How Vision RAG Can Organize Unstructured Data in Finance
Unstructured data management in the finance sector presents significant challenges due to the sheer volume and complexity of the data involved. This type of data, which includes emails, social media interactions, contracts, and multimedia files, accounts for over 80% of the data generated in financial services. The difficulties in managing unstructured data can hinder decision-making processes, compliance efforts, and risk management strategies.
Vision RAG (Retrieval-Augmented Generation) is a promising solution for addressing the challenges associated with unstructured data. Vision RAG is a revolutionary approach that combines computer vision, vector databases, and language models to streamline data processing.
This guide demonstrates how to build a Vision RAG system using a cutting-edge tech stack:
- Llama-3.2-11B Vision Preview (via Ollama) for extracting text from images.
- Qdrant Vector Database to store and retrieve information.
- Sentence-Transformers for embedding generation.
- LangChain for seamless integration of components.
- Gradio for a user-friendly interface.
Additionally, the system will run on an E2E GPU Node for enhanced processing power, ensuring smooth execution of the entire pipeline. The workflow involves extracting text from images, storing it in Qdrant for efficient retrieval, and using an LLM to generate clear answers to user queries. Whether it’s automating invoice processing or enhancing document search, this solution is tailored to make finance data management smarter and faster. Let’s dive in!
Let’s Code
Launch an E2E Node
Get started with E2E’s TIR AI/ML Platform here. Here are some screenshots to help you navigate through the platform.
Go to the Nodes option on the left side of the screen and open the dropdown menu. In our case, 100GB will work.
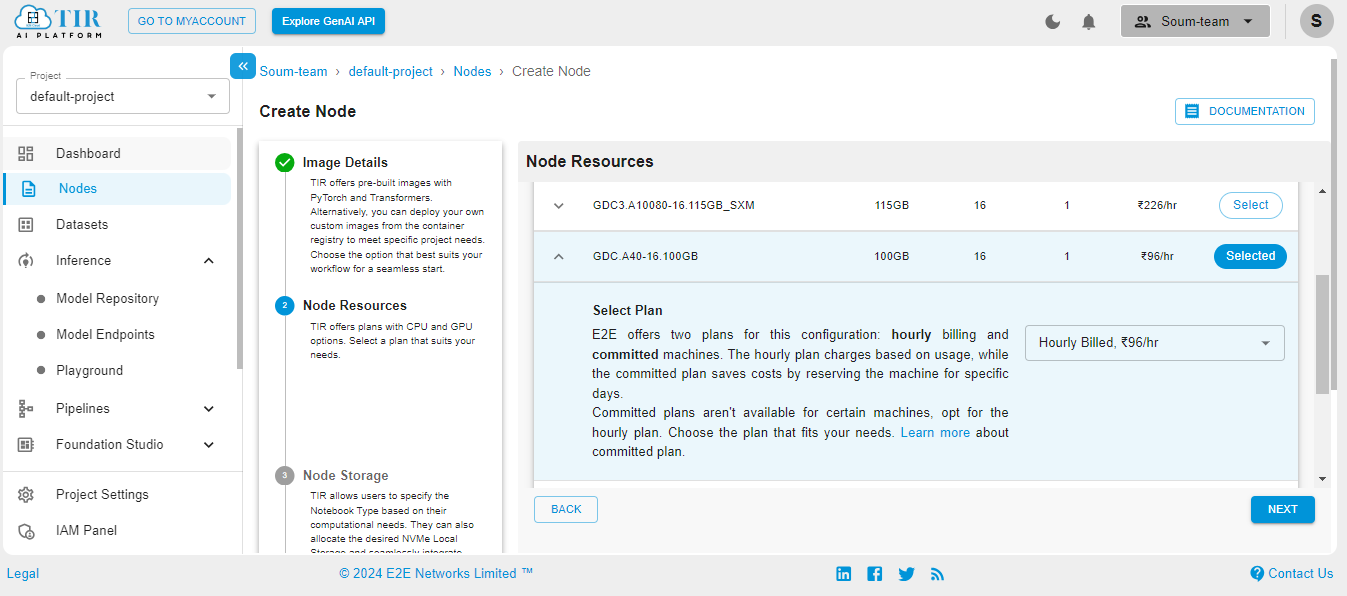
Select the size of your disk as 50GB – it works just fine for our use case. But you might need to increase it if your use case changes.
