Understanding ColPali: An Advanced Document Retrieval Model Using Vision Language Technology
ColPali is an advanced document retrieval model that leverages Vision Language Models (VLMs) to enhance the retrieval of information from complex documents, particularly PDFs. Unlike traditional Optical Character Recognition (OCR) systems, which extract text from images in a segmented manner, ColPali processes entire document pages as images, capturing both textual and visual elements in a unified embedding space. This approach significantly improves the efficiency and accuracy of document retrieval by eliminating the need for multiple preprocessing steps like text extraction and layout detection.
Key Features of ColPali
- Unified Embedding Space: ColPali encodes document images directly into a multi-vector representation, allowing it to maintain the full context of the document, which can be crucial for understanding complex layouts that include tables, diagrams, and images.
- Enhanced Contextual Understanding: By analyzing the entire layout rather than isolated text points, ColPali can better interpret how different elements of a document relate to one another, leading to more accurate retrieval results.
- Dynamic Retrieval-Augmented Generation (RAG): ColPali integrates seamlessly into RAG frameworks, enabling real-time information retrieval that is contextually rich and relevant to user queries.
- Efficiency Gains: The model simplifies the indexing process and maintains low query latency, making it suitable for applications requiring rapid responses.
ColPali is particularly useful in scenarios where documents contain rich visual content alongside text, such as academic papers, technical manuals, or reports. Its ability to analyze and retrieve information from these multimodal documents makes it a powerful tool for organizations dealing with complex data sets.
Delivering Customer Support with a Multimodal AI Assistant: A Step-by-Step Guide
Today’s customer support demands more than just text-based query handling. Modern customers often seek assistance using various formats, including images, PDFs, and other media types. Addressing these diverse queries requires an advanced system capable of understanding and processing both visual and textual information seamlessly.
In this blog, we’ll guide you through creating a powerful multimodal AI assistant using the E2E platform node. This innovative system combines two cutting-edge models—ColPali for multimodal retrieval and LLaVA for multimodal understanding and response generation. By integrating these models within the E2E framework, your AI assistant will be equipped to index, search, and generate responses based on both text and images, enabling businesses to deliver personalized and highly accurate customer support.
We’ll walk you through the entire process, step by step. From loading the models and indexing files to performing advanced question-and-answer tasks, this modular approach ensures flexibility and scalability. By the end, you’ll have a robust AI assistant capable of addressing a wide array of customer inquiries, delivering timely and contextually relevant responses by combining visual and textual data. Let’s dive in and explore how you can transform customer support with a multimodal AI assistant!
Before we start, a short introduction to LLaVA: LLaVA v1.5-7B-4096 is a state-of-the-art vision-language model engineered to seamlessly integrate image understanding with natural language processing. Boasting a powerful 7-billion-parameter architecture, this model excels in tasks such as visual question answering, image-to-text generation, and multimodal dialogue. With the ability to process high-resolution images and handle extended text inputs of up to 4096 tokens, LLaVA delivers a comprehensive understanding of both visual and textual contexts. Its capabilities make it an ideal solution for complex applications like detailed document analysis, image captioning, and building interactive AI assistants.
Designed to empower industries such as education, customer support, and data-driven analytics, LLaVA v1.5-7B-4096 offers developers the tools to create smarter, more context-aware systems. Whether it’s analyzing intricate documents, generating accurate image-based descriptions, or facilitating intelligent interactions, LLaVA sets a new standard for multimodal AI innovation.

Launching the E2E Node
Get started with E2E AI / ML Platform here. Here are some screenshots to help you navigate through the platform.
Go to the Nodes option on the left side of the screen and open the dropdown menu. In our case, 100GB will work.
