Introduction
Imagine a scenario in which computers are capable of comprehending and responding to human natural language, whether we are speaking, writing, or presenting them with graphics. This is the environment that LLaVA-1.5 is contributing to. So when compared to standard language models, which can only be used for text, LLaVA-1.5 stands out from the crowd.
In this blog, we will explore the capabilities of LLaVA-1.5 and discuss its potential impact in the field of artificial intelligence.
Without further ado, let’s get started.
About LLaVA-1.5
LLaVA-1.5 is a novel artificial intelligence (AI) model that can comprehend and produce text based on images. This implies that it has the ability to respond to inquiries about photos and generate descriptions of photographs.
Although LLaVA-1.5 is still in development, it has already mastered a variety of jobs, like providing answers to image-related queries like 'What is the object in the foreground of the image?' and 'How many people are in the image?, or making statements about photographs, like 'A black cat is sitting on a red couch’, etc.
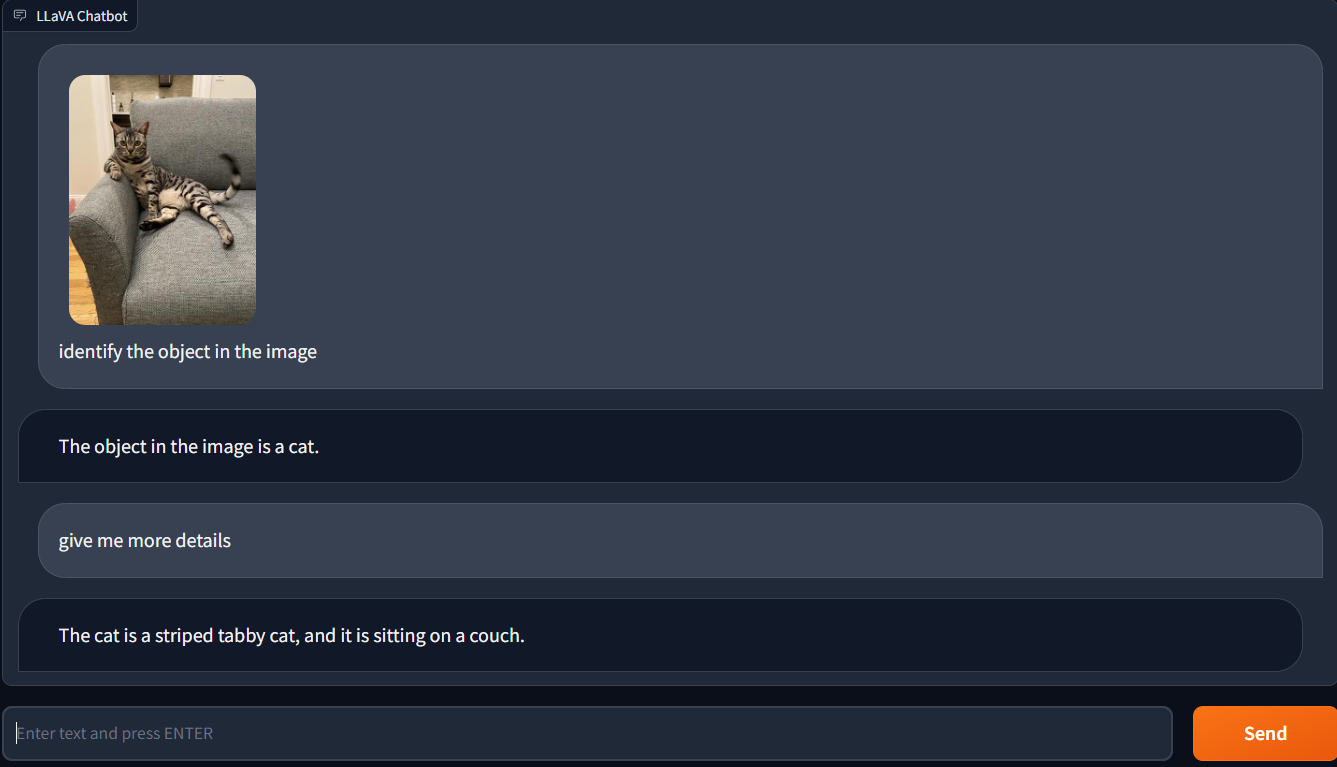
Test #1: Object Classification
Evaluation of LLaVA-1.5's item classification abilities was one of our first tests. I asked the model to name the object in a photograph that featured a cat lounging on a couch. Even though there were other items in the background, LLaVA-1.5 accurately recognized the object as a cat.
