In this article we are going to learn about Deep Generative Models, an interesting field of AI. The scope of the article is as follows:
- What are Generative Models?
- Why Generative Models?
- What are Generative Models Zoo?
- What are latent variables?
- What are Autoencoders?
- What are Variational Autoencoders(VAEs)?
- What are Generative Adversarial Networks(GANs) and their recent advances ?
- Generative Modeling on E2E Cloud
What are Generative Models?
Generative Models learn to model the true (unknown) underlying data distribution from samples. These models are used to create new data points similar to original data distribution. Historically generative modeling is considered as a subfield of un-supervised learning but conditional generative modeling makes the boundary between supervised and unsupervised blurry. These models can be used for any kind of data, for example - text,audio,image,biological data etc.
Why Generative Models?
Can you guess which of the following images is fake?

The answer is both! It's cool to see such photorealistic images created by deep learning that have diverse practical applications like:-
- Density estimation and outlier detection
- Data compression
- Mapping from one domain to another
- Language translation, text-to-speech
- Planning in model-based reinforcement learning
- Representation learning
- Understanding the data
What are Generative Models Zoo?
Explicit likelihood models:-
● Maximum likelihood
○ PPCA, Factor Analysis, Mixture models
○ PixelCNN/PixelRNN
○ Wavenet
○ Autoregressive language models
● Approximate maximum likelihood
○ Boltzmann machines
○ Variational autoencoders
Implicit Models:-
● Generative adversarial networks
● Moment matching networks
Our focus in this post will be on latent variable models i.e. Autoencoders and Variational
Autoencoders (VAEs) and Generative Adversarial Networks.
What are latent variables?
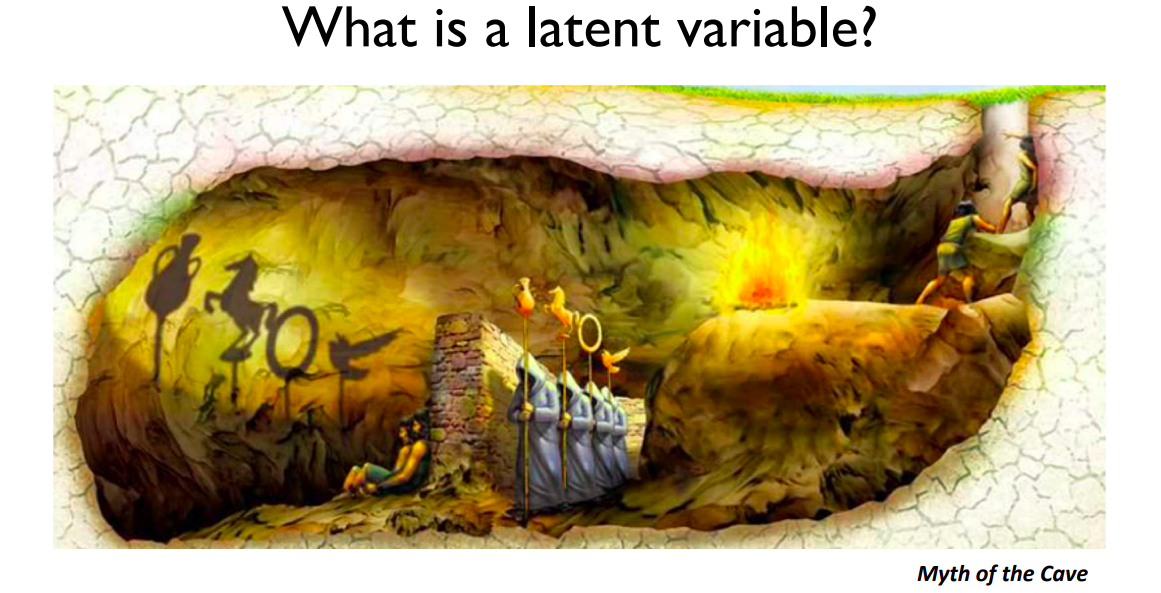
One of the best ways to explain the latent variables is by understanding the story - “Myth of the Cave” from Plato’s book Republic. In this story, a few prisoners faced the wall and observed that only the shadows of objects found outside of the world were on the wall. We can correlate the actual objects to be latent variables in a higher dimension, while shadows are the observed variable. The key question is - can we learn these latent variables from observed variables? The answer is yes. Neural networks help us achieve that.