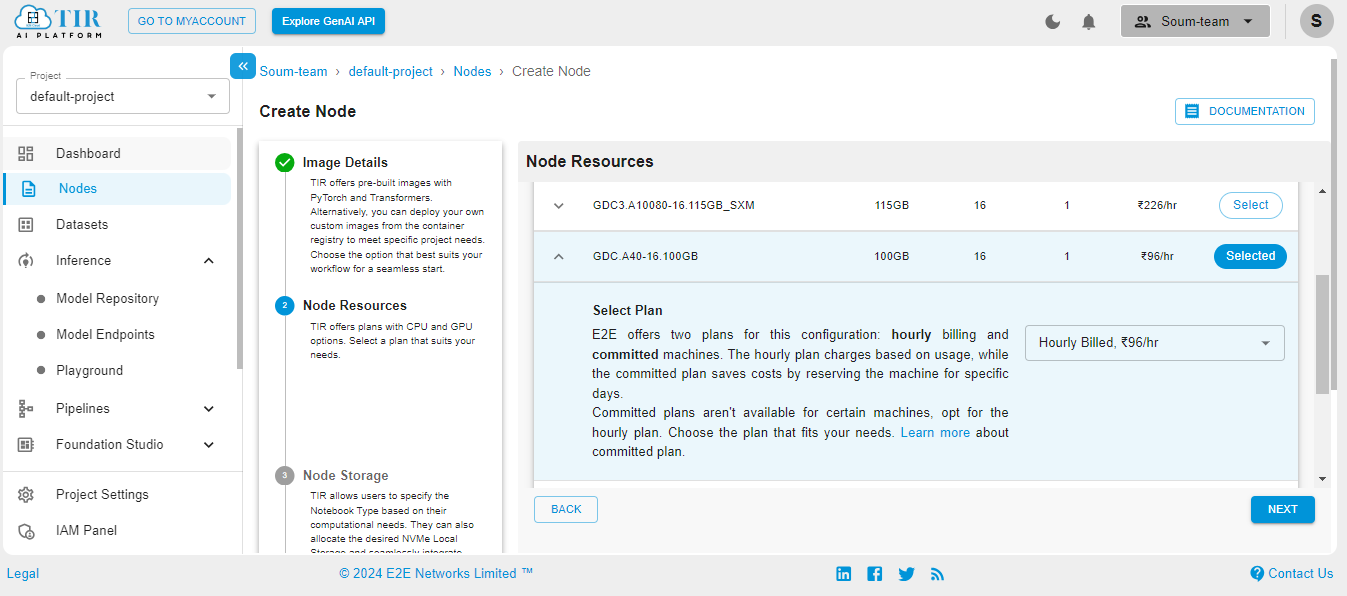
Select the size of your disk as 50GB – it works just fine for our use case. But you might need to increase it if your use case changes.
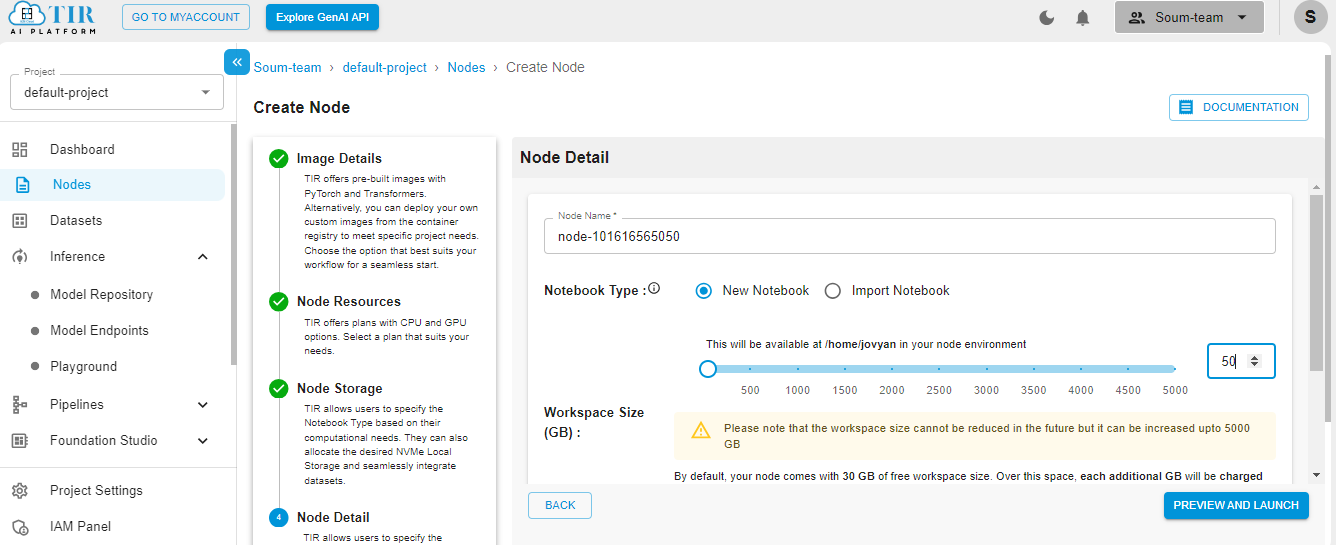
Hit Launch to get started with your E2E Node.
