Introduction
Llama 3.2-11B is a state-of-the-art multimodal large language model developed by Meta, featuring 11 billion parameters. This model is part of the Llama 3.2 collection, which includes both vision and text capabilities, marking a significant advancement in the integration of visual and linguistic understanding. Unlike its predecessors, Llama 3.2-11B is designed to handle complex tasks that involve both text and images, such as image captioning, visual question answering, and document understanding.
One of the standout features of Llama 3.2-11B is its ability to process high-resolution images alongside text, enabling it to perform tasks that require reasoning over visual data. The model employs a unique architecture that integrates an image encoder into the language model through a series of cross-attention layers. This allows it to bridge the gap between visual inputs and language outputs effectively. Also, it supports a context length of up to 128,000 tokens, significantly enhancing its capacity for handling extensive data inputs.
The applications of Llama 3.2-11B are diverse. For example, in education, it can be used for interactive learning tools that require image-based content generation or analysis. In business contexts, it can assist in extracting information from graphs or charts to provide insights based on visual data. Alternatively, it can enhance customer service through AI-driven solutions that require both visual comprehension and conversational abilities.
Our Aim in This Tutorial
In this guide, we'll walk you through the process of building a Retrieval-Augmented Generation (RAG) system using the Llama 3.2-11B model, enhanced with vision capabilities. The goal is to process images, extract text from them, and store this data in a high-performance vector database like Qdrant. This setup enables efficient retrieval of information when users ask questions.
The process starts by taking an image URL and using the Llama 3.2-11B model to extract text from the image. The extracted text is then stored in Qdrant, allowing for quick lookups and retrievals based on queries. Building on this, we'll create a Question and Answer (QnA) system that retrieves relevant information from the stored data and generates responses using the Llama model.
This project demonstrates how Llama 3.2-11B can seamlessly integrate vision tasks with text-based retrieval, creating a powerful system capable of handling both image processing and dynamic QnA functionality.
Let’s Code
The Installations
This command installs libraries for NLP, embeddings, vector search, and building machine learning interfaces.
!pip install -q sentence-transformers transformers qdrant-client groq gradio
Imports
Some required Imports:
from PIL import Image
import io
import torch
from transformers import LlamaTokenizer, LlamaForCausalLM
from sentence_transformers import SentenceTransformer
from qdrant_client import QdrantClient
from qdrant_client.http.models import VectorParams, Distance
import os
import requests
import torch
from PIL import Image
from transformers import MllamaForConditionalGeneration, AutoProcessor
from groq import Groq
import gradio as gr
Hugging Face Login
Login to Hugging Face using your access token.
from huggingface_hub import notebook_login
notebook_login()
Setup
In this code block, we’re setting up a sophisticated natural language processing pipeline using several powerful tools:
- LLaMA 3.2 11B Model: We load the "Llama-3.2-11B-Vision-Instruct" model, a large language model designed for both text and vision tasks. It’s configured with bfloat16 precision to balance memory efficiency and computational power. The device_map="auto" setting automatically assigns the model to the most appropriate hardware (like GPU or CPU), streamlining deployment.
- Processor: The model's processor is loaded using the AutoProcessor class. This ensures inputs are formatted correctly for the model, whether it’s images, text, or a combination.
- Groq Client: Here, we’re initializing the Groq client, which connects to Groq’s hardware accelerator. This is useful for speeding up inference, leveraging Groq’s AI hardware, and requires an API key to connect.
- Sentence Embedder: We’re using the SentenceTransformer library with the "all-MiniLM-L6-v2" model to generate sentence embeddings. This model is small yet effective, making it ideal for creating vector representations of text for tasks like semantic search or clustering.
- Qdrant Vector Database: Finally, we connect to a Qdrant instance, a vector database optimized for searching and storing embeddings. It’s running locally on port 6333 and will store our text embeddings, allowing us to efficiently search or compare them.