What are Autoencoders?
Autoencoder is an unsupervised learning approach for learning a lower dimensionAI feature representation from an unlabeled training data.“Encoder” learns mapping from the data, x, to a low-dimensional latent space z. But the problem is how can we learn this latent space since we only have unlabeled data. To solve this problem we train the model to use these features to reconstruct the original data.“Decoder” learns mapping back from latent, z, to a reconstructed observation x#use xcap”.

We calculate the loss between the original image and the generated image without using any labeled data and we can backpropagate over the network to train it.
What are Variational Autoencoders (VAEs)?
The latent space, vector z, is deterministic in nature i.e. for the same x it will produce the same z each time given the same weights. This would cause the problem of reconstructing the image rather than creating the variations in it and producing new samples. Variational Autoencoders(VAEs) replace the deterministic element z with a stochastic sampling operation. So instead of learning the z variable directly, a mean and variance for each variable is learnt in latent space which can then be parameterised to get a probability distribution. The new samples are created from various samples, and from these probability distributions of latent variables are defined by μ and σ.

The encoder computes the probability function p of z on x parameterised by ⱷ while decoder computes probability function q of x on z parameterised by θ. The loss function for VAEs carry two terms i.e. reconstruction loss and a regularization term. The reconstruction loss is same as of VAE but regularization term is divergence of inferred latent distribution with fixed prior on latent distribution.
The regularization term basically enforces a prior on the distribution of z and instructs how the distribution should look like.But how do we get this prior? A common choice for prior is normal gaussian distribution centered around mean 0 and variance 1.
- Encourages encodings to distribute evenly around the center of the latent space
- Penalize the network when it tries to “cheat” by clustering points in specific regions (i.e. memorizing the data)
The regularization term ensures continuity and completeness in the samples generated. By continuity, we mean that if two points are close in latent space they generate the same content after decoding, and completeness means that for any data point in latent space, the content generated is meaningful after decoding.
We cannot backpropagate gradients through the sampling layer due in the presence of a stochastic element. The backpropagation can be applied only on deterministic elements. To solve this problem, the reparameterization of the sampling layer is done. Consider the sampled latent vector as a sum of:
• a fixed 𝜇 vector,
• and fixed 𝝈 vector, scaled by random constants drawn from the prior distribution
Z = 𝜇 + 𝝈 ⊙ 𝜺
Where 𝜺 is taken from normal gaussian distribution.

Different dimensions of z encodes different interpretable latent features which can be found by slowly increasing or decreasing a single latent variable while keeping all other variables fixed. Ideally, we want latent variables that are not correlated with each other. Enforce diagonal prior on the latent variables to encourage independence.
What are Generative Adversarial Networks(GANs) and their recent advances ?
- Idea: Don’t explicitly model density, and instead just sample to generate new instances.
- Problem: Want to sample from a complex distribution – can’t do this directly!
- Solution: sample from something simple (noise), learn a transformation to the training distribution.
Generative Adversarial Networks (GANs) are a way to make a generative model by having two neural networks compete with each other. The generator turns noise into an imitation of the data to trick the discriminator. The discriminator tries to identify real data from fakes created by the generator.
Intuition behind the GAN is that Generator tries to improve its imitation of the data while Discriminator tries to predict what’s real and what’s fake.

The first part of the right hand side is log-probability that D correctly predicts real data x is real while second part is for og-probability that D correctly predicts generated data G(z) are generated.
Discriminator’s (D) goal: maximize prediction accuracy.
Generator’s (G) goal: minimize D’s prediction accuracy, by fooling D into believing its outputs G(z) are real as often as possible.
Take home message:-GANs are an implicit generative model trained as a two player game.
**Diffusion Models:-**Diffusion Models are generative models, which means that they are used to make the data imitate the data that they were trained on. Diffusion Models work by destroying training data by adding Gaussian noise to it over and over again, and then learning how to get the data back by reversing this process of adding noise.
