Introduction
Recently, researchers from Chennai introduced the ‘World’s First Autonomous AI University Professor’, known as the ‘Malar Teacher’. This AI teacher / professor has been built with an understanding of the entire engineering syllabus of Anna University.
The most interesting fact about ‘Malar Teacher’ is that it is accessible through WhatsApp. Since it has access to all the recommended study materials, it can teach any concept from the syllabus, and simplify topics to a 10-year-old's comprehension level.
Leveraging WhatsApp, a widely used messaging application in India, was a masterstroke, as it widely increased the accessibility of this AI, and demonstrated how exactly AI might create a positive impact in India.
In this article, we will demonstrate how to build a similar AI Professor Chatbot, using purely open-source technologies and an open LLM - Mistral-7B. This can be highly relevant for future EdTech startups, universities, coaching institutes and other businesses operating in the Education sector.
Since access to WhatsApp API is through third-party partners, we will instead use Telegram for demonstration purposes. However, the core methodology, especially the AI application architecture used, would be very similar in case of WhatsApp. You would just need to replace the send/receive APIs.
Let’s get started.
Chatbot Workflow
We’ll be using the Retrieval Augmented Generation (RAG) technique for our chatbot. It’s a method of “grounding” an LLM’s response by connecting it to an external knowledge source. This is extremely useful when we want our applications to read and understand documents. By sending contextually relevant information from the documents to the LLM, one can receive information about them by querying the LLM in simple natural language.
Below is a diagrammatic workflow for our chatbot - it will help in understanding the tech under the hood.
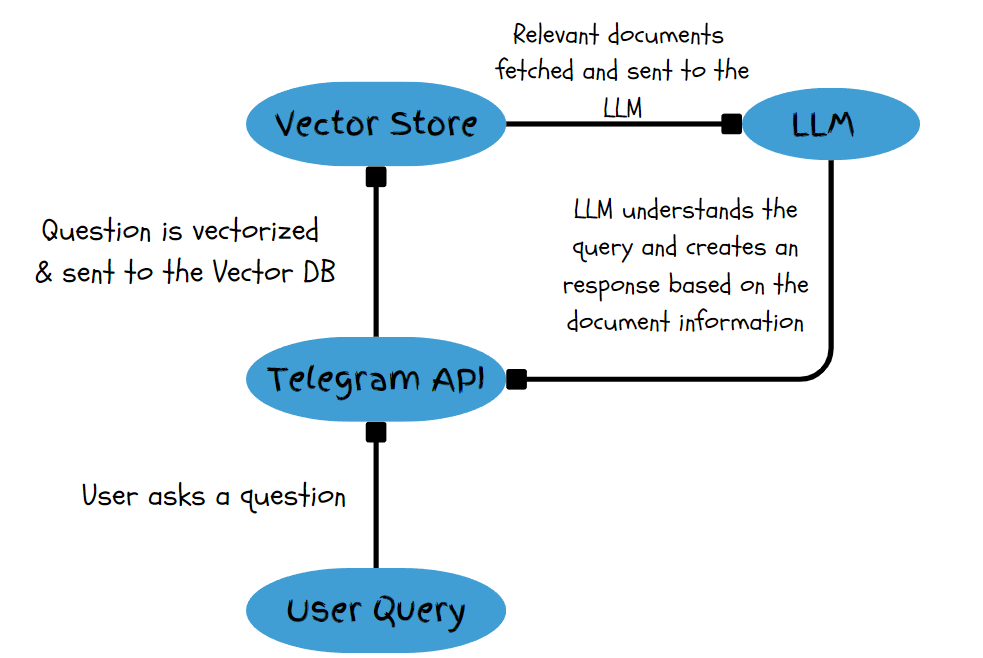
Components used:
- Mistral-7B LLM hosted on Ollama
- Chromadb Vector Store
- LangChain for document ingestion and retrieval
- Telegram API & Python SDK
Let’s Get to the Code
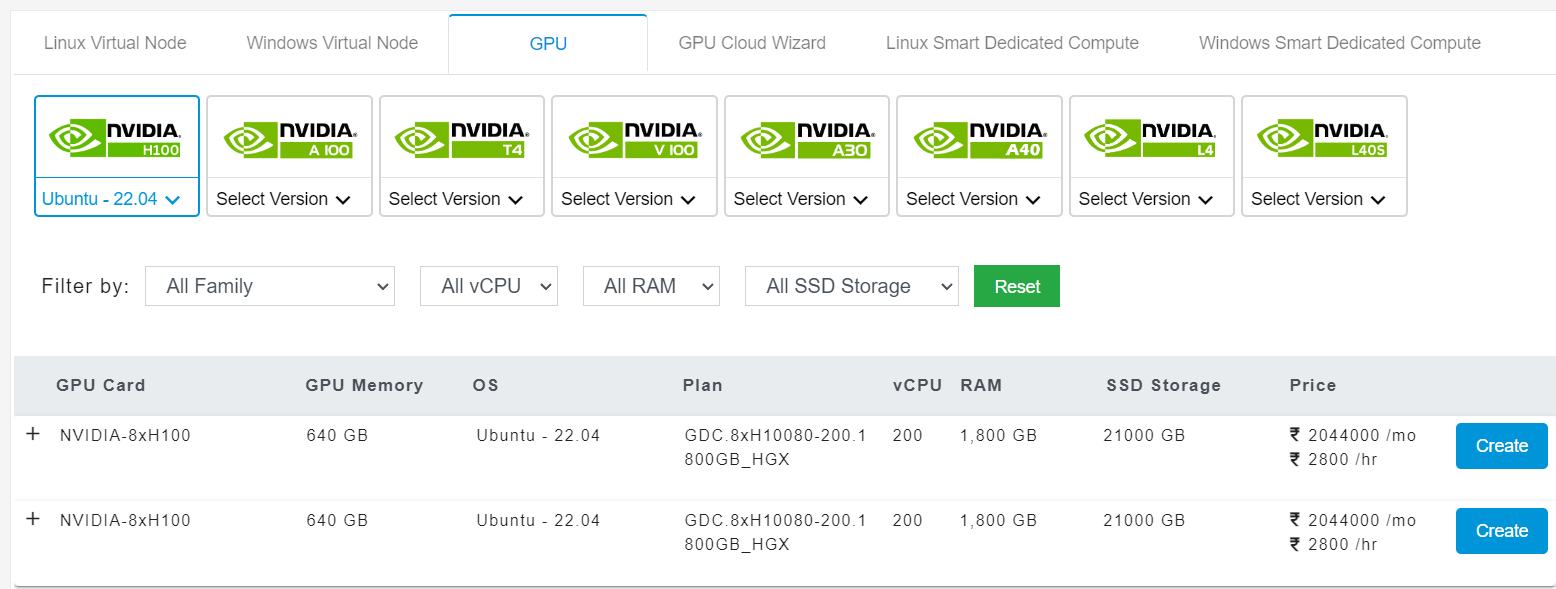
For hosting the LLM we’ll be needing a GPU-server to handle the AI workload. E2E Networks provides a fleet of advanced GPUs which are tailored specifically for this purpose.
You can check out the GPU offerings by heading over to https://myaccount.e2e networks.com/. Click on Compute on the left-hand side, then click on Nodes, and Add New Node.