This displays the capability of LLaVA-1.5 to classify objects in real-world photos despite noise and distractions. Even the most advanced computer vision models find it difficult to do this task accurately; however LLaVA-1.5 proved successful in doing so.
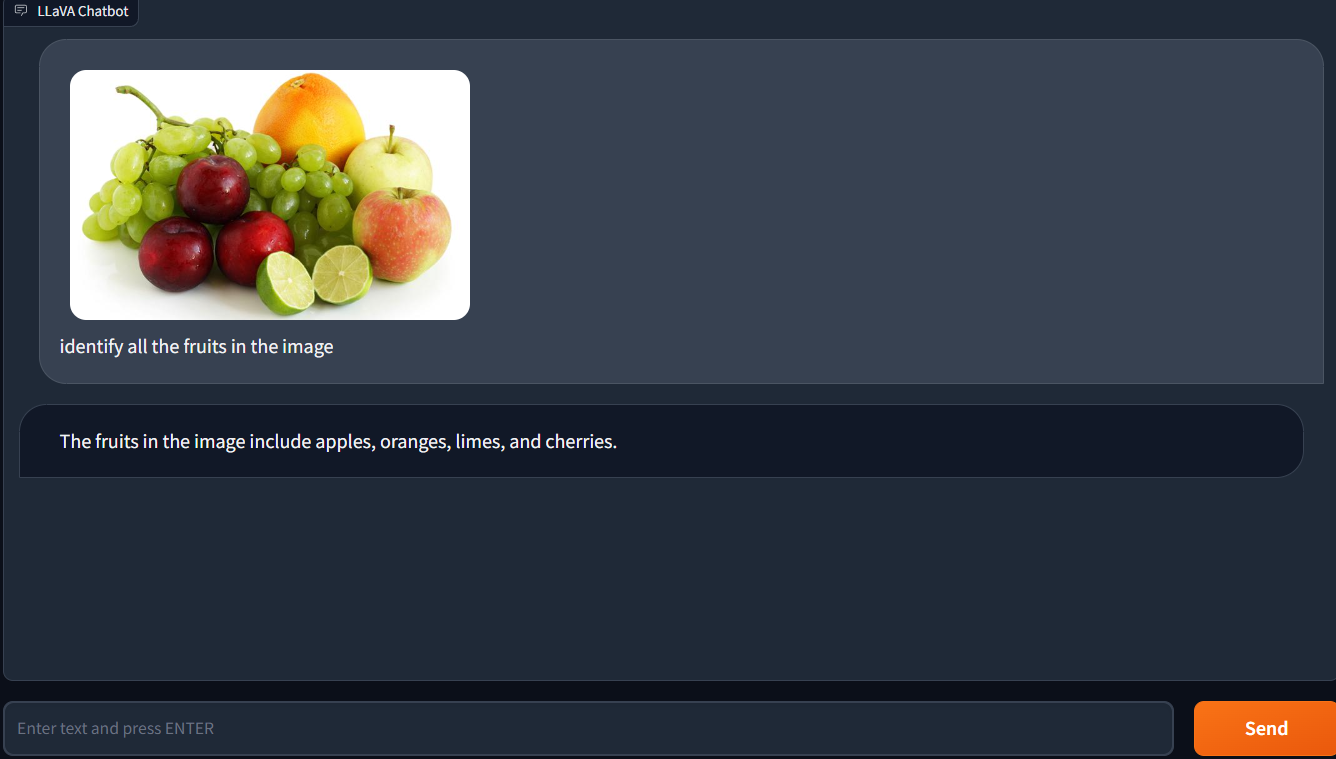
Next, I supplied an image with five fruits. Apples, oranges, limes, and cherries were among the four fruits that LLaVA-1.5 was able to accurately identify. But it couldn't accurately distinguish grapes.