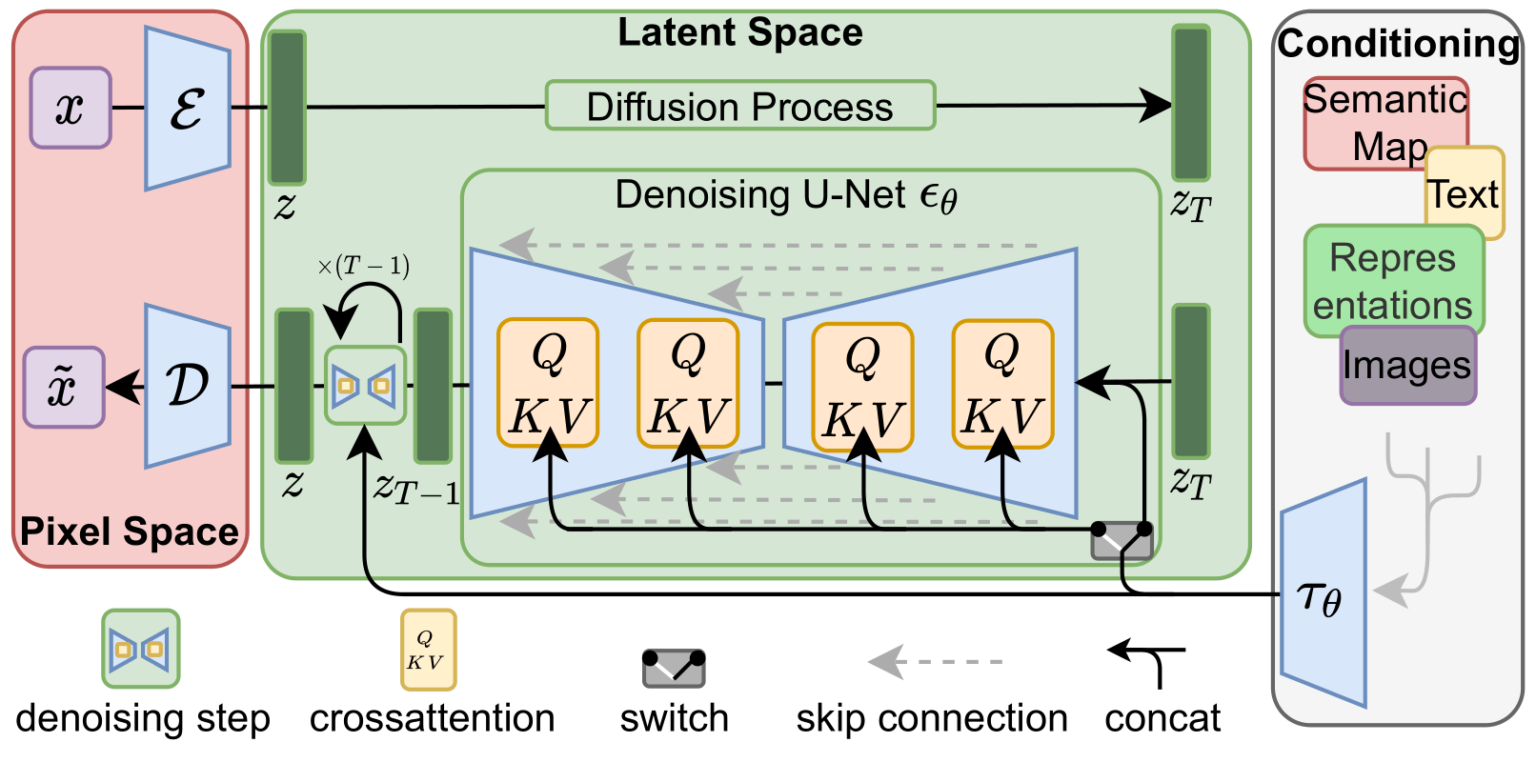
Stable Diffusion:-Let's consider the text2img case with their various components and their functions. A text is given as an input which passes through a Text Encoder (Use CLIPText). The Text Encoder produces token embeddings in latent space representing the features of the text.