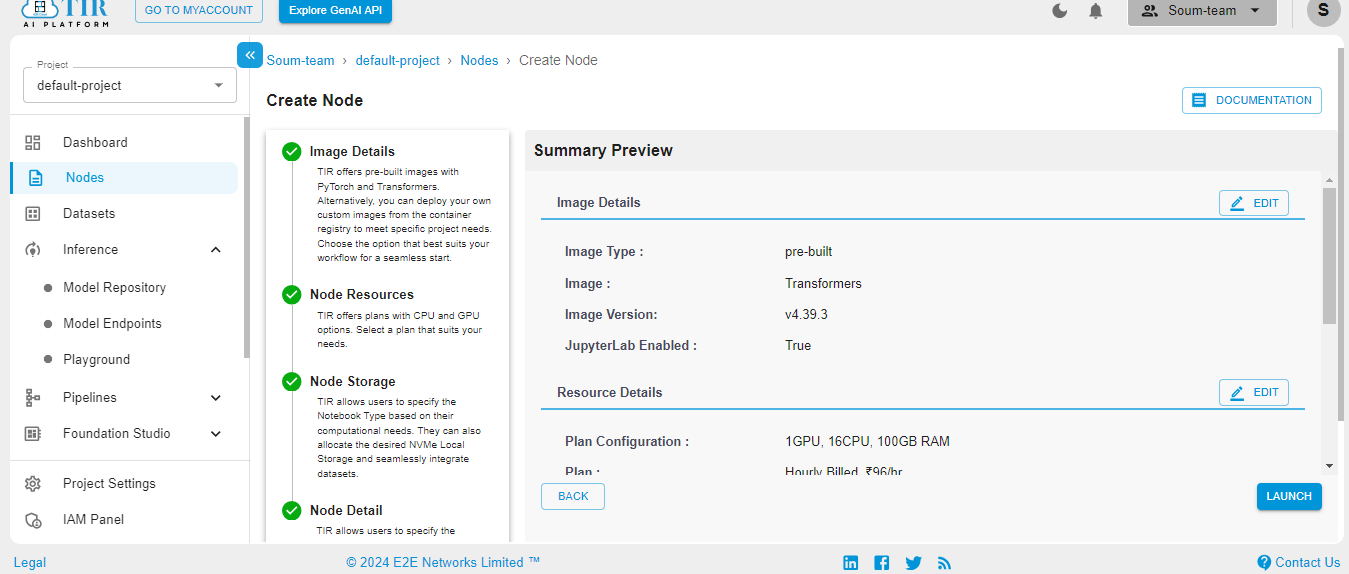
When the Node is ready to be used, it’ll show the Jupyter Lab logo. Hit on the logo to activate your workspace.