This setup enables robust natural language and vision tasks, high-performance inference, and fast vector-based searches—all in one workflow.
model_id = "meta-llama/Llama-3.2-11B-Vision-Instruct"
model = MllamaForConditionalGeneration.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
)
processor = AutoProcessor.from_pretrained(model_id)
client = Groq(
api_key="",
)
embedder = SentenceTransformer('all-MiniLM-L6-v2')
qdrant = QdrantClient("localhost", port=6333)
Qdrant Vector DB
The function create_qdrant_collection() sets up a new collection in the Qdrant vector database, specifically named "pdf_collection". This collection is configured to store vector embeddings with a size of 384 dimensions. The collection uses cosine similarity as the distance metric, which is ideal for comparing the similarity between vectors, commonly used in tasks like semantic search, recommendation systems, or clustering. The qdrant.create_collection method handles the creation and configuration of the collection.
def create_qdrant_collection():
qdrant.create_collection(
collection_name="pdf_collection",
vectors_config=VectorParams(size=384, distance=Distance.COSINE),
)
Text Extraction from Image (OCR)
The function convert_url_to_text(url) takes an image from a given URL, processes it, and extracts text from the image using a model.
Here's a breakdown:
- Image Retrieval: The function fetches an image from a URL and opens it using PIL's Image.open with a stream request.
- Message Setup: It prepares a message instructing the model to "Extract text from the image" and formats this input using a processor.
- Processing Input: The image and text prompt are processed and tokenized to be compatible with the model.
- Text Generation: The model generates a response based on the processed input (the image and the prompt), and it is configured to allow up to 28,000 tokens.
- Decoding: The output is decoded into readable text and returned as the extracted text from the image.
This function is designed to convert an image from a URL into text using an AI model that processes both images and natural language instructions.
def convert_url_to_text(url):
image = Image.open(requests.get(url, stream=True).raw)
#image = Image.open(local_path)
messages = [
{"role": "user", "content": [
{"type": "image"},
{"type": "text", "text": "Extrcat text from the image, Respond with only extracted text"}
]}
]
input_text = processor.apply_chat_template(messages, add_generation_prompt=True)
inputs = processor(image, input_text, return_tensors="pt").to(model.device)
output = model.generate(**inputs, max_new_tokens=28000)
return processor.decode(output[0])
Index Text
The function index_texts(texts: str, max_token=100) is designed to encode and store text data into a Qdrant vector database for future search or retrieval.
Here's a summary of how it works:
- Loop through Texts: The function iterates over each text in the provided texts list (or other iterable).
- Generate Embeddings: For each text, it uses the embedder.encode() function to generate a vector (embedding) representing the text in a high-dimensional space. The vector is then converted to a list format.
- Prepare Payload: It creates a payload (metadata) for each text, containing the page_num (which is the index of the text) and the actual text.
- Upsert into Qdrant: The function inserts or updates (upsert) the text embedding into the "pdf_collection" in the Qdrant vector database. Each point is stored with an ID, its embedding, and the associated payload metadata (such as page number and text).
This function essentially indexes a series of text documents by generating embeddings and storing them in Qdrant for later vector-based search or retrieval.
def index_texts(texts: str, max_token = 100):
for i, text in enumerate(texts):
embedding = embedder.encode(text).tolist()
payload = {"page_num": i, "text": text}
qdrant.upsert(
collection_name="pdf_collection",
points=[{
"id": i,
"vector": embedding,
"payload": payload
}]
)
Relevant Document Extraction
The function retrieve_relevant_text(query) is designed to search for and retrieve relevant text snippets from a Qdrant vector database based on a provided query. Here’s a brief overview of how it works:
- Query Embedding: It first generates an embedding for the input query using the embedder.encode() method, converting the resulting vector to a list format.
- Search in Qdrant: The function then performs a search in the "pdf_collection" of the Qdrant database using the query embedding. It retrieves a maximum of 3 relevant results based on similarity.
- Extract and Return Text: Finally, it compiles a list of the text payloads from the results and returns them, providing the user with the most relevant text snippets related to their query.
This function facilitates efficient retrieval of information from indexed texts by leveraging vector similarity search.
# Retrieve relevant text from Qdrant
def retrieve_relevant_text(query):
query_embedding = embedder.encode(query).tolist()
results = qdrant.search(
collection_name="pdf_collection",
query_vector=query_embedding,
limit=3
)
return [result.payload['text'] for result in results]
Generating Answers
The function generate_answer(context, query) is designed to generate a response to a user's query based on a given context using the Llama 3.2 model. Here’s a concise overview of its operation:
- Prepare Messages: The function constructs a message format suitable for the chat model. It includes a system message that establishes the role of the agent as an answer generator, incorporating the provided context. It also includes a user message that specifies the user's query and instructs the model to answer it using the context.
