Introduction to Object Tracking with YOLOv11
YOLOv11, released in October 2024, is the latest iteration of the "You Only Look Once" (YOLO) series, designed for real-time object detection. This model introduces significant enhancements over its predecessors, focusing on efficiency, accuracy, and versatility in various applications.
Standout Features of YOLOv11
- Improved Accuracy and Efficiency: YOLOv11m achieves higher mean Average Precision (mAP) on the COCO dataset while utilizing 22% fewer parameters than YOLOv8m. This makes it computationally efficient without sacrificing performance.
- Versatile Task Support: The model supports a wide range of computer vision tasks, including Object Detection, Instance Segmentation, Image Classification, Pose Estimation, and Oriented Object Detection (OBB).
- Enhanced Feature Extraction: With an improved backbone and neck architecture, YOLOv11 enhances feature extraction capabilities, leading to more precise object detection.
- Optimized for Speed: The architectural improvements allow for faster processing rates, making YOLOv11 suitable for real-time applications. It reportedly operates up to 2% faster than its predecessor, YOLOv10.
- Adaptability: YOLOv11 can be deployed across various environments, including edge devices and cloud platforms, ensuring flexibility in application.
Industries That Can Benefit from YOLOv11
YOLOv11's advanced object tracking technology can significantly impact several industries:
- Transportation: For vehicle tracking and traffic management systems.
- Retail: Enhancing customer experience through people tracking and inventory management.
- Healthcare: Assisting in medical image analysis and monitoring patient movements.
- Security: Implementing surveillance systems that require real-time object detection and tracking.
- Agriculture: Monitoring livestock or crop health through aerial imagery analysis.
- Robotics: Enabling robots to navigate and interact with their environments by recognizing objects in real-time.
Our Aim in This Tutorial
In this guide, we’ll take you through the process of fine-tuning and deploying YOLOv11 to detect and track specific objects, such as humans, cars, and packaging. By tailoring the model to recognize these categories, you can apply it to various scenarios, including monitoring traffic on highways, detecting people in work environments, or identifying packaging in manufacturing or retail settings.
Whether you are aiming to enhance operational efficiency, improve safety, or optimize resource management, this step-by-step guide will show you how to effectively train and deploy YOLOv11 for your object tracking needs. Let's get started!
Let’s Code
Step 1: Installing the Necessary Libraries
The first library, OpenCV (installed via opencv-python), is a powerful tool for handling various computer vision tasks. It enables the manipulation and analysis of visual data, including images and video streams, which is essential for tasks like object detection, tracking, and recognition.
The second library, Ultralytics, provides the framework to implement YOLO models, including the latest YOLOv11. YOLO (You Only Look Once) is a real-time object detection system known for its speed and accuracy. The Ultralytics library simplifies the deployment and fine-tuning of YOLO models, allowing users to detect objects efficiently in various environments.
!pip install opencv-python ultralytics
Step 2: Importing the Libraries
import cv2
from ultralytics import YOLO
Step 3: Training the Model
First, the yolo command runs a pre-trained YOLOv11 model (yolo11m.pt) to detect objects in an image. The task=detect specifies that the task is object detection, and mode=predict means it is using the model to make predictions. The source parameter provides the image URL (in this case, an image of a bus) where the object detection will be applied.
The second part of the code involves loading the YOLOv11 model (YOLO("/content/yolo11m.pt")) and training it further on a custom dataset. Here, the dataset for car detection is specified in the file car.yaml, and the model is trained for 100 epochs with images resized to 640x640 pixels. This fine-tuning step is crucial for adapting the pre-trained YOLOv11 model to specific tasks, such as detecting cars, by learning patterns specific to the new dataset.
Overall, this code demonstrates both the deployment of a pre-trained model for object detection and the customization of the model through additional training.
!yolo task=detect mode=predict model=yolo11m.pt source="https://ultralytics.com/images/bus.jpg"
model = YOLO("/content/yolo11m.pt")
# Train the model
results = model.train(data="/content/car.yaml", epochs=100, imgsz=640)
Here’s an example of the dataset structure:
This dataset structure is organized to train and test the YOLO model for object detection. It follows a clear separation between training and testing data, ensuring that the model can be both trained and evaluated effectively.
- /train: This folder contains the images and corresponding label files used for training the model. Each image (e.g., image1.jpg, image2.jpg) has an associated label file in the /labels subdirectory (e.g., image1.txt, image2.txt), which provides the bounding box coordinates and class labels for objects in each image.
- /test: Similar to the /train directory, this folder holds images and label files but is meant for testing the model's performance. These files are used to evaluate how well the trained model performs on unseen data.
- dataset.yaml: This configuration file provides the necessary metadata for the YOLO model to understand the dataset structure. It typically includes information such as the paths to the training and testing data, the number of classes, and class names. This file helps guide the training process by defining how the model should interpret the dataset.