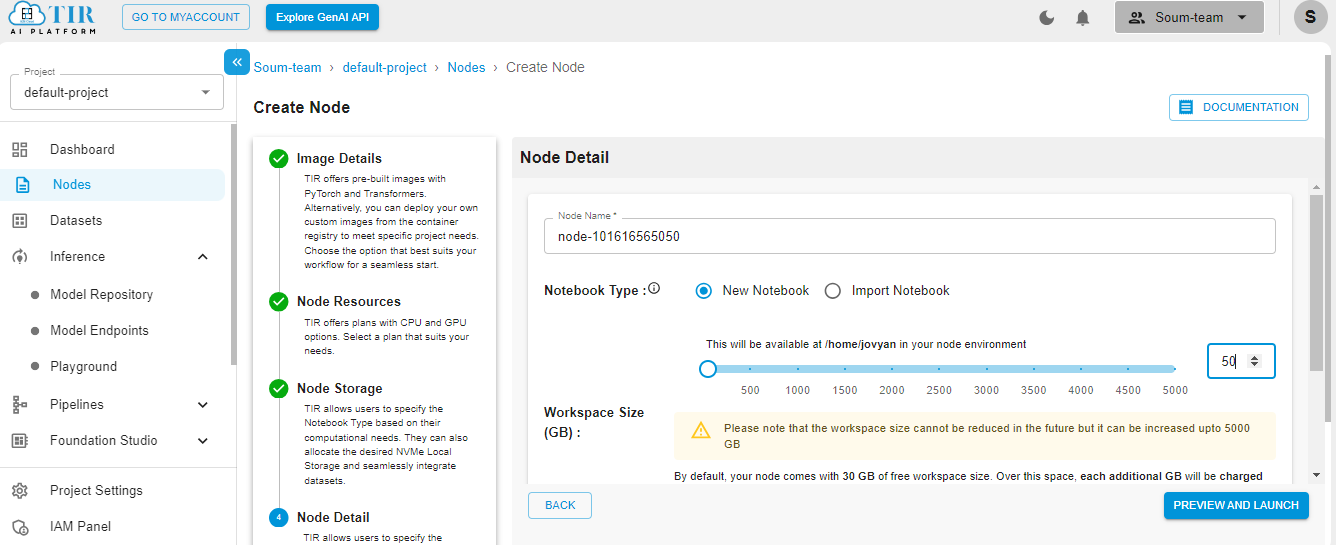
Hit Launch to get started with your E2E Node.
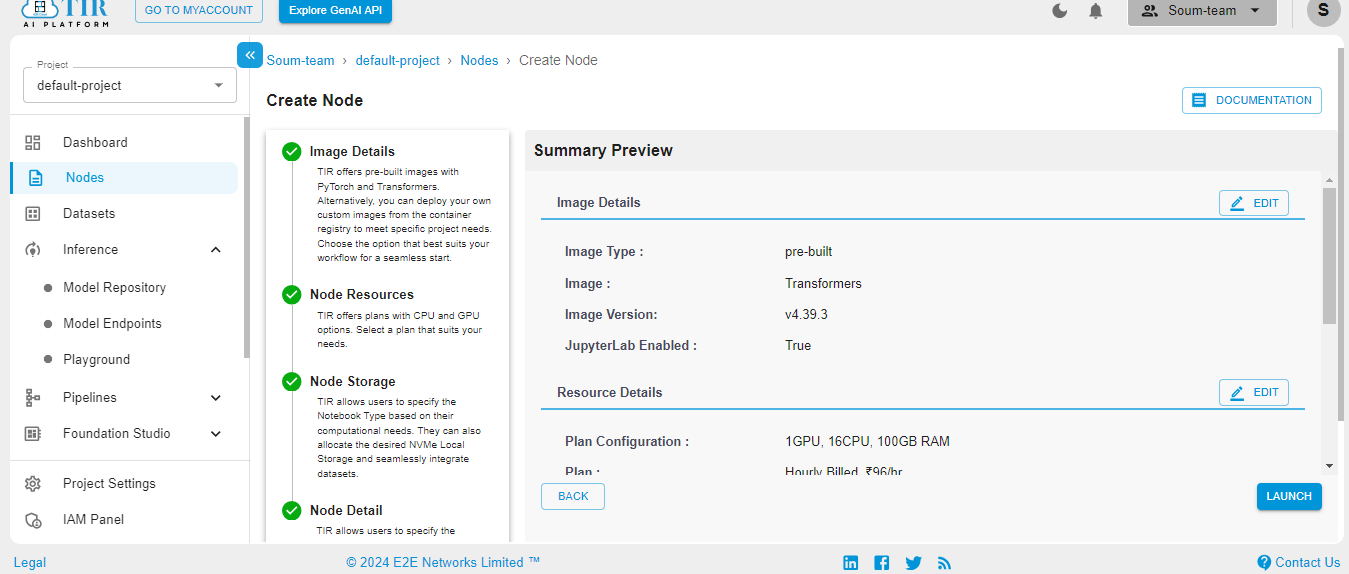
When the Node is ready to be used, it’ll show the Jupyter Lab logo. Hit on the logo to activate your workspace.