- Chat Completion: It sends these messages to the Llama model via the Groq Client to generate a chat completion, which is the model's response to the query.
- Return Answer: Finally, the function retrieves and returns the generated answer from the model’s response, specifically the content of the first choice.
This function allows for dynamic question answering based on the context provided, leveraging the capabilities of the Llama 3.2 model.
# Generate an answer using LLaMA 3.2 11B
def generate_answer(context, query):
chat_completion = client.chat.completions.create(
messages=[
{
"role": "system",
"content": "You are an answer generation angent, with context {context}",
"role": "user",
"content": f"your query was {query}, answer this query from the given context {context}",
}
],
model="llama-3.2-1b-preview",
)
return chat_completion.choices[0].message.content
Main Entry Point
This block of code serves as the main entry point for executing a series of tasks related to processing an image, indexing text, and generating a response to a query. Here’s a breakdown of its functionality:
- URL and Query Setup: It defines a URL pointing to an image and a query asking for information about that image.
- Text Extraction: The function convert_url_to_text(url) is called to extract text from the specified image URL. The extracted text is stored in the data variable.
- Create Qdrant Collection: The create_qdrant_collection() function is called to create a new collection in Qdrant where the text data will be indexed.
- Index Texts: The index_texts(context) function is used to index the extracted text into the Qdrant collection, allowing for future retrieval based on embeddings. (Note: There seems to be a missing definition of context before this call; it should likely reference the text extracted from the image.)
- Retrieve Relevant Text: The retrieve_relevant_text(query) function retrieves text relevant to the provided query from the Qdrant collection. The results are stored in the context variable.
- Generate Answer: Finally, the generate_answer(context, query) function is called to generate a response based on the retrieved context and the user's query.
This code effectively combines image processing, text indexing, and natural language understanding to answer user queries about the content of an image.
if __name__=="__main__":
url = "https://resumegenius.com/wp-content/uploads/2019/08/Computer-Science-Cover-Letter-Example-Template.png"
query = "What is this information about"
data = convert_url_to_text(url)
create_qdrant_collection()
payload = index_texts(context)
context = retrieve_relevant_text(query)
response = generate_answer(context, query)
Gradio Interface
This code sets up a Gradio web application that processes an image URL and a user query.
- Process Function: The process(url, query) function:some text
- Extracts text from the image at the specified URL.
- Creates a Qdrant collection.
- Indexes the extracted text.
- Retrieves relevant text based on the query.
- Generates and returns a response.
- Gradio Interface: It defines a user interface with two text inputs for the URL and query, and outputs the generated response.
- Launch: Finally, it launches the app, allowing users to interact with the model through a web interface.
This setup enables users to get relevant answers based on the content of an image simply by providing a URL and a question.
# Main function to handle the Gradio inputs
def process(url, query):
context = convert_url_to_text(url)
create_qdrant_collection()
payload = index_texts(data)
context = retrieve_relevant_text(query)
response = generate_answer(context, query)
return response
# Define the Gradio interface
interface = gr.Interface(
fn=process,
inputs=[gr.Textbox(label="URL"), gr.Textbox(label="Query")],
outputs="text",
title="URL to Text and Query Processing",
description="Provide a URL and a query to get a relevant response."