This demonstrates that LLaVA-1.5 is still being developed and that object classification is not yet flawless. Although the image comprised a range of different fruits of various sizes and colours, it is encouraging that LLaVA-1.5 was able to properly identify four out of the five fruits in it.
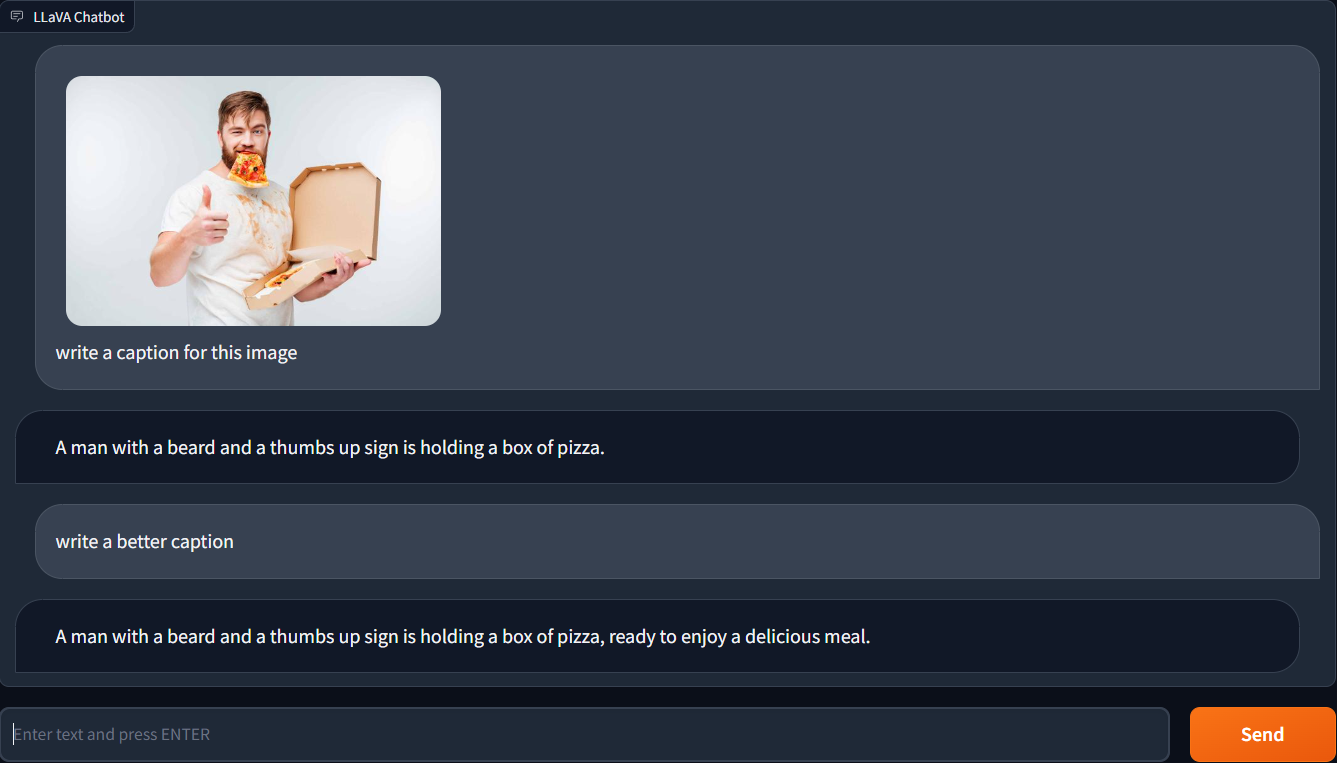
Test #2: Caption Generation
The next thing I did was submit a photo of a man eating pizza and ask LLaVA-1.5 to come up with a caption. The captions it generated did not impress me much. Most of them lacked originality. I was able to come up with two captions that were insightful, but it wasn't particularly original or interesting.