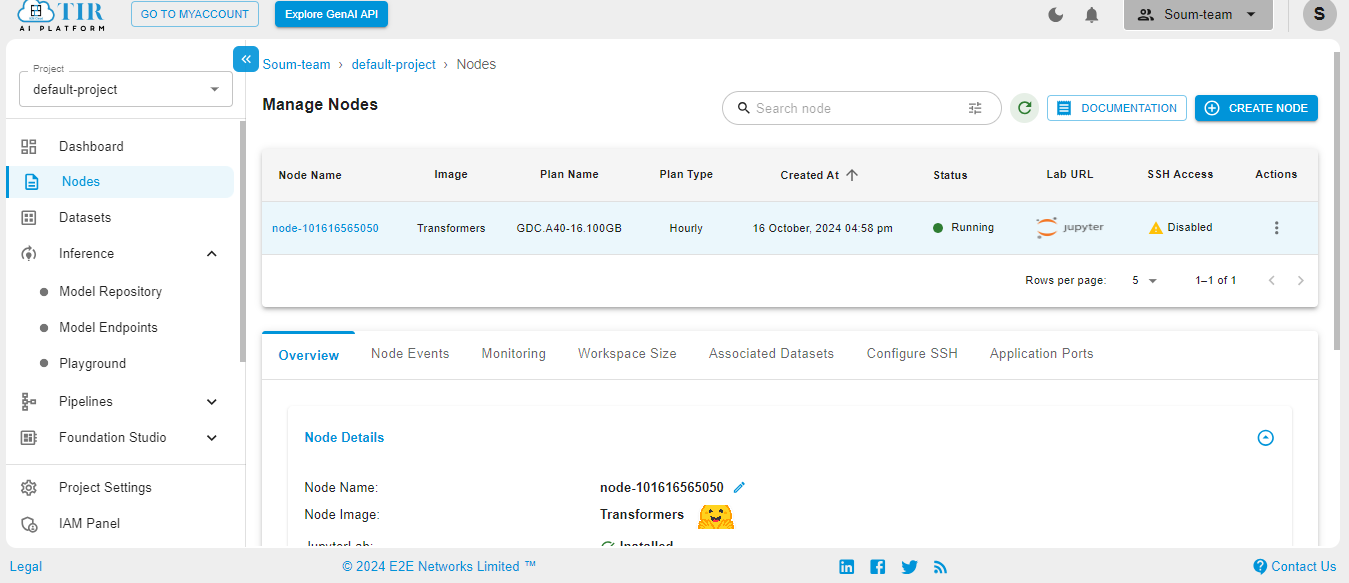
Select the Python3 pykernel, then select the option to get your Jupyter Notebook ready. Now you are ready to start coding.

Setting Up the Environment
This step focuses on installing the essential dependencies needed to build the multimodal RAG (Retrieval-Augmented Generation) pipeline. Here’s a breakdown of the key tools:
- byaldi: Simplifies indexing and retrieval, enabling seamless integration with the ColPali model.
- pdf2image: Converts PDF pages into images, making them accessible for visual processing tasks.
- flash_attn: Optimizes attention mechanisms for faster computations, improving performance during inference.
- LLaVA Integration: Facilitates interaction with the LLaVA model, enabling sophisticated multimodal tasks.
- poppler-utils: Provides crucial utilities for converting PDF files to images, ensuring efficient PDF-to-image workflows.
To set up your environment with all the necessary tools for efficient document indexing and querying, use the following one-liner command:
This command ensures your environment is fully equipped to handle both textual and visual data, laying the groundwork for a robust multimodal AI assistant.
Importing Essential Libraries for the Multimodal RAG Pipeline
In this section, we import the critical libraries required to build and run the multimodal RAG (Retrieval-Augmented Generation) pipeline. Each library serves a specific function within the workflow:
- byaldi: Manages the multimodal RAG model and facilitates document indexing and retrieval with ColPali.
- Llava-v1.5-7b-4096-preview & AutoProcessor: From the Transformers library, these components enable the use of the LLaVA v1.5-7B-4096-preview Vision-Language Model to process both text and images seamlessly.