First, install all the necessary dependencies.
langchain
python-telegram-bot
ollama
chromadb
asyncio
nest_asyncio
Now open Telegram and search for BotFather to get an API token for the Telegram bot. BotFather is a service offered by Telegram to manage and create new bots.
With the command /newbot you can name and create your own bot. You’ll receive an API_TOKEN of that bot.
Spin up a Jupyter notebook and import all the required libraries:
import logging
from telegram import Update
from telegram.constants import ParseMode
from telegram.ext import Updater, CommandHandler, MessageHandler, filters, ApplicationBuilder, ContextTypes
from langchain.document_loaders import PyPDFLoader
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import Chroma
from langchain_text_splitters import RecursiveCharacterTextSplitter
from ollama import Client
import nest_asyncio
from telegram.helpers import escape_markdown
import asyncio
Set up the API_TOKEN, the logging info, the Ollama client, and a textsplitter object.
-
The Telegram Bot API utilizes asynchronous programming to handle and execute requests concurrently.
-
When an
awaitstatement is encountered, the program jumps to another ready task while the awaited task completes. -
An event loop manages the flow of execution whenever an
awaitstatement is encountered. It continuously checks for tasks that are ready to run and executes them based on their priority and readiness. -
The event loop takes control and executes other ready tasks when an
awaitstatement is reached. -
If another
awaitstatement is encountered, the event loop again takes control and decides the next action. -
Async programming ensures efficient utilization of resources by executing other parts of the code while one part is busy.
-
Asynchronous programming is highly effective for Telegram bots handling thousands of users simultaneously.
nest_asyncio.apply()
# Replace 'YOUR_API_TOKEN' with the token you received from the BotFather
API_TOKEN = 'YOUR_API_TOKEN'
# Set up logging
logging.basicConfig(format='%(asctime)s - %(name)s - %(levelname)s - %(message)s', level=logging.INFO)
logger = logging.getLogger(name)
client = Client(host='http://localhost:11434')
text_splitter = RecursiveCharacterTextSplitter(
# Set a really small chunk size, just to show.
chunk_size=512,
chunk_overlap=20,
length_function=len,
is_separator_regex=False,
)
Refer to this to start a Ollama server and pull the Mistra-7B model on your local server.