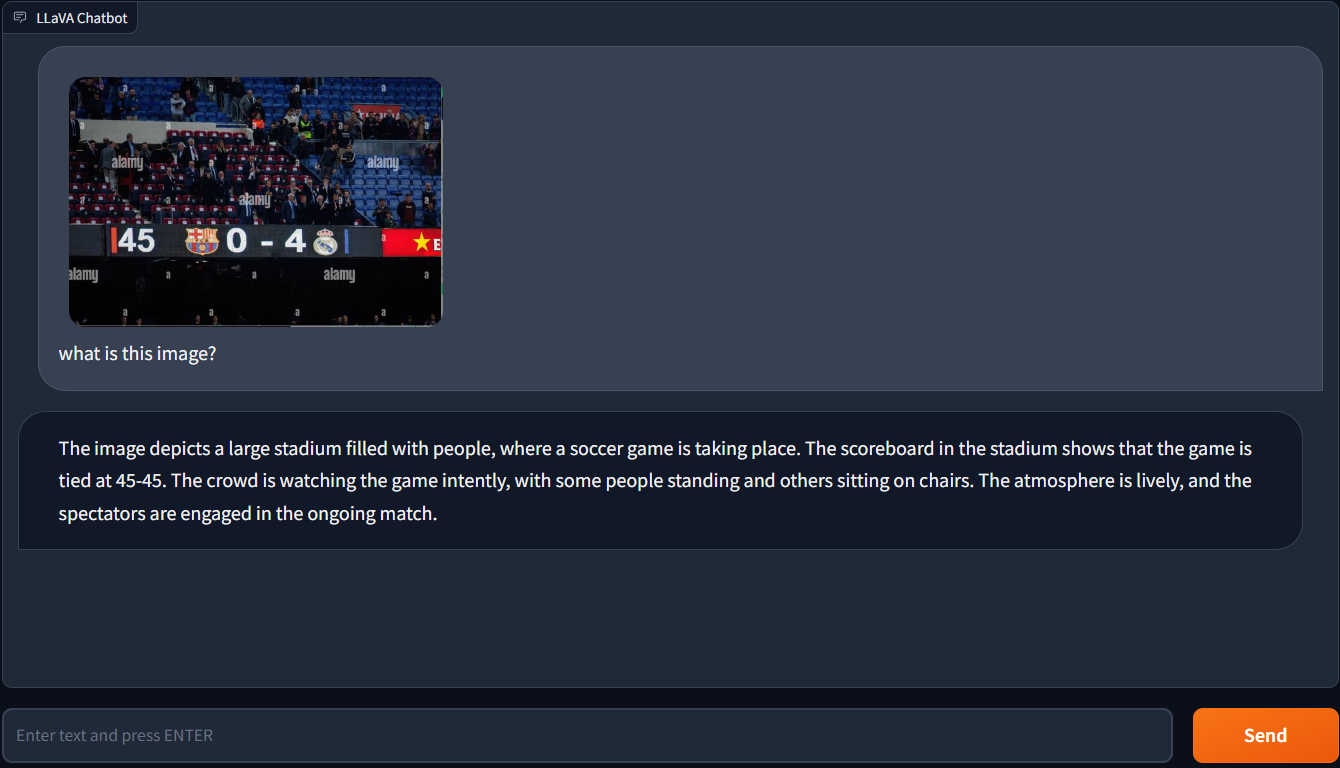
Test #3: Visual Question Answering
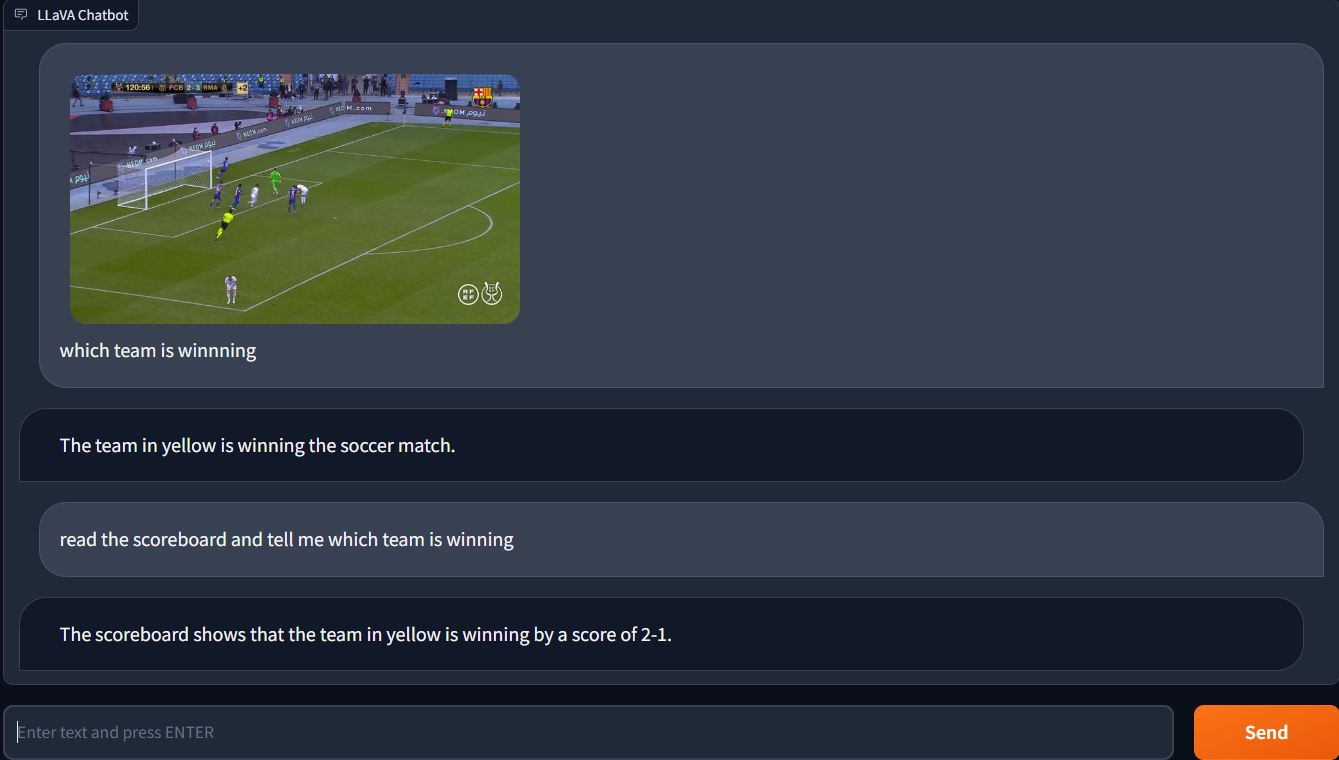
In the next test, I asked LLaVA-1.5 which team was winning while uploading a photo of a football game. The response from LLaVA-1.5, however, was completely meaningless.
This shows that LLaVA-1.5 is still being refined and is not yet ideal at tasks requiring visual question answering. It is crucial to remember that answering visual questions is a difficult task, even for the most advanced computer vision models.