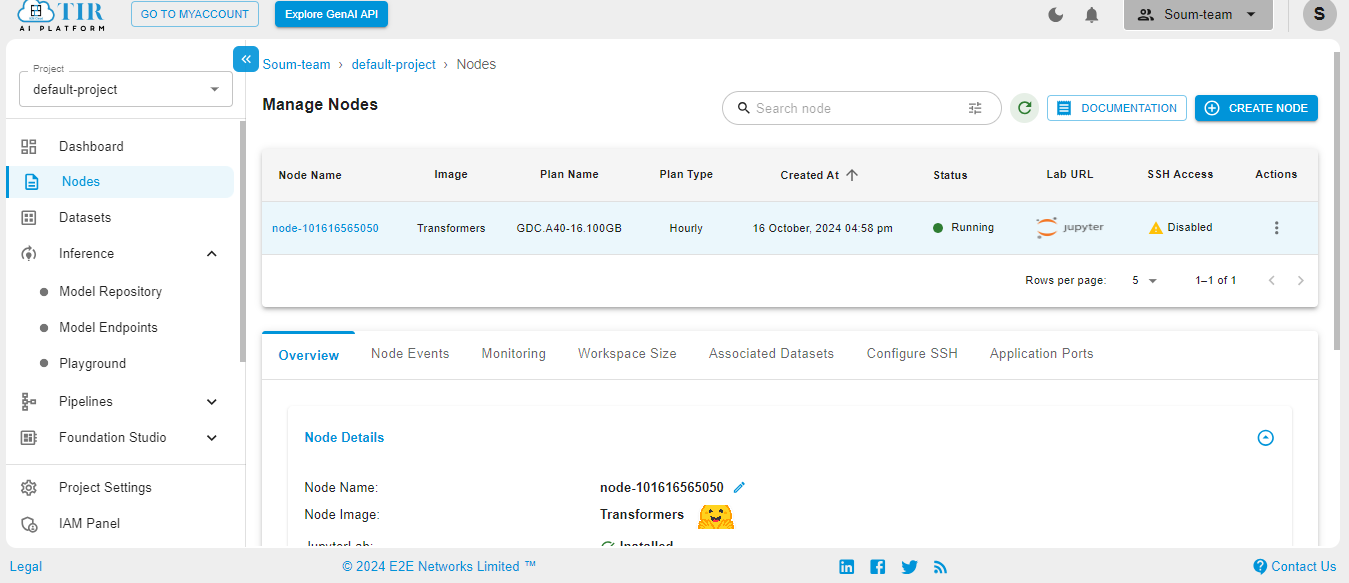
Select the Python3 pykernel, then select the option to get your Jupyter Notebook ready. Now you are ready to start coding.

Set Up the Required Libraries
To build a Vision RAG system, we need specialized libraries for image processing, text embedding, and query handling. Here's a quick rundown of the libraries we're installing:
- qdrant_client: For managing the Qdrant vector database, which stores and retrieves data efficiently using embeddings.
