This article discusses the advancements in the field of object detection by explaining the latest breakthroughs that happened with the evolution of YOLO. The article covers YOLO architecture and the latest models such as YOLOv8 and YOLONAS, comparing and contrasting the advantages and improvements these techniques have over other approaches.
As AI takes over the software industry and many of its domains, one of the biggest advancements in the field of computer vision has been the advent of YOLO. It has made it possible for every image or video that ever existed to be processed by machines – by the power of machine learning – and offer valuable insights into what the content of the image is. Many softwares and organisations now use YOLO in their AI products.
In this article, we provide a step-by-step guide to understand the technology behind YOLO.
Object Detection in Computer Vision
In the field of computer vision where you can process any image, video – in the form of a live video or recordings, using AI to extract insights from this data – has become very crucial for a lot of applications. One such task defined to extract objects from a given image is called Object Detection. Given an input image, an object detection task will detect the area where an object lies in the image and classify it into a known label.
Traditional approaches used image segmentation and other techniques that often used the understanding of the pixel characteristics of an image. Modern techniques use the power of neural networks to understand the image and the subjects in it. CNNs (Convolutional Neural Networks) are a common neural network technique used in modern-day object detection systems.
Since a video can also be analysed with multiple frames that are images, Object Detection has widespread application in image and video analysis for self-driving cars, traffic monitoring, surveillance, augmented reality, and much more.
What Is YOLO? How Does It work?
YOLO is an algorithm and is an acronym for You Only Look Once. With one look into an image or a video, it can figure out the objects in the input. The foundational principles of YOLO rely on CNNs – by using an FCNN (Fully Convolutional Neural Network) and passing the image through it to perform the predictions.
YOLO outperformed many other algorithms for the object detection task. While other algorithms require multiple scanning procedures, the single scan by YOLO proves to be faster, which makes it highly efficient for real-time image processing. Hence it is popular among products that aim to have state-of-the-art image processing capabilities under their hood.
The working of YOLO can be described with the following steps:
- A neural network model divides the image into regions.
- The model looks at each region and assigns scores (i.e., probabilities) and predict bounding boxes.
- The regions with higher scores are considered to have a detection, and the rest are discarded.
- The score and bounding box belongs to a class, which we now have as the detected object.
How to Use YOLOv8 on E2E Networks
In this section, we can test out how YOLO performs by using some pre-trained weights from the neural network. The cloud platform of our choice will be E2E Networks. The pre-trained weights capture the knowledge gained by the neural network during training and this can be reused in carrying out our detection tasks.
For implementing YOLO, we have to install Ultralytics. Ultralytics has an open-source framework which will help our object detection tasks with YOLO smoother. The Ultralytics project is continuously maintained, and includes releases that contain the latest versions of YOLO.
Excited to test YOLO out? Here are the steps.
Step 1 - Launching E2E Node
- Create an Ubuntu 22.04 GPU node on E2E
- Select a 40GB Machine and hit Create.
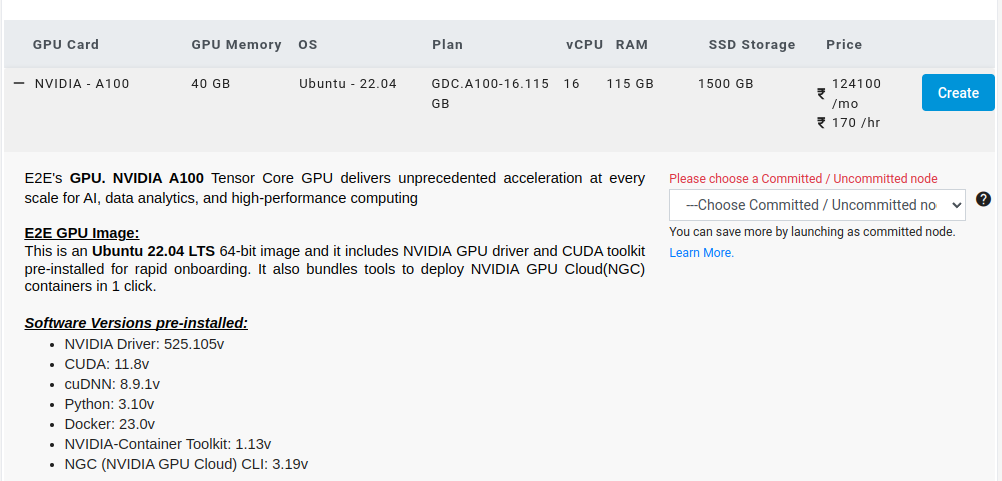
- Check on Enable Backup and hit Create.
