What Is cuGraph?
cuGraph is a powerful graph analytics library that is part of the RAPIDS AI ecosystem, designed to leverage GPU acceleration for high-performance data science and analytics. It enables users to perform graph computations efficiently, making it suitable for large-scale applications across various domains, including social network analysis, fraud detection, and molecular chemistry.
Key Features of cuGraph
- GPU Acceleration: NVIDIA cuGraph utilizes the CUDA architecture to perform graph analytics at unprecedented speed, allowing for real-time or near-real-time processing of large graphs.
- Versatile Algorithms: The library includes a range of algorithms for graph analytics, such as betweenness centrality, PageRank, and community detection using methods like the Louvain algorithm.
- Integration with Other Libraries: cuGraph integrates seamlessly with other RAPIDS libraries, such as cuDF (for DataFrame manipulation) and cuML (for machine learning), enabling a comprehensive data science workflow on GPUs.
- Support for Various Graph Types: It supports multiple graph structures, including directed, undirected, weighted, and unweighted graphs, as well as property graphs and hypergraphs.
Applications
NVIDIA cuGraph is particularly useful in scenarios requiring the analysis of complex relationships within data. Some common applications include:
- Social Network Analysis: Identifying influencers or communities within social networks.
- Healthcare: Analyzing drug interactions or patient networks.
- Finance: Detecting fraudulent activities through transaction networks.
cuGraph is an essential tool for data scientists and analysts looking to harness the power of GPU computing for efficient graph analytics and processing. Its capabilities make it a valuable asset in various fields that require deep insights from complex data structures.