Test #4: Code Generation
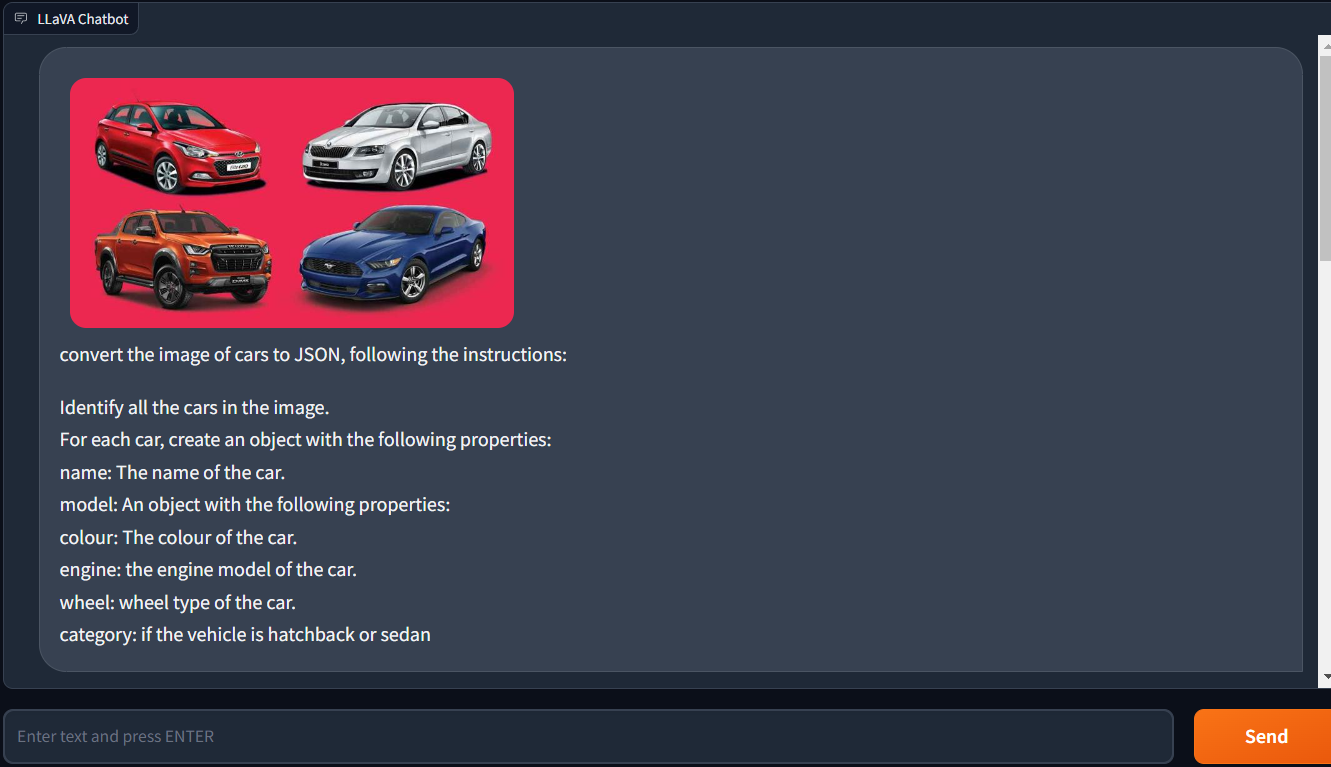
The following test involved uploading an image and instructing LLaVA-1.5 to create a JSON code. The outcomes were outstanding. LLaVA-1.5 was able to correctly produce a JSON code that precisely matched the information we gave it.
This exemplifies how LLaVA-1.5 can produce intricate and detailed JSON code from photos. This is a fairly significant accomplishment considering how frequently JSON is used in a wide range of applications.