Overall, this structured layout ensures that both the training and evaluation processes are well-organized and streamlined for fine-tuning the YOLO model.
/dataset
│
├── /train
│ ├── image1.jpg
│ ├── image2.jpg
│ ├── ...
│ └── labels
│ ├── image1.txt
│ ├── image2.txt
│ └── ...
│
├── /test
│ ├── imageA.jpg
│ ├── imageB.jpg
│ ├── ...
│ └── labels
│ ├── imageA.txt
│ ├── imageB.txt
│ └── ...
│
└── dataset.yaml
Step 4: Choosing the Model
# Load the fine-tuned model
model = YOLO("/content/runs/detect/train/weights/best.pt")
Step 5: Creating Videowriter to Save Results of the Video
This function, create_video_writer, is designed to initialize a video writer for saving processed video frames into an MP4 file.
- The function takes two inputs:some text
- video_cap: A video capture object (usually created using OpenCV), which provides access to the video stream.
- output_filename: The name of the output MP4 file where the video will be saved.
- The function extracts key properties from the video stream, such as:some text
- Frame width and height: The resolution of the video.
- FPS (frames per second): The frame rate of the video.
- It then initializes a FourCC (Four Character Code), which defines the video codec to use for encoding. In this case, it uses 'MP4V', the codec for MP4 video.
- Finally, the function creates and returns a VideoWriter object, which can be used to write frames to the specified output file. This function is essential when you want to process video frames (like adding object detection boxes) and save the results into a new video file.
# defining function for creating a writer (for mp4 videos)
def create_video_writer(video_cap, output_filename):
# grab the width, height, and fps of the frames in the video stream.
frame_width = int(video_cap.get(cv2.CAP_PROP_FRAME_WIDTH))
frame_height = int(video_cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
fps = int(video_cap.get(cv2.CAP_PROP_FPS))
# initialize the FourCC and a video writer object
fourcc = cv2.VideoWriter_fourcc(*'MP4V')
writer = cv2.VideoWriter(output_filename, fourcc, fps,
(frame_width, frame_height))
return writer
Step 5: Detecting Objects in Videos with YOLOv11
This code block processes a video using object detection and writes the results into a new output video file.
Here’s a brief overview of what it does:
- Video Input/Output Setup:some text
- output_filename: Defines the name of the output video file where processed frames will be saved (e.g., "YourFilename.mp4").
- video_path: Points to the input video file (e.g., "YourVideoPath.mp4").
- cv2.VideoCapture(video_path): Opens the video stream from the specified file.
- create_video_writer(cap, output_filename): Creates a writer to save processed video frames using the function defined earlier.
- Frame-by-Frame Processing:some text
- A loop reads frames from the video stream using cap.read(). If a frame is successfully read (success is True), it proceeds to the next steps; otherwise, it exits the loop.
- The frame is passed to predict_and_detect(model, img, classes=[], conf=0.5), which performs object detection using the specified YOLO model. The detected objects are then drawn on the frame (result_img).
- The processed frame is written to the output file using writer.write(result_img).
- The frame is also displayed in a window using cv2.imshow("Image", result_img) for real-time visualization.
- Cleanup:some text
- The writer.release() ensures that the video writer is properly closed and the video file is saved correctly when processing is complete.
This code processes an entire video, applying object detection to each frame, saving the result into a new video, and displaying the processed frames in real time.
output_filename = "YourFilename.mp4"
video_path = r"YourVideoPath.mp4"
cap = cv2.VideoCapture(video_path)
writer = create_video_writer(cap, output_filename)
while True:
success, img = cap.read()
if not success:
break
result_img, _ = predict_and_detect(model, img, classes=[], conf=0.5)
writer.write(result_img)
cv2.imshow("Image", result_img)
cv2.waitKey(1)
writer.release()
The Whole Code
import cv2
from ultralytics import YOLO
def predict(chosen_model, img, classes=[], conf=0.5):
if classes:
results = chosen_model.predict(img, classes=classes, conf=conf)
else:
results = chosen_model.predict(img, conf=conf)
return results
def predict_and_detect(chosen_model, img, classes=[], conf=0.5, rectangle_thickness=2, text_thickness=1):
results = predict(chosen_model, img, classes, conf=conf)
for result in results:
for box in result.boxes:
cv2.rectangle(img, (int(box.xyxy[0][0]), int(box.xyxy[0][1])),
(int(box.xyxy[0][2]), int(box.xyxy[0][3])), (255, 0, 0), rectangle_thickness)
cv2.putText(img, f"{result.names[int(box.cls[0])]}",
(int(box.xyxy[0][0]), int(box.xyxy[0][1]) - 10),
cv2.FONT_HERSHEY_PLAIN, 1, (255, 0, 0), text_thickness)
return img, results
# defining function for creating a writer (for mp4 videos)
def create_video_writer(video_cap, output_filename):
