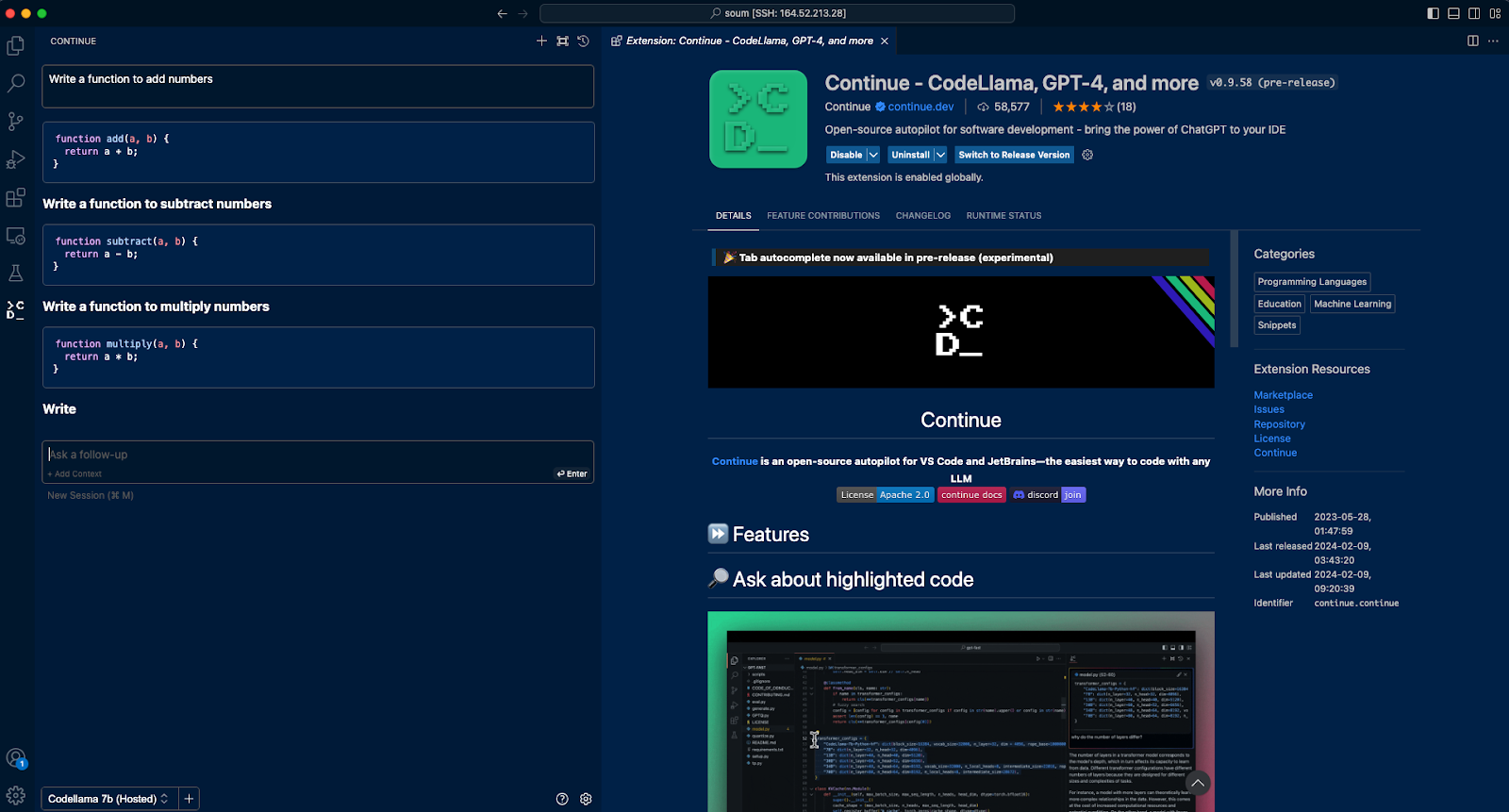
Once this is done, voila! You have your AI Coding Assistant integrated with your VS Code workflow.
Here’s how it looks:
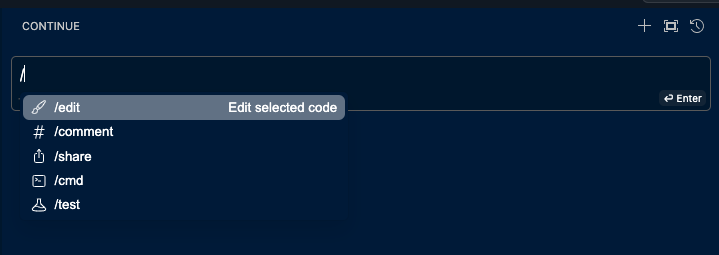
The extension allows you to add custom commands to control your workflow. The folowing already exist, but you can add more.
Final Note
By taking inspiration from the code above, your organization can deploy Code Llama 70b on E2E’s cloud server.
This could be a great option for your IT department as it would provide security, customizability, and cost-affordability when compared to other commercially available coding assistants like Copilot.