- The node will now be created with the following specifications:

- Login to the E2E server using ssh via terminal:
ssh username@IP_address
Step 2 - Installing Ultralytics
Make sure your system has Python and Pip installed.
We can install Ultralytics via Pip.
pip install ultralytics
In case you want the most bleeding edge updates to Ultralytics, you can clone the repo using Git and install from source like this:
git clone https://github.com/ultralytics/ultralytics
cd ultralytics
python setup.py install
Step 3 - Choosing the Pre-trained Models
You could explore any of the pre-trained models by exploring the models page and choosing the model you need for carrying out the experiments. For our experiments, we will be using one of the latest models, the YOLOv8x.
Here is a sample image I used.

Source: Wikipedia
Step 4 - Testing the YOLO Algorithm with Custom Input
Now run the command like this:
yolo predict model=yolov8x.pt source='/path_to_image/image.jpg
Replace the /path_to_image/ directory path with your custom directory path. Note that you can mention the name pre-trained models – and the command will take care of downloading the models for you. In case you have a custom model that you would like to use for inference, mention the model path instead.
You will see an output like this:
Downloading https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8x.pt to 'yolov8x.pt'...
100% 131M/131M [00:02 00:00, 56.2MB/s]
Ultralytics YOLOv8.0.145 🚀 Python-3.10.6 torch-2.0.1+cu118 CPU (Intel Xeon 2.20GHz)
YOLOv8x summary (fused): 268 layers, 68200608 parameters, 0 gradients
image 1/1 /content/bear.jpg: 448x640 1 bear, 3318.5ms
Speed: 5.3ms preprocess, 3318.5ms inference, 2.1ms postprocess per image at shape (1, 3, 448, 640)
Results saved to runs/detect/predict4
The above inference has correctly detected the one bear in the image.
YOLO can predict multiple objects in an image. Let’s try another image like this:
â€

Source: Author
Now we can see the output like this:
Ultralytics YOLOv8.0.145 🚀 Python-3.10.6 torch-2.0.1+cu118 CPU (Intel Xeon 2.20GHz)
YOLOv8x summary (fused): 268 layers, 68200608 parameters, 0 gradients
image 1/1 /content/image.jpg: 640x480 1 bench, 1 cat, 4 handbags, 3570.2ms
Speed: 5.9ms preprocess, 3570.2ms inference, 6.3ms postprocess per image at shape (1, 3, 640, 480)
Results saved to runs/detect/predict5
Training a YOLO Model with Your Custom Data
An Object Detection task can be done for any label that you want if you have the right kind of data. Once the images are collected, the data needs to be annotated with the bounding boxes and the preferred labels before training.
If you want to train your own model from scratch, there are popular datasets available for a wide variety of image datasets for object detection. One of the most used datasets for the task is the COCO (Common Objects in Context) dataset. Let’s take a look at how to train a COCO dataset with the YOLO architecture.
Coco Dataset
The coco dataset comprises hundreds of thousands of images containing information that could be helpful in training and validating many image recognition tasks like object detection, segmentation and captioning. There are around 80 categories and subcategories to perform object classification. This dataset is also used in evaluating YOLO algorithms and their accuracy.
Dataset Configuration
We will use a YAML (Yet Another Markup Language) file to configure details about the dataset. In the Coco.yaml file, we can configure details such as:
- Text files for training and validation and test files that contain information about the respective image paths.
- Image classes and their labels.
- Optional download script to fetch the dataset from the source.