- Gradio: To create an interactive and user-friendly web interface.
- Ollama: We’re leveraging Ollama to interact with advanced vision and language models.
- sentence-transformers: To generate embeddings for text storage in the vector database.
- langchain-community: A framework that simplifies the use of language models in custom workflows.
Run the command below to install these dependencies in your environment:
Import the Essential Libraries and Modules
To build the Vision RAG system, we’ll utilize various libraries and frameworks. Here’s an overview of the key imports and their purposes:
- Ollama:some text
- Provides access to Ollama for interacting with advanced vision and language models.
- QdrantClient and Related Modules:some text
- Enables integration with the Qdrant vector database to store and query embeddings.
- PointStruct, VectorParams, and Distance help define the structure and configuration of the stored vectors.
- uuid:some text
- Used to generate unique IDs for each data point stored in the vector database.
- SentenceTransformer:some text
- A pre-trained model from the Hugging Face library, used to create high-quality text embeddings.
- HuggingFaceEmbeddings:some text
- A wrapper for generating embeddings with models from Hugging Face, simplifying integration with tools like LangChain.
- huggingface_hub.login:some text
- Provides authentication to access models or resources hosted on Hugging Face.
- gradio:some text
- Used to build an interactive web interface for user inputs (image URLs, queries) and to display responses.
These imports form the backbone of our Vision RAG system, connecting its core components—image processing, vector storage, and query handling—seamlessly.
Initialize the Core Components
This section sets up the key tools required for building the Vision RAG system. Here's a breakdown of the initialization:
- Qdrant Client:some text
- The QdrantClient is configured with a URL and API key to connect to your cloud-based Qdrant instance.
- This enables seamless storage and retrieval of text embeddings.
- Ollama Client:some text
- The Ollama client is initialized with a key for accessing advanced vision and language capabilities.
- This is critical for querying the vision model to extract text from images.
- Hugging Face Authentication:some text
- The login function authenticates your environment with a Hugging Face token to access models and resources hosted on their platform.
- Embedding Model:some text
- The SentenceTransformer model, all-mpnet-base-v2, is loaded to generate high-quality text embeddings.
- The device is set to cpu, ensuring compatibility with your current system setup.
These initializations ensure the Vision RAG system is connected to the necessary APIs, vector database, and embedding tools, forming the foundation for further functionality.
Generate the Text Embeddings
The generate_embeddings function transforms raw text into high-dimensional vector representations (embeddings). These embeddings are crucial for storing and retrieving relevant chunks of text in the Qdrant vector database.
Code
Store the Text Chunks in Qdrant
The store_chunks_in_qdrant function handles the process of storing text embeddings in the Qdrant vector database. This ensures the extracted and embedded text can be efficiently retrieved later for answering user queries.
How It Works
- Input: Accepts a list of text chunks (chunks) for storage.
- Collection Setup:some text
- Checks if the "FINANCE-RAG" collection exists in Qdrant.
- If not, create it with a vector size of 768 (matching the embedding dimension) and cosine similarity as the distance metric.
- Embedding and Metadata:some text
- Generates embeddings for each chunk using the generate_embeddings function.
- Assigns metadata (like chunk text and a document_id) to each point for traceability.
- Generates a unique identifier (uuid) for every chunk.
- Storage:some text
- Uses the upsert method to store or update points in the Qdrant collection.
Why It’s Important
This function is the backbone of the retrieval system. By storing text chunks as embeddings, it ensures:
- Fast similarity-based search for queries.
- Contextual and relevant responses from the RAG system.
Query Qdrant for the Relevant Results
The query_qdrant function is responsible for searching the Qdrant vector database using a user-provided query. It converts the query into an embedding and then performs a similarity search within the specified collection, returning the most relevant results.
How It Works
- Input:some text
- The user provides a query string (query) for the search.
- Optionally, specify the collection name and the number of results to return (defaults to 3).
- Query Processing:some text
- The function generates an embedding of the query using the generate_embeddings function.
- Search:some text
- The function performs a vector search in the specified Qdrant collection (default is "FINANCE-RAG") and retrieves the top results based on similarity.