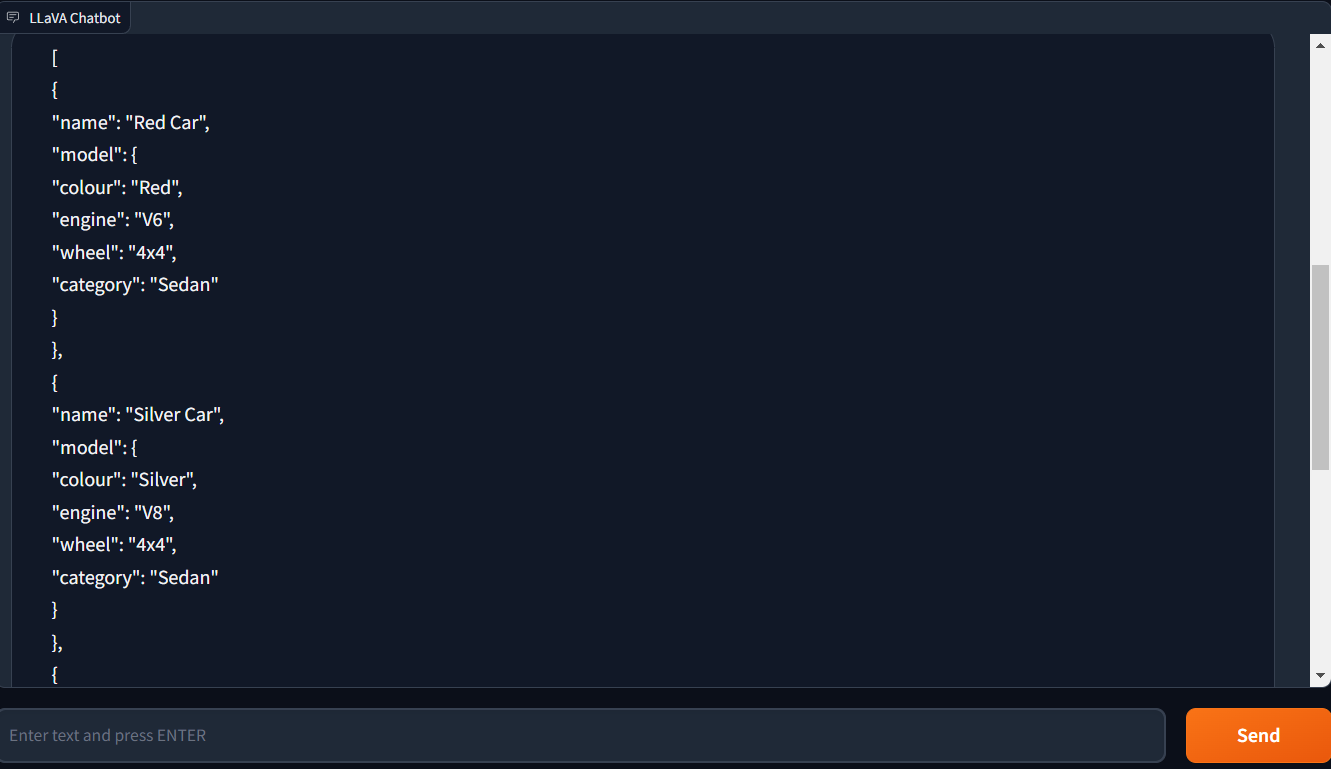
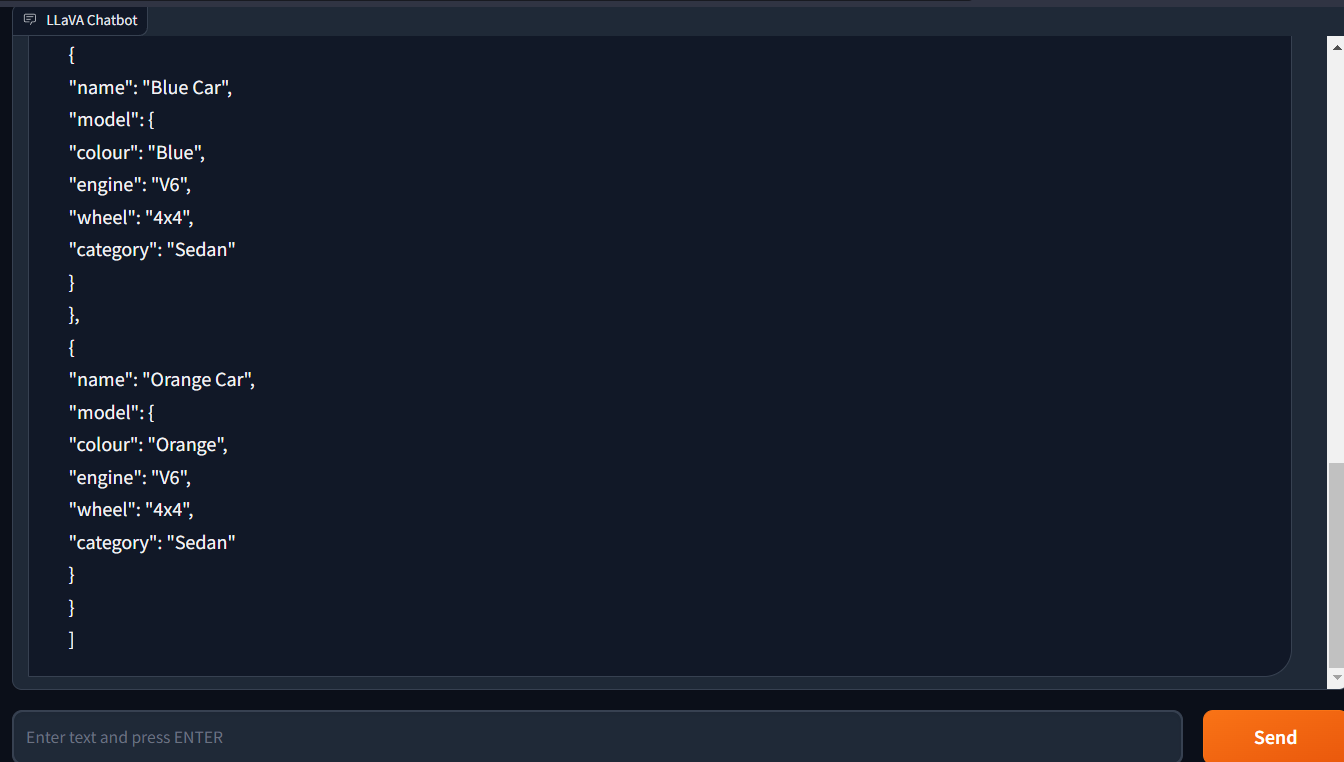
The capacity of LLaVA-1.5 to produce JSON code from photos might be applied in a number of ways, including:
Automating the process of annotating photos with JSON data. The creation of image databases and the training of machine learning models would both benefit greatly from this.
Generating original content. JSON code might be produced from photos using LLaVA-1.5. This could be applied to produce novel forms of interactive experiences and games.
Conclusion
LLaVA-1.5 is a large language model that has the ability to understand and generate both text and images. It is still under development. Even so it has shown remarkable performance on a number of tasks, such as object classification, image captioning, and JSON code generation.
In my study of LLaVA-1.5's performance, I discovered that it could successfully recognize the object in a picture of a cat relaxing on a couch. However, AI found it difficult to come up with clever and interesting captions for a picture of a man eating pizza. Additionally, when shown with a picture of a football game, it was unable to accurately respond to the question 'Which team is winning?'
Despite these drawbacks, LLaVA-1.5 was able to follow my instructions and produce a JSON code from an image. This exemplifies the ability of LLaVA-1.5 to produce intricate data structures from photos.
The way we interact with images and data could be completely changed by LLaVA-1.5, a promising new technology. LLaVA-1.5 has the potential to make a significant impact in a variety of fields, including data science, machine learning, and creative computing.









