Introduction
AI-generated images are revolutionizing the process of visual content creation. With just simple text inputs, these models can create highly detailed, stunning visuals, providing a new level of accessibility for designers, marketeers, and content creators. This technology is accelerating workflows and making creative processes more efficient by automating image generation. Whether for digital art, product showcases, or personalized marketing content, AI tools like Flux.1 makes it possible for users to transform ideas into reality within a fraction of time, reshaping how visual content is produced.
In this tutorial, you will learn how to implement image generation using FLUX.1-dev-gguf model in ComfyUI. Flux.1 is an advanced AI model designed for generating high-quality visuals from simple text prompts.
ComfyUI: An Overview
ComfyUI is a flexible, node-based interface designed for running and testing AI diffusion models. It simplifies the process of creating image generation workflows by allowing users to easily connect different components like models, prompts, and outputs without the need for deep coding knowledge. Its easy-to-use design makes it accessible for both beginners and advanced users, supporting experimentation with various configurations and parameters.
Why Use FLUX.1-dev-gguf
FLUX.1-dev-gguf is a quantized version of the FLUX.1-dev model, designed to significantly reduce the memory footprint while maintaining high-quality image generation capabilities. This quantization method optimizes the model using lower precision (e.g., 8-bit or mixed-precision), making it more efficient on hardware with limited resources like older or smaller GPUs. This helps users to deploy the models on less powerful systems without sacrificing much performance. Compared to FLUX.1-dev, FLUX.1-dev-gguf is perfect for users trying to generate images with computational power, offering faster inference times and lower VRAM consumption. Therefore, keeping resource efficiency is a priority, and using FLUX.1-dev-gguf is a more accessible and cost-effective solution for image generation tasks.
Steps to Generate Images
Step 1: Install ComfyUI
First, clone the ComfyUI repository and download its requirements to launch the web server for easily accessing nodes through the interface.
git clone https://github.com/comfyanonymous/ComfyUI.git
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu124
cd ComfyUI
pip install -r requirements.txt
Step 2: Download and Save the Models
To use quantized FLUX.1-dev models in ComfyUI, you'll need to download and save the models within the ComfyUI directory:
- U-Net Model: Download the FLUX.1-dev-gguf model from Flux-dev-gguf and save it in the U-Net folder inside the ComfyUI directory.
- CLIP Models: Since quantized models do not include in-built CLIP models, you'll need to download them from Flux Text Encoders and save them in the CLIP folder.
- VAE Model: Download the VAE model from FLUX.1-schnell and place it in the VAE folder within the ComfyUI directory.
By organizing these models in the respective folders, you ensure that ComfyUI can utilize them effectively for image generation tasks.
Step 3: Add Custom Nodes
For using gguf models in ComfyUI, you need to clone ComfyUI-GGUF in the custom_nodes folder in the ComfyUI directory.
git clone https://github.com/comfyanonymous/ComfyUI.git
Launch the web server of ComfyUI by running:
python3 main.py
It should automatically detect your GPU to improve performance.
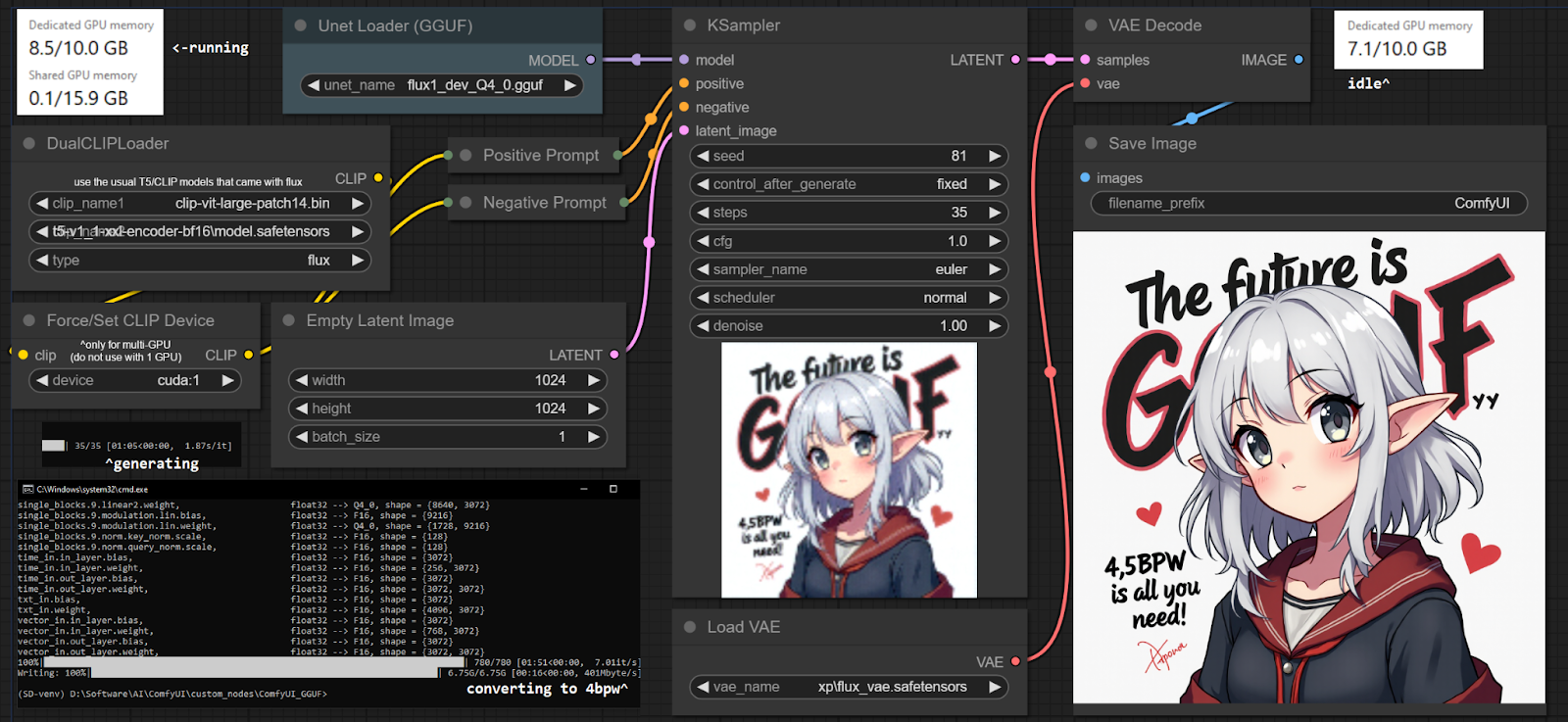
Step 4: Design the Workflow
Add the following nodes in the workflow:
- U-Net Loader (gguf):This node loads the quantized U-Net model for diffusion processes; it is responsible for generating images from noise with reduced memory usage.
- DualCLIPLoader (gguf): This node loads two quantized CLIP models, which are used to encode text prompts and guide image generation, enhancing comparison between text and image.
- Load VAE: Loads the Variational Autoencoder (VAE) model; it is responsible for encoding and decoding images between pixel space and latent space during generation.
- CLIP Text Encode: Inputs text prompts and encodes into vector representations using a CLIP model, guiding the diffusion process to generate images aligned with the text.
- EmptySD3LatentImage: This node creates an empty latent image that serves as a starting point for workflows, used in the initial stages of image synthesis.
- FluxGuidance: Adds Flux-based guidance to the generation process, helping refine the output based on specific parameters or constraints and enhancing control over the final image.
- KSampler: Samples the latent space during the diffusion process, controlling parameters like noise level and iteration count to shape the final image quality.
- VAE Decode: Converts the latent representation back into an image using the VAE, producing a pixel-level image from the compressed latent space.
- Save Image: Saves the generated image to the output directory in the format specified by the user, completing the image generation workflow.
You can use this workflow as a reference workflow.json. Load it by clicking on Load and selecting this workflow.