Load the embeddings model to convert text into vectors:
embeddings = HuggingFaceEmbeddings(model_name= 'BAAI/bge-large-en')
We create a function to convert PDF into Document format with a chunk size of 512 tokens each as defined by the text splitter.
def load_and_process_documents(file_path):
loader = PyPDFLoader(file_path)
pages = loader.load_and_split(text_splitter=text_splitter)
for page in pages:
page.page_content = page.page_content.replace('\n',' ')
return pages
We create a function which will refresh the user data (vector DB) every time the command ‘/start’ is sent. This will allow users to start over fresh.
async def start(update: Update, context: ContextTypes.DEFAULT_TYPE):
"""Handler for the /start command"""
user_id = update.effective_user.id
context.bot_data[user_id] = {}
await update.message.reply_text('Welcome! Please send me the PDF documents you want to process.')
Then we create a function to handle the document processing stage. Every time the user sends in a PDF document, it is indexed into the vector DB.
async def document_handler(update: Update, context: ContextTypes.DEFAULT_TYPE):
"""Handler for receiving PDF documents"""
user_id = update.effective_user.id
# Initialize user-specific data if it doesn't exist
if user_id not in context.bot_data:
context.bot_data[user_id] = {}
document = update.message.document
if document.mime_type == 'application/pdf':
file_id = document.file_id
new_file = await context.bot.get_file(file_id)
file_path = f"{file_id}.pdf"
await new_file.download_to_drive(file_path)
pages = load_and_process_documents(file_path)
if 'vectordb' not in context.bot_data[user_id]:
vectordb = Chroma.from_documents(pages, embeddings)
context.bot_data[user_id]['vectordb'] = vectordb
else:
vectordb = context.bot_data[user_id]['vectordb']
vectordb.add_documents(pages)
await update.message.reply_text('PDF document received and processed. You can now ask questions about the content.')
else:
await update.message.reply_text(f"Unsupported file type: {document.mime_type}. Skipping this file.")
Given a query, this function will create a prompt for the LLM. The prompt will contain the context fetched from the Vector DB, along with the query.
def get_prompt(question, vectordb):
documents = vectordb.similarity_search(question, k=10)
context = '\n'.join(doc.page_content for doc in documents)
prompt = f"""Using only the context below, answer the following question:
context : {context}
question: {question}"""
return prompt
Now we write a function to handle user queries. Note that all the Telegram functions are user specific. This means that for every user there’s a unique vector DB involved (as given by context.bot_data[‘user_id’]). This ensures that the bot can handle concurrent requests from multiple users without mixing up the document information provided by these users. This is because the users’ documents are separately indexed for every user.
async def question_handler(update: Update, context: ContextTypes.DEFAULT_TYPE):
"""Handler for answering questions based on the processed documents"""
user_id = update.effective_user.id
question = update.message.text
vectordb = context.bot_data.get(user_id, {}).get('vectordb')
if vectordb:
prompt = get_prompt(question, vectordb)
response = client.chat(model='mistral:instruct', messages=[
{
'role': 'user',
'content': prompt,
},
])
await context.bot.send_message(chat_id=update.effective_chat.id, text=escape_markdown(response['message']['content']))
else:
await update.message.reply_text('No processed documents found. Please send PDF documents first.')
Then we create the main function to deploy the bot.
def main():
"""Main function to run the bot"""
application = ApplicationBuilder().token(API_TOKEN).build()
# Register command and message handlers
application.add_handler(CommandHandler("start", start))
application.add_handler(MessageHandler(filters.Document.ALL, document_handler))
application.add_handler(MessageHandler(filters.TEXT & ~filters.COMMAND, question_handler))
# Start the bot
application.run_polling()
# application.idle()
if name == 'main':
main()
Results
I sent this Arxiv paper to the bot. It’s called “Don’t Think about Pink Elephants”, and it’s about the fact that certain AI models, when prompted to not think about certain objects, invariably end up thinking about it - which is a flaw in their design, and is very similar to how human brains work.


Voila! We have created a Virtual Professor chatbot that can read and understand scientific papers and respond to your queries. Of course this chatbot can be used for many other use cases, as the LLM (Mistral 7B) it uses is a general purpose LLM and can understand queries and context in a variety of domains other than just EdTech.
Final Note
You can also implement a similar chatbot in Whatsapp, but that process is a little bit complicated as it requires signing up for a Whatsapp Business account, and then selecting a third-party service provider that offers Whatsapp API integration.