How to Build a Knowledge Graph RAG with cuGraph and Llama 3.1
Building a Knowledge Graph Retrieval-Augmented Generation (RAG) involves extracting meaningful entities and their relationships from textual data and visualizing them. This blog will demonstrate how to build a Knowledge Graph using cuGraph and Llama 3.1 to enhance retrieval capabilities. The code presented here uses E2E’s powerful infrastructure to emphasize scalability and performance.
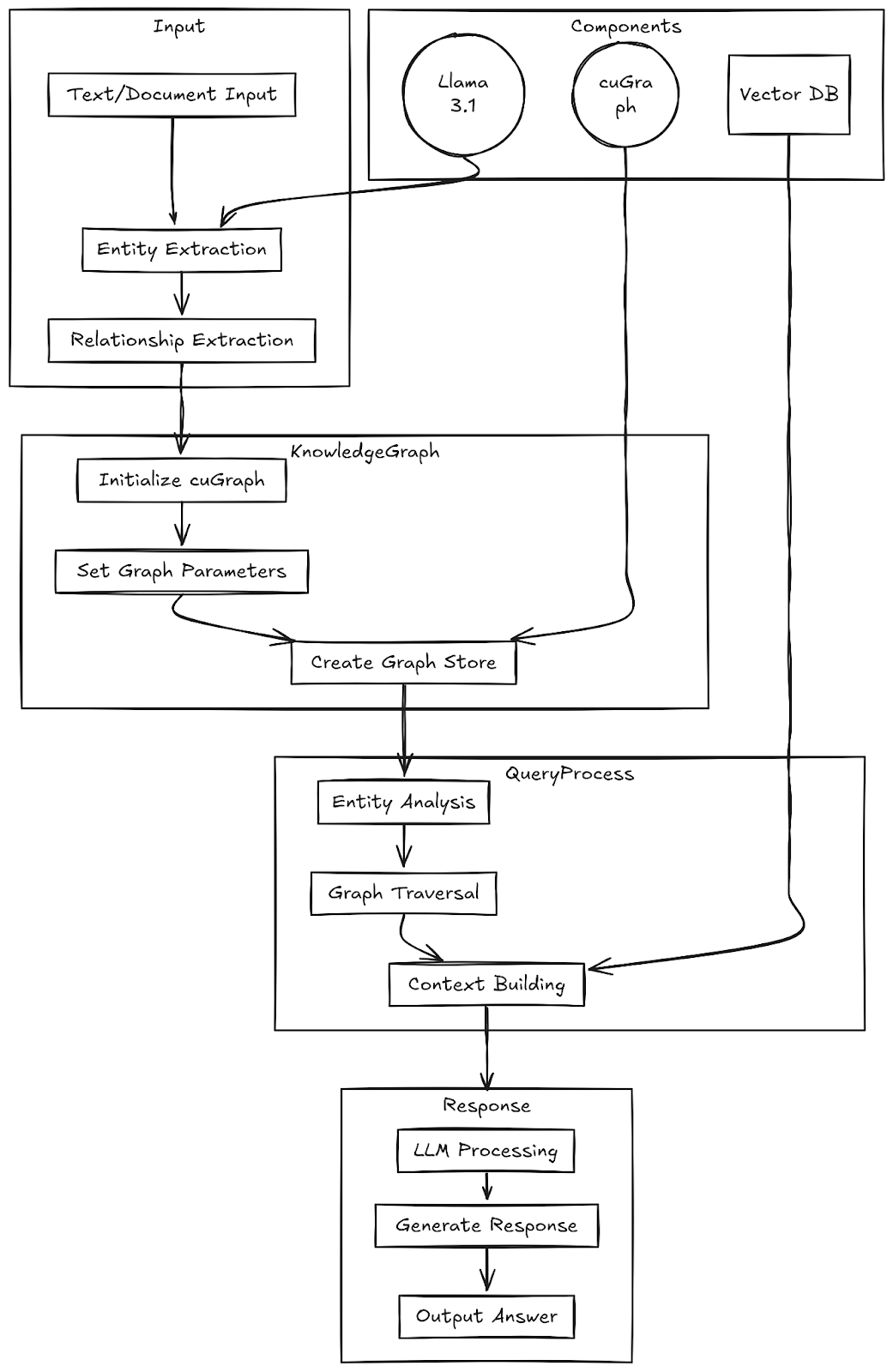
System Overview
This implementation combines:
- cuGraph for efficient graph processing
- Llama 3.1 for natural language understanding
- Python libraries for visualization and data manipulation
Prerequisites
Before starting, ensure you have access to:
- An E2E GPU node with sufficient memory
- CUDA-enabled environment
- Required Python packages: cudf, cugraph, llama-cpp, langchain
Let’s Code
Step 1: Setting Up the Environment
Start by installing the necessary libraries. We’re using cuGraph for graph processing and LlamaCPP to integrate the Llama model for natural language processing tasks.
Required Libraries
- cuDF and cuGraph: GPU-accelerated data frames and graph processing.
- LlamaCpp: A Python wrapper for Llama models to generate embeddings and perform NLP.
Download the Llama 3.1 Model
We use the Llama 3.1 model from Hugging Face. It provides robust capabilities for entity extraction and semantic embeddings.
Initialize the required components and download the Llama model:
Step 2: Configuring the Llama Model
Step 3: Extract Relationships from the Text
To build a Knowledge Graph, extract entities and their relationships from input text. The following function uses Llama 3.1 to process text and return structured relationships.
Step 4: Knowledge Graph Creation
Implement the graph creation using cuGraph:
Step 5: Visualization
To visualize the Knowledge Graph, use NetworkX and Matplotlib.