)
# Launch the Gradio app
interface.launch(share = True)
Outputs

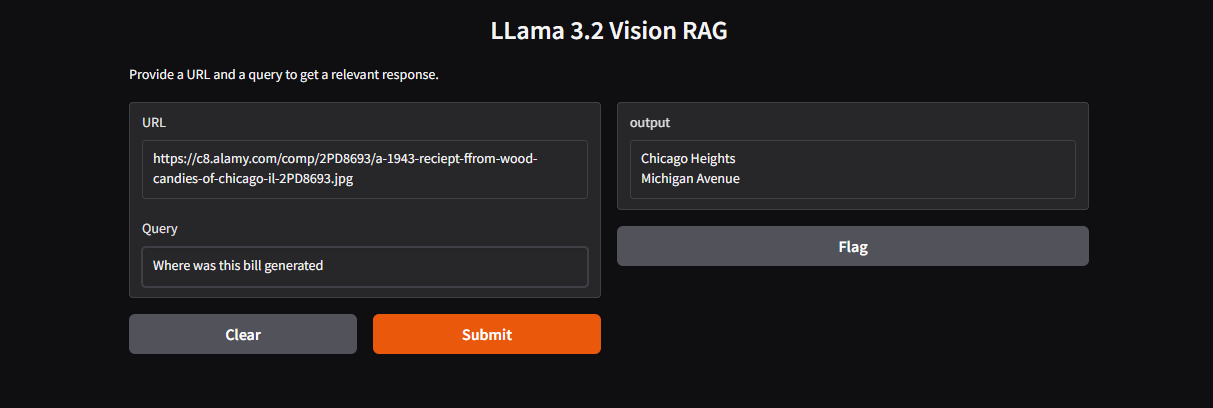
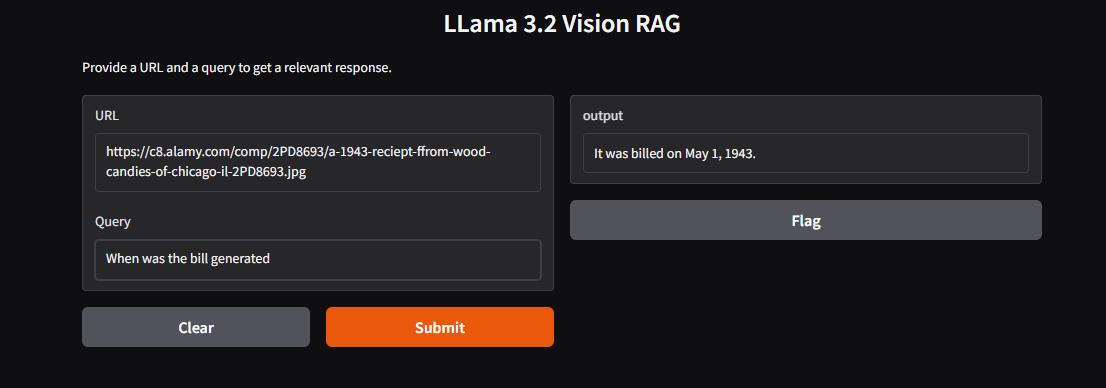
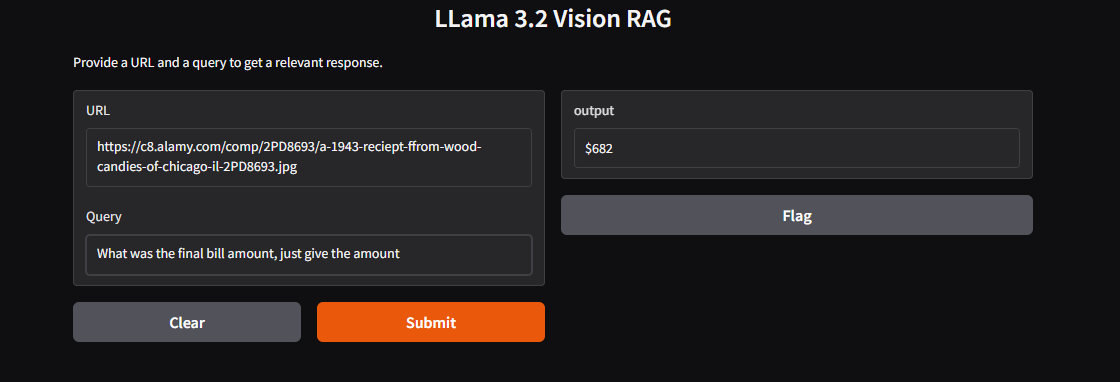
Conclusion
Today, we delved into the fascinating world of object detection and demonstrated how powerful it can be in various applications.
To get started with Flux.1-dev, sign up to E2E Cloud today, and launch a cloud GPU node, or head to TIR. E2E Cloud offers the most price-performant cloud GPUs in the Indian market, and enables developers to use advanced GPUs like H200, H100, A100 for application development.