These Token embeddings and a random noise is passed through Image Information Creator (Based on UNet + Scheduler). This is the component where the diffusion process takes place. The Image Information Creator produces a processed image tensor in latent space, which gets fed to Image Decoder (Based on Autoencoder Decoder) and a high resolution image is produced.
Generative Modeling on E2E Cloud:
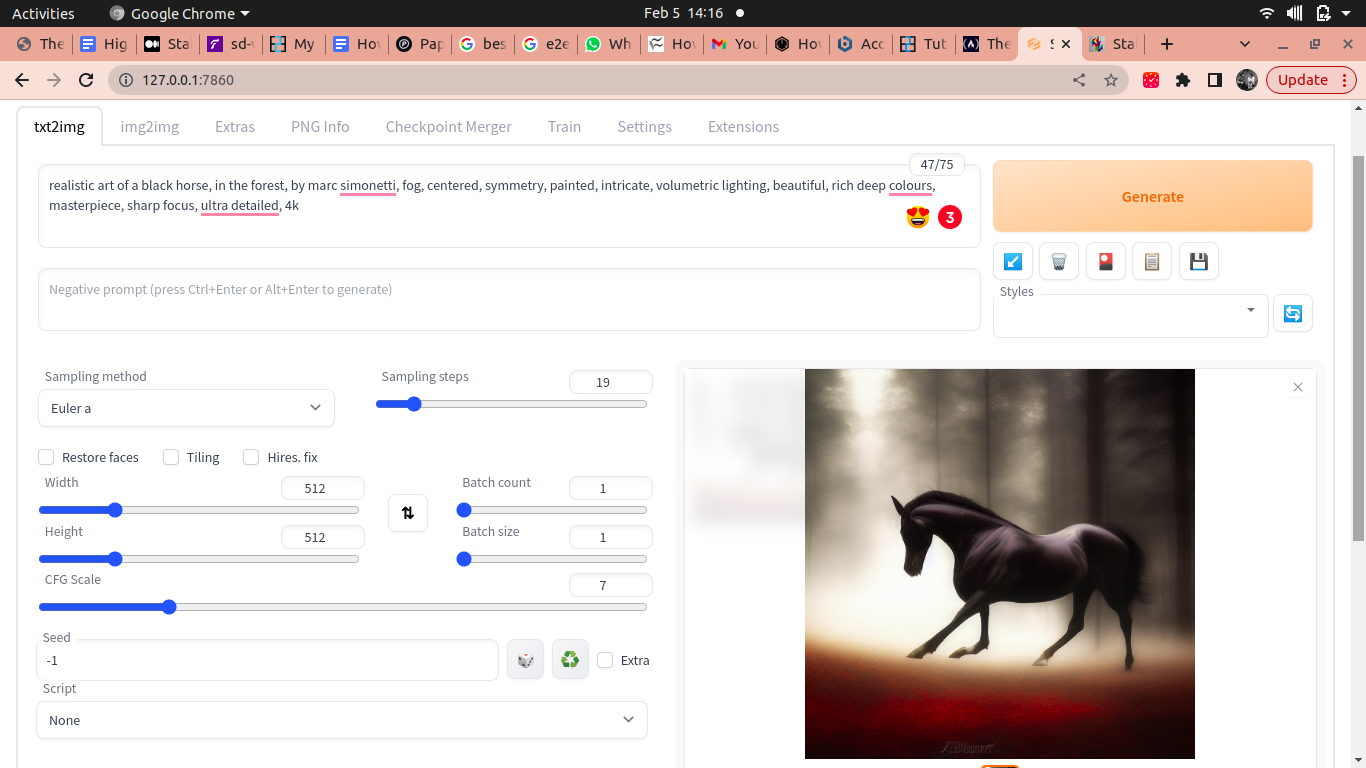
To learn about how to implement stable-diffusion webUI on E2E Cloud visit link.
A instance of stable-diffusion webUI running on E2E Cloud is demonstrated below:-
References:-
https://www.deepmind.com/learning-resources/deep-learning-lecture-series-2020
http://cs231n.stanford.edu/slides/2017/cs231n_2017_lecture13.pdf