Example Usage
Here's a sample conversation analysis:
Results
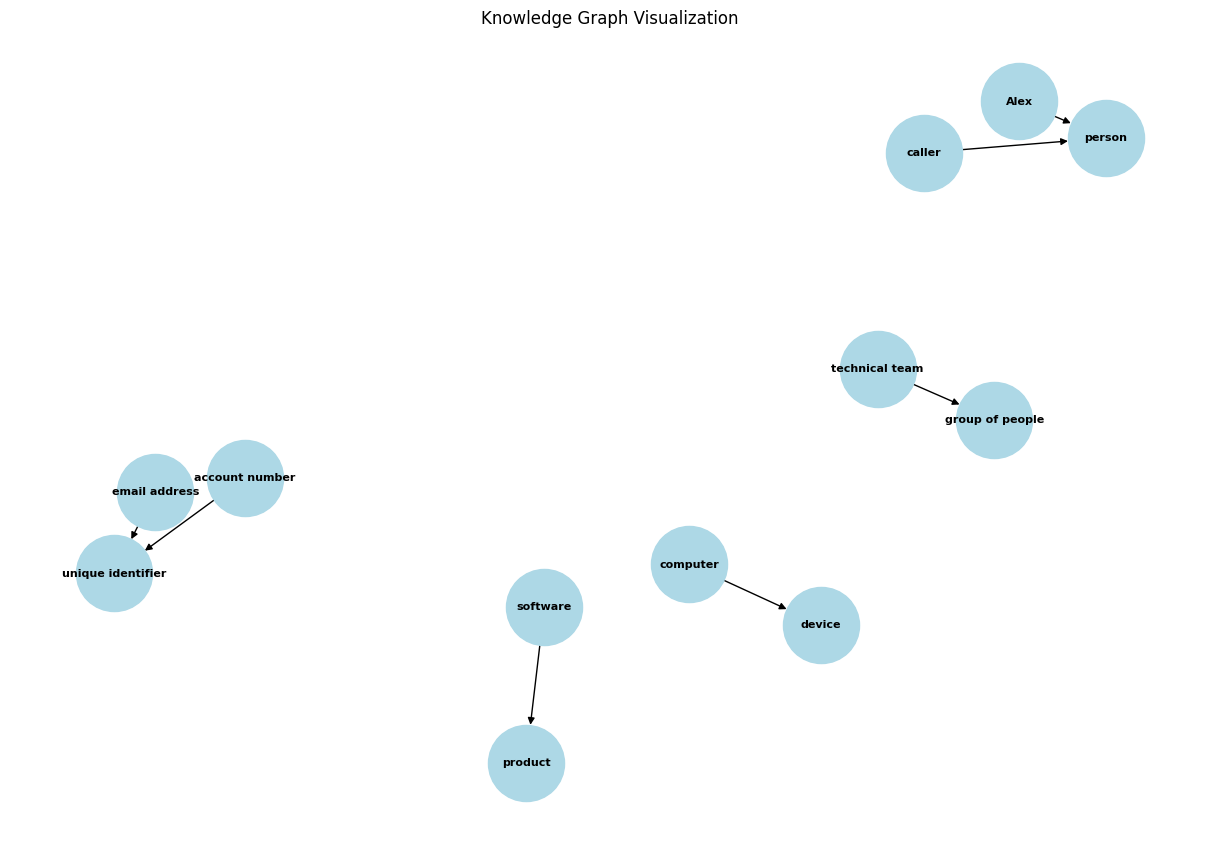
The system successfully identified and mapped various entities and their relationships:
- Personal entities (Alex, caller)
- Technical components (software, computer)
- Organizational units (technical team)
- Identifiers (account number, email address)
Things to Keep in Mind
Key Features
- GPU Acceleration: Utilizes cuGraph for efficient graph processing.
- Advanced NLP: Leverages the capabilities of Llama 3.1 for relationship extraction.
- Interactive Visualization: Provides clear and intuitive visualization of entity relationships.
- Scalable Architecture: Efficiently handles complex conversational data.
Technical Considerations
- Adjust n_gpu_layers based on the available GPU memory.
- Configure the batch size and context length according to your requirements.
- Consider the relationship types when designing the graph structure.
Why Choose E2E Cloud?
This guide has shown how by integrating cuGraph with Llama 3.1, we achieved GPU-accelerated graph processing and robust entity extraction. While this tutorial uses E2E's scalable platform, the approach is designed to ensure compatibility with other systems. Combining NLP with graph analytics opens the door to advanced Knowledge Graph applications, enhancing tasks such as question answering, semantic search, and retrieval-based generation (RAG).
Why choose E2E Cloud?
- Unbeatable GPU Performance: Access top-tier GPUs like H200, H100, and A100—ideal for state-of-the-art AI and big data projects.
- India’s Best Price-to-Performance Cloud: Whether you’re a developer, data scientist, or AI enthusiast, E2E Cloud delivers affordable, high-performance solutions tailored to your needs.
Get Started Today
Ready to supercharge your projects with cutting-edge GPU technology?
- Launch a cloud GPU node tailored to your project needs.
E2E Cloud is your partner for bringing ambitious ideas to life, offering unmatched speed, efficiency, and scalability. Don’t wait—start your journey today and harness the power of GPUs to elevate your projects.