- Output:some text
- Returns the top search results as a list of matching entries.
- If no results are found or an error occurs, an empty list is returned.
Why It’s Important
This function is essential for retrieving contextually relevant information from the Qdrant database. By using semantic search, it ensures that the system fetches the most relevant text chunks to answer user queries, thereby improving the accuracy and relevance of the final responses.
Process the Vision-Based Queries
The process_vision_query function handles the task of sending a vision-based query to Ollama, which processes both text and image inputs. This function is essential for integrating vision and language models, enabling the system to analyze and respond to queries involving images.
How It Works
- Input:some text
- The function takes an image_url (the location of the image to analyze) and a text_prompt (the instruction for what to extract from the image) as inputs.
- Ollama Query:some text
- The function uses the Ollama chat.completions.create() method to send a request to the llama-3.2-11b-vision-preview model. The request includes both the image URL and the text prompt.
- The model processes the image based on the provided text prompt and generates a response.
- Response Handling:some text
- The function captures the generated response, which contains the text extracted or generated from the image, and returns it.
- Error Handling:some text
- If any issues arise during processing, the function catches the exception and returns None.
Why It’s Important
This function bridges the gap between visual data (images) and textual processing, enabling the system to interpret and extract meaningful information from images. It is key for tasks where both visual and text input are involved, such as analyzing financial reports, invoices, or other document images in the finance domain.
Generate Human-Friendly Answers Based on Context
The generate_answer function is responsible for producing human-readable answers to user queries by leveraging the context provided from previous searches or image analysis. This function combines relevant pieces of information and generates a response using a language model.
How It Works
- Input:some text
- The function accepts a user query (the question the user is asking) and a context (a list of text strings containing relevant information) as input.
- Context Preparation:some text
- The context is combined into a single string by joining all the text chunks, which helps to provide a broader view for the language model.
- Message Formation:some text
- The combined context is added to the model's input along with the user's query in a structured format. This helps the model understand the relationship between the query and the provided context.
- Response Generation:some text
- Using the Ollama client, a request is sent to the language model (in this case, llama-3.2-3b-preview) to generate a response. The model then produces a human-like answer that integrates the context with the query.
- Output:some text
- The function extracts the generated answer and returns it. If an error occurs, it returns None.
Why It’s Important
This function enables the system to answer complex queries by using context from previous operations (such as image text extraction or vector search results). It plays a critical role in ensuring that the AI provides accurate, meaningful, and coherent answers to user queries, making the system more interactive and user-friendly.
Control Flow for Vision-Based Query and Answer Generation
The control function orchestrates the entire process of handling a vision-based query and generating a relevant answer based on the extracted information. It integrates various components such as vision processing, querying the vector database, and generating answers from the context. This function is the backbone of the system, ensuring seamless flow from image processing to generating a coherent response.
How It Works
- Input:some text
- The function accepts an image_url (the link to the image to be analyzed) and a query (the user’s question related to the image content).
- Process Vision Query:some text
- The function first uses the process_vision_query function to extract text from the image. It sends a request to the Ollama vision model, specifying the image and the prompt to extract text.
- Error Handling:some text
- If the vision model returns an error, it is captured and returned as a response.
- Text Chunking and Storage:some text
- If the vision response is successful, the extracted content is split into chunks (512 characters each). These chunks are then stored in the Qdrant vector database for future reference and querying.
- Querying Qdrant:some text
- The function queries the Qdrant database to retrieve relevant chunks of text that match the user’s query. These chunks serve as context for answering the query.
- Answer Generation:some text
- The function generates a final response to the user’s query by using the generate_answer function, which combines the query with the retrieved context.
- Output:some text
- The function returns the generated answer along with the content extracted from the image, providing a full context to the user.
Why It’s Important
This function ties together all the components of the system: vision processing, vector search, and natural language generation. It allows the system to respond accurately to user queries based on both visual and textual information, making it highly useful for tasks in the finance domain, where documents and images are key sources of data.
Build a Gradio Interface for Vision RAG System
The gradio_interface function and its integration with Gradio provide an interactive web-based interface for users to interact with the Vision RAG System. This interface allows users to input an image URL and a query related to the image, and then the system processes this input and provides a relevant answer using the Vision RAG architecture.