- pdf2image: Converts PDF pages into images, allowing the model to process visual content efficiently.
- base64: Encodes images into a format that the model can interpret as input.
- os: Handles file path manipulations and manages environment variables for streamlined file management.
- torch: Powers model inference, providing GPU acceleration and efficient computation capabilities for large-scale processing tasks.
These imports form the foundation for integrating and processing text and visual data seamlessly in the pipeline. Here's a sample code snippet to include these imports:
By leveraging these libraries, the multimodal pipeline is equipped to handle both textual and visual information, ensuring robust and accurate responses in various scenarios.
Module: Loading Pretrained Models for Multimodal AI
In this step, we load the essential models needed to build a robust multimodal AI assistant. These include two key models—ColPali and LLaVA—that empower the system to handle both image-based and text-based customer queries effectively.
1. ColPali Model for Retrieval-Augmented Generation (RAG)
The load_colipali_rag function loads the pretrained ColPali model, which is specifically designed for Retrieval-Augmented Generation (RAG). This model enables the system to:
- Retrieve relevant information from a knowledge base.
- Generate context-aware answers by combining text and visual data.
ColPali seamlessly integrates vision and language, allowing the assistant to provide accurate and comprehensive responses to customer queries that involve both textual and visual elements.
2. LLaVA Model for Visual-Linguistic Tasks
The load_llava_model function initializes the LLaVA model, which excels in handling tasks that involve visual inputs. This includes:
- Generating natural language responses from images or other visual data.
- Supporting scenarios like interpreting product images, analyzing diagrams, or understanding complex visual cues.
This function loads both the LLaVA model and its tokenizer, ensuring the multimodal assistant is fully equipped to process and respond to queries requiring visual understanding.
These functions are integral to enabling the multimodal capabilities of the AI assistant, allowing it to intelligently combine textual and visual information.
Converting PDF Pages to Images and Encoding for Processing
This section covers the process of converting PDF pages into images and encoding these images into a suitable format for further processing. These steps are vital for scenarios where customer support queries include documents, diagrams, or other visual content.
1. PDF to Image Conversion
The pdf_to_images function converts each page of a PDF file into an image format (e.g., JPEG or PNG). This transformation is necessary because the multimodal AI assistant processes visual inputs in the form of images. For example, when a customer uploads a PDF document, such as a product manual or brochure, converting it into images enables the system to analyze and respond effectively to visual data.
This function uses the pdf2image library to perform the conversion reliably. Key features of this step include:
- Efficient handling of multi-page PDFs.
- High-quality image output to preserve details required for accurate processing.
2. Image Encoding
The encode_image function reads an image file from a specified path and encodes it into Base64 format. This step is critical because:
- Base64 encoding transforms binary image data into text, making it suitable for transmission in APIs or web-based requests.
- Many AI models and services require image data in Base64 format for seamless input processing.
Here’s how these functions work together to prepare visual data for the multimodal AI assistant:
File Indexing for Efficient Retrieval in Multimodal AI Systems
The index_file function is a pivotal component in organizing and indexing documents (such as PDFs, images, and text files) to enable efficient retrieval. This step is crucial for building a multimodal AI assistant capable of accessing and processing documents quickly, ensuring timely and relevant responses to customer support queries.
1. Handling PDF Files
If the input file is a PDF, the function performs the following steps:
- Conversion to Images: Each page of the PDF is converted into an image using the pdf_to_images function. This step ensures that the system can handle the visual data contained within the document, such as diagrams or images.
- Page-by-Page Indexing: Each converted image is saved as a separate file and indexed individually using the provided RAG model. By indexing each page, the system ensures that the entire document, regardless of its length or complexity, is searchable and accessible for future queries.
2. Handling Non-PDF Files
For non-PDF files (e.g., images or text files), the function bypasses the conversion step and directly indexes the file. This streamlined process avoids unnecessary transformations for files already in a format suitable for the AI assistant, such as simple image files or plain text documents.