# Ultralytics YOLO 🚀, AGPL-3.0 license
# COCO 2017 dataset http://cocodataset.org by Microsoft
# Example usage: yolo train data=coco.yaml
# parent
# ├── ultralytics
# └── datasets
#   └── coco  ↠downloads here (20.1 GB)
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: ../datasets/coco  # dataset root dir
train: train2017.txt  # train images (relative to 'path') 118287 images
val: val2017.txt  # val images (relative to 'path') 5000 images
test: test-dev2017.txt  # 20288 of 40670 images, submit to https://competitions.codalab.org/competitions/20794
# Classes
names:
 0: person
 1: bicycle
 2: car
 3: motorcycle
 4: airplane
 5: bus
 6: train
 7: truck
 8: boat
 9: traffic light
 10: fire hydrant
 11: stop sign
 12: parking meter
 13: bench
 14: bird
 15: cat
 16: dog
 17: horse
 18: sheep
 19: cow
 20: elephant
 21: bear
 22: zebra
 23: giraffe
 24: backpack
 25: umbrella
 26: handbag
 27: tie
 28: suitcase
 29: frisbee
 30: skis
 31: snowboard
 32: sports ball
 33: kite
 34: baseball bat
 35: baseball glove
 36: skateboard
 37: surfboard
 38: tennis racket
 39: bottle
 40: wine glass
 41: cup
 42: fork
 43: knife
 44: spoon
 45: bowl
 46: banana
 47: apple
 48: sandwich
 49: orange
 50: broccoli
 51: carrot
 52: hot dog
 53: pizza
 54: donut
 55: cake
 56: chair
 57: couch
 58: potted plant
 59: bed
 60: dining table
 61: toilet
 62: tv
 63: laptop
 64: mouse
 65: remote
 66: keyboard
 67: cell phone
 68: microwave
 69: oven
 70: toaster
 71: sink
 72: refrigerator
 73: book
 74: clock
 75: vase
 76: scissors
 77: teddy bear
 78: hair drier
 79: toothbrush
# Download script/URL (optional)
download: |
 from ultralytics.utils.downloads import download
 from pathlib import Path
 # Download labels
 segments = True  # segment or box labels
 dir = Path(yaml['path'])  # dataset root dir
 url = 'https://github.com/ultralytics/yolov5/releases/download/v1.0/'
 urls = [url + ('coco2017labels-segments.zip' if segments else 'coco2017labels.zip')]  # labels
 download(urls, dir=dir.parent)
 # Download data
 urls = ['http://images.cocodataset.org/zips/train2017.zip',  # 19G, 118k images
     'http://images.cocodataset.org/zips/val2017.zip',  # 1G, 5k images
     'http://images.cocodataset.org/zips/test2017.zip']  # 7G, 41k images (optional)
 download(urls, dir=dir / 'images', threads=3)
Training the Model
After setting up the configuration files, you can train the model with the help of the command given below:
yolo train model=yolov8n.pt data=coco8.yaml epochs=3 imgsz=640
You can also specify the hyperparameters such as learning rate, epochs, image size, etc. from the Ultralytics CLI for YOLO. For more information, refer to the CLI docs.
YOLO Nas: Latest Breakthrough in the Object Detection Industry
So far we have had several releases of YOLO, where each release has been outperforming the previous ones in the evaluation metrics. However, with YOLO Nas, there has been a leap in the speed and memory efficiency as well. This model is built from a neural architecture search engine called AutoNac.
The major advantage that comes from using YOLO Nas is the ability to perform quantization with maximum precision, which was a challenge for much of the previous YOLO releases. Quantization is the process to reduce the precision of the weights and biases. This will make the model smaller in size, but also makes it faster and more power-efficient.
The Ultralytics framework introduced YOLO Nas in their releases. Here is an example of how to use YOLO Nas. Keep in mind that this model is still new and under lots of development and testing, so it might not be ideal to use it in production right away.
First, download the pre-trained weights.
And run the below code.
from ultralytics import NAS
model = NAS('yolo_nas_s')
results = model.predict('path/to/image.jpg'')
print(results)
Conclusion
YOLO achieves impressive accuracy and speed with its ability to scan an image just once and leveraging top deep learning methodologies. Using state-of-the-art frameworks like Ultralytics and Darknet that helps train YOLO using neural networks, the task of object detection is made easier. Numerous applications such as autonomous driving, surveillance, and so on have used YOLO for its popularity and ease of creating solutions based on it.