How It Works
- User Input: The interface consists of two textboxes for user input:some text
- Image URL Input: Users provide the URL of the image they want to analyze.
- Query Input: Users type in a query related to the image content.
- Processing: When the user clicks the Submit button, the gradio_interface function is triggered. This function calls the control function, which:some text
- Extracts the relevant text from the image.
- Queries the Qdrant database for the most relevant chunks of text.
- Generates an answer using the language model based on the query and the retrieved context.
- Output: After processing, the system outputs:some text
- LLM Response: The generated response to the user's query based on the extracted image content.
- Extracted Text: The raw text extracted from the image, providing transparency into the image analysis process.
- Launch: The interface is launched with demo.launch(share=True), making it accessible via a public URL for easy sharing.
Why It’s Important
This Gradio interface makes the Vision RAG System accessible and user-friendly. Instead of dealing with backend logic directly, users can interact with a simple web interface, input their queries, and receive answers based on images in an intuitive manner. It helps users to extract insights from documents and images without the need for technical expertise.
Results
1)
Image URL: https://i.ytimg.com/vi/qJeBwBypXoE/hq720.jpg?sqp=-oaymwEhCK4FEIIDSFryq4qpAxMIARUAAAAAGAElAADIQj0AgKJD&rs=AOn4CLA94SS6FTy47lCHgtmLSmCBjXracg
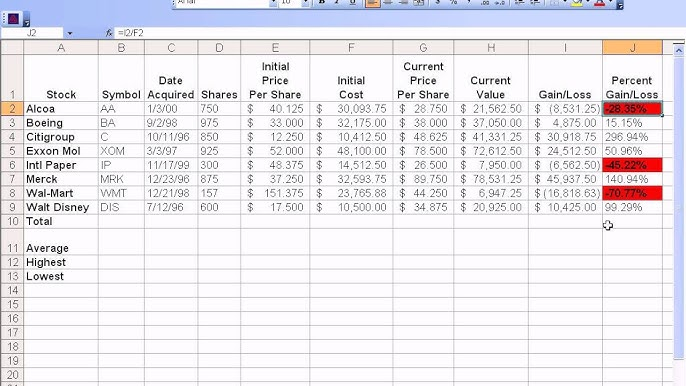
Text Extracted:
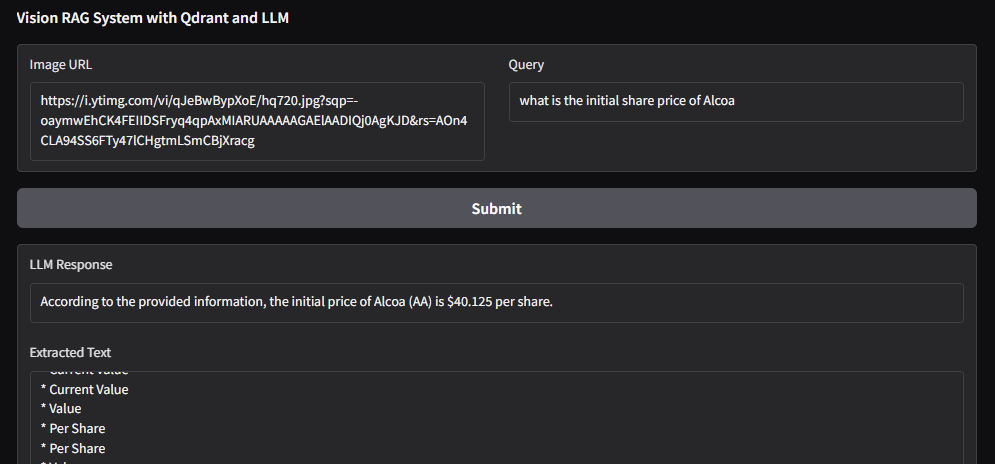
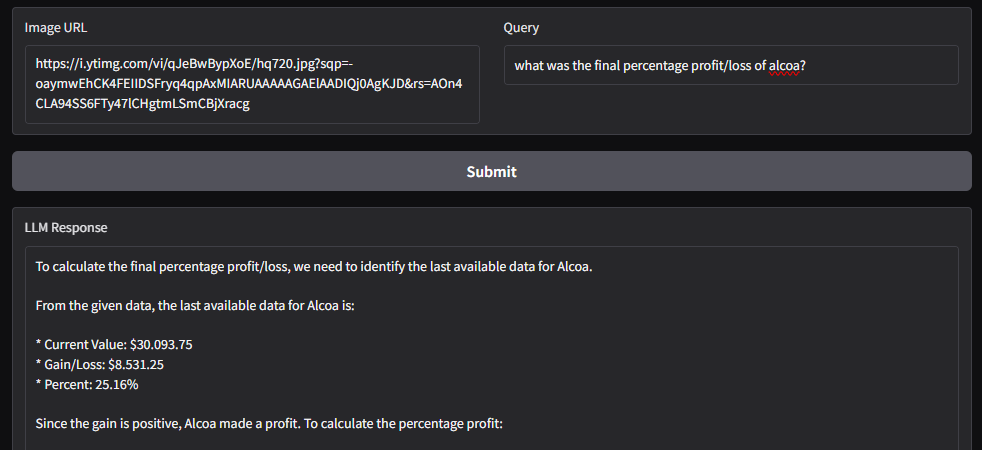
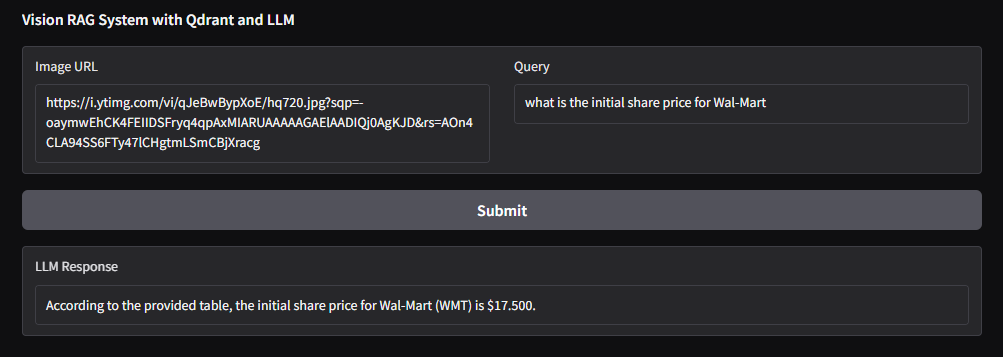
2)
Image URL: https://www.business-case-analysis.com/images/accounting/balance-sheet-brief2x.jpg
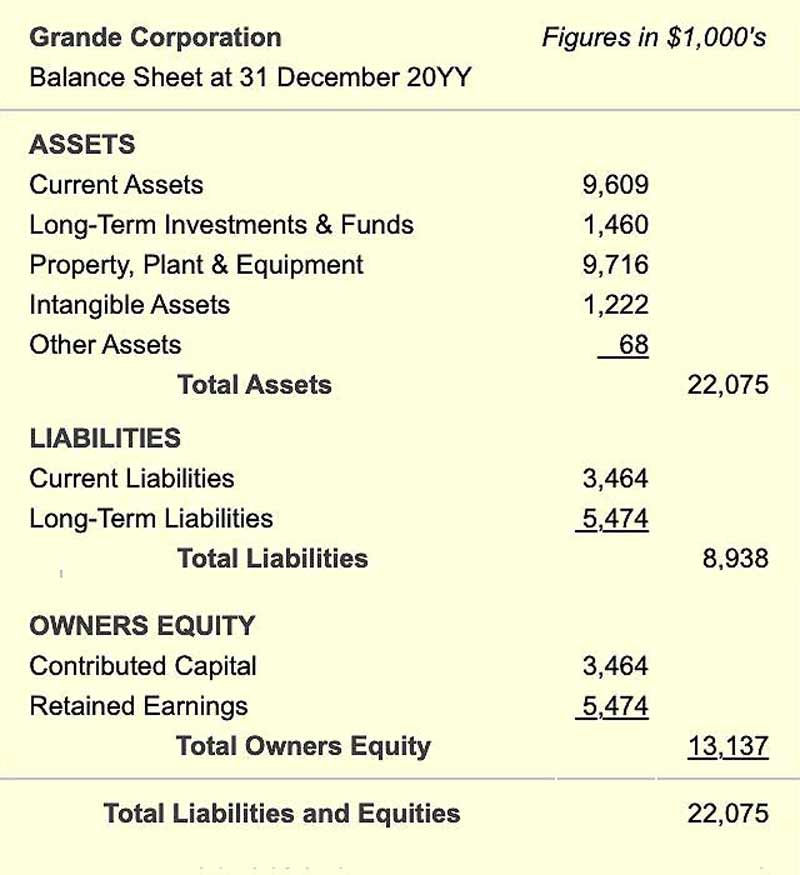
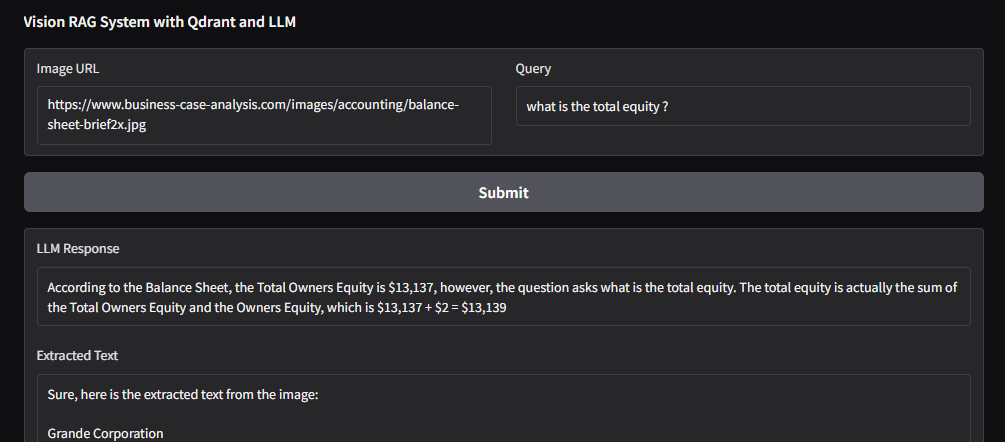