Why It Matters
By differentiating how files are processed and indexed based on their type, the index_file function ensures that the multimodal AI assistant can:
- Seamlessly handle diverse document formats.
- Retrieve specific content quickly and accurately, regardless of whether it originates from a PDF manual or an image file.
- Offer more efficient and effective customer support by maintaining an organized and easily accessible knowledge base.
See the implementation below:
Q&A Over Images with ColPali and LLaVA
This section outlines two methods for performing question-and-answer (Q&A) tasks using images indexed in the system. Both approaches leverage state-of-the-art multimodal models, ColPali and LLaVA, making them invaluable for customer support scenarios that require visual context.
1. Q&A with ColPali
The qna_with_colipali function uses the ColPali model, which is specifically designed for multimodal retrieval-augmented generation (RAG).
- How It Works: The function queries the ColPali model with a specific question. The model retrieves the top three most relevant results based on the query.
- Outputs: For each result, it provides the path to the image and the associated text, ensuring a clear context for the retrieved visual content.
This method is best suited for retrieving visual materials such as product images, technical diagrams, or charts that help answer customer questions effectively.
2. Q&A with LLaVA
The qna_with_llava function integrates the LLaVA (Large Language and Vision Assistant) model, which excels at advanced multimodal processing by combining visual and textual inputs.
- How It Works:
- Image Processing: The provided image is processed through a vision processor to extract visual features.
- Text Tokenization: The query is tokenized for textual understanding.
- Response Generation: The LLaVA model combines the image and text inputs to generate a contextually relevant response.
- Use Case: This method is ideal for answering questions that require both image interpretation and textual context, such as identifying objects in a photo, explaining visual elements, or providing insights based on a visual prompt.
Here’s the code for both methods:
Main Workflow: Orchestrating the Multimodal AI Assistant
This module brings together all the components of the multimodal AI assistant system, from loading models to indexing files and handling question-and-answer (Q&A) tasks. By leveraging the strengths of ColPali and LLaVA, this workflow ensures seamless integration for customer support applications that require multimodal capabilities.
Workflow Steps
- Model Loading
- The workflow begins by loading the ColPali model for multimodal retrieval and the LLaVA model for multimodal understanding and response generation.
- These models enable the system to process textual and visual inputs efficiently.
- File Indexing
- File paths for images or PDFs to be indexed are specified.
- The index_file function processes each file. For PDFs, it converts pages into images and indexes them using the ColPali RAG model. This ensures all relevant data is prepared for future retrieval.
- Query and Retrieval
- A user query is defined (e.g., “What is the age of the star hosting the Kepler-51 planetary system?”).
- The ColPali model retrieves the most relevant documents (including both image paths and associated text) based on this query.
- Response Generation
- Each document retrieved by ColPali is passed to LLaVA for response generation.
- The LLaVA model combines the retrieved image and query to generate a detailed and context-aware response.
- The final output includes the image path and the AI-generated response.
This modular and scalable workflow efficiently handles complex multimodal queries, making it ideal for applications requiring both textual and visual understanding.
Results

Summary
This tutorial details the step-by-step process of creating a multimodal AI assistant capable of handling both textual and visual queries, making it an invaluable tool for customer support systems. To create your own assistant, you need powerful GPUs that are available on E2E Cloud.
What E2E Cloud offers are the following:
- Unbeatable GPU Performance: Access top-tier GPUs like H200, H100, and A100—ideal for state-of-the-art AI and big data projects.
- India’s Best Price-to-Performance Cloud: Whether you’re a developer, data scientist, or AI enthusiast, E2E Cloud delivers affordable, high-performance solutions tailored to your needs.
Get Started with E2E Cloud Today
Ready to supercharge your projects with cutting-edge GPU technology?
- Launch a cloud GPU node tailored to your project needs.
E2E Cloud is your partner for bringing ambitious ideas to life, offering unmatched speed, efficiency, and scalability. Don’t wait—start your journey today and harness the power of GPUs to elevate your projects.