# grab the width, height, and fps of the frames in the video stream.
frame_width = int(video_cap.get(cv2.CAP_PROP_FRAME_WIDTH))
frame_height = int(video_cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
fps = int(video_cap.get(cv2.CAP_PROP_FPS))
# initialize the FourCC and a video writer object
fourcc = cv2.VideoWriter_fourcc(*'MP4V')
writer = cv2.VideoWriter(output_filename, fourcc, fps,
(frame_width, frame_height))
return writer
model = YOLO("/content/runs/detect/train/weights/best.pt")
output_filename = "YourFilename.mp4"
video_path = r"YourVideoPath.mp4"
cap = cv2.VideoCapture(video_path)
writer = create_video_writer(cap, output_filename)
while True:
success, img = cap.read()
if not success:
break
result_img, _ = predict_and_detect(model, img, classes=[], conf=0.5)
writer.write(result_img)
cv2.imshow("Image", result_img)
cv2.waitKey(1)
writer.release()
Video Links
- Yolo11 Detects Cars On Highway yollo-11-car.mp4
- Workers Working: Human Detection Factory-people-working-detection.mp4
- People Shopping in Store people-shopping-detection.mp4
- People Office Door Detection people-office-detection.mp4
For Image Processing
from ultralytics import YOLO
import cv2
def predict(chosen_model, img, classes=[], conf=0.5):
if classes:
results = chosen_model.predict(img, classes=classes, conf=conf)
else:
results = chosen_model.predict(img, conf=conf)
return results
def predict_and_detect(chosen_model, img, classes=[], conf=0.5, rectangle_thickness=2, text_thickness=1):
results = predict(chosen_model, img, classes, conf=conf)
for result in results:
for box in result.boxes:
cv2.rectangle(img, (int(box.xyxy[0][0]), int(box.xyxy[0][1])),
(int(box.xyxy[0][2]), int(box.xyxy[0][3])), (255, 0, 0), rectangle_thickness)
cv2.putText(img, f"{result.names[int(box.cls[0])]}",
(int(box.xyxy[0][0]), int(box.xyxy[0][1]) - 10),
cv2.FONT_HERSHEY_PLAIN, 1, (255, 0, 0), text_thickness)
return img, results
model = YOLO("/content/runs/detect/train/weights/best.pt")
# read the image
image = cv2.imread("YourImagePath.png")
result_img, _ = predict_and_detect(model, image, classes=[], conf=0.5)
cv2.imshow("Image", result_img)
cv2.imwrite("YourSavePath.png", result_img)
cv2.waitKey(0)
This code defines two functions to handle object detection using a YOLO model and applies them to an image, displaying the result.
- predict function:some text
- This function makes predictions using the given chosen_model (a YOLO model). It takes the image (img), a list of classes to detect (classes=[]), and a confidence threshold (conf=0.5).
- If specific classes are provided, it filters the detection to those classes; otherwise, it performs detection on all object classes in the image.
- predict_and_detect function:some text
- This builds on the predict function to not only make predictions but also draw bounding boxes around detected objects in the image.
- For each object detected, a bounding box (rectangle) is drawn using the coordinates provided by YOLO (box.xyxy). The class name of the detected object is displayed above the box using cv2.putText().
- The rectangle_thickness and text_thickness parameters control the thickness of the bounding box and text.
- Model and Image Handling:some text
- The YOLO model is loaded from the specified path (/content/runs/detect/train/weights/best.pt), which is assumed to be a trained model.
- An image is loaded using OpenCV (cv2.imread("YourImagePath.png")), and then passed to the predict_and_detect function for processing.
- The processed image, with object detections and bounding boxes, is displayed (cv2.imshow("Image", result_img)) and saved to a file (cv2.imwrite("YourSavePath.png", result_img)).
This code performs object detection on a single image and visualizes the results by drawing rectangles around detected objects and labeling them with their class names.
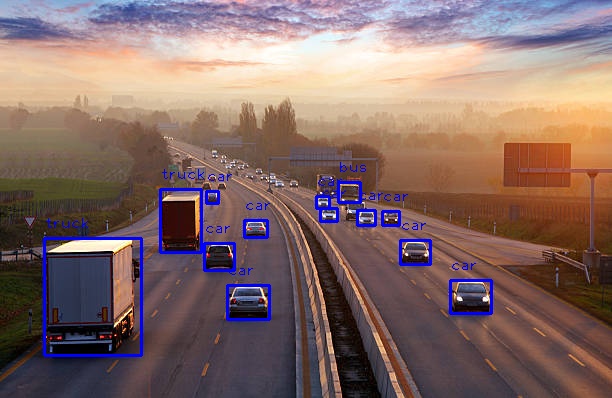

Conclusion
Today, we delved into the fascinating world of object detection and demonstrated how powerful it can be in various applications.