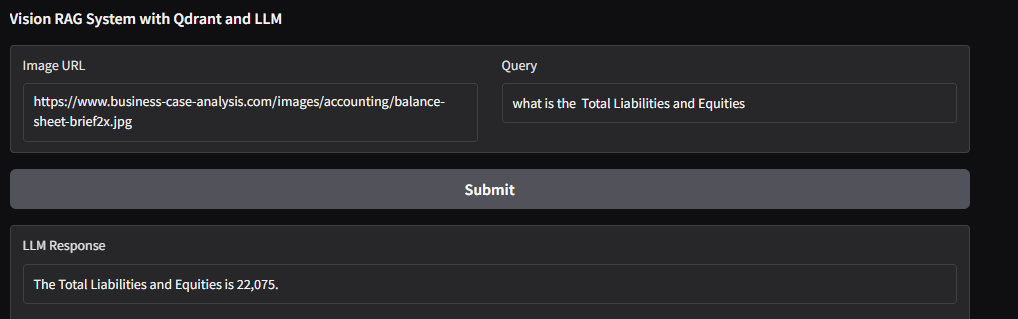
Summary
This guide has shown how to build a vision RAG system for unstructured financial data, but the real power lies in the cloud infrastructure you choose. That’s where E2E Cloud shines.
- Unbeatable GPU Performance: Access top-tier GPUs like H200, H100, and A100—ideal for state-of-the-art AI and big data projects.
- India’s Best Price-to-Performance Cloud: Whether you’re a developer, data scientist, or AI enthusiast, E2E Cloud delivers affordable, high-performance solutions tailored to your needs.
Get Started with E2E Cloud Today
Ready to supercharge your projects with cutting-edge GPU technology?
- Launch a cloud GPU node tailored to your project needs.
E2E Cloud is your partner for bringing ambitious ideas to life, offering unmatched speed, efficiency, and scalability. Don’t wait—start your journey today and harness the power of GPUs to elevate your projects.