Now you can select the downloaded models: FLUX.1-dev-gguf model, CLIP model, and VAE model respectively.
Step 5: Configurations
To fine-tune the output in ComfyUI when using FLUX.1-dev-gguf, you can try different configurations in the KSampler, which controls key parameters such as steps, CFG scale, and noise.
Experimenting with different CLIP models like the t5-v1_1-xxl-encoder-gguf can also affect the generated images, allowing for better outputs based on the text prompts provided.

To adjust image size, simply modify the height and width settings in the EmptySD3LatentImage node. This allows you to generate images of different dimensions according to your needs.
Step 6: Prompting
Now that the workflow is set up in ComfyUI, you can start generating images based on your prompts. In the CLIP Text Encode nodes, provide your own positive and negative prompts.
The node connected to the positive terminal of KSampler represents the positiveprompt, and the node connected to the negative terminal represents the negativeprompt.
Once you've added your prompts, click Generate to start the image generation workflow.
The current running node will be highlighted.
Outputs
Prompt 1
A close-up view of an elegant luxury product display, showcasing high-end handbags and jewelry in a premium ecommerce store.

Prompt 2
A customer receiving the keys to a brand-new car at a dealership, with a salesperson handing over the keys and shaking hands in a celebratory moment.

Prompt 3
A cozy coffee shop on a rainy day, with customers sitting at tables, steam rising from hot coffee mugs, and a barista making a cappuccino behind the counter.

The outputs are saved as the image name provided and in the output folder.
Conclusion
By following this guide, you can efficiently implement the FLUX.1-dev-gguf model in ComfyUI to generate high-quality images with minimal system resources. By experimenting with various prompts and configurations in nodes like KSampler and CLIP Text Encode, users can fine-tune models to get tailored results to match their creative vision. With the right configurations, this workflow delivers visually stunning images for your needs, making AI-driven image generation accessible and highly customizable.