Large and small businesses often deal with large volumes of invoices, which can be time-consuming and error-prone to process manually. To tackle this challenge, advancements in AI are transforming the way companies handle repetitive tasks like invoice processing. Enter Llama 3.2-11B, a powerful AI model designed to streamline complex tasks such as extracting and understanding text from images, making it an ideal solution for automating bulk invoice processing.
This guide will walk you through the process of using Llama 3.2-11B for bulk invoice processing. Whether you’re new to AI or looking to implement it into your workflow, we’ll cover everything from setting up the system to extracting data and generating results in just a few simple steps. By the end of this guide, you'll be able to automate invoice processing efficiently, saving time and reducing the risk of manual errors.
Get ₹2,000 free credits to test your AI workloads
Sign up and complete ID verification to unlock free credits. Deploy on NVIDIA H200, H100, and L40S GPUs—no commitment required.
The USP of Llama 3.2-11B
Llama 3.2-11B is a state-of-the-art multimodal large language model developed by Meta, featuring 11 billion parameters. This model is part of the Llama 3.2 series, which integrates both text and image processing capabilities, enabling it to perform complex tasks that involve reasoning over visual and textual data.
Key Features
- Multimodal Capabilities: Llama 3.2-11B can process both images and text, allowing it to handle tasks such as image captioning, visual question answering, and document understanding. This makes it suitable for applications that require comprehension of visual content alongside textual information.
- High-Resolution Image Processing: The model is designed to work with high-resolution images, leveraging a unique architecture that includes an image encoder integrated through cross-attention layers. This integration allows the model to effectively bridge the gap between visual inputs and language outputs.
- Extended Context Length: It supports a context length of up to 128,000 tokens, significantly enhancing its ability to manage extensive data inputs.
Performance and Applications
Llama 3.2-11B has been optimized for various tasks, including:
- Visual Recognition: Identifying objects and scenes in images.
- Image Reasoning: Answering questions about images based on their content.
- Caption Generation: Creating descriptive text for images.
- Document Visual Question Answering: Interpreting documents with visual elements like graphs or charts.
The model has been trained on a large dataset of approximately 6 billion image-text pairs, which enhances its performance across diverse benchmarks, outperforming many existing multimodal models.
How to Get Started with TIR AI Platform
You can get started with the TIR AI / ML Platform here. Here are some screenshots to help you navigate through the platform.
Go to the Nodes option on the left side of the screen and open the dropdown menu. In our case, 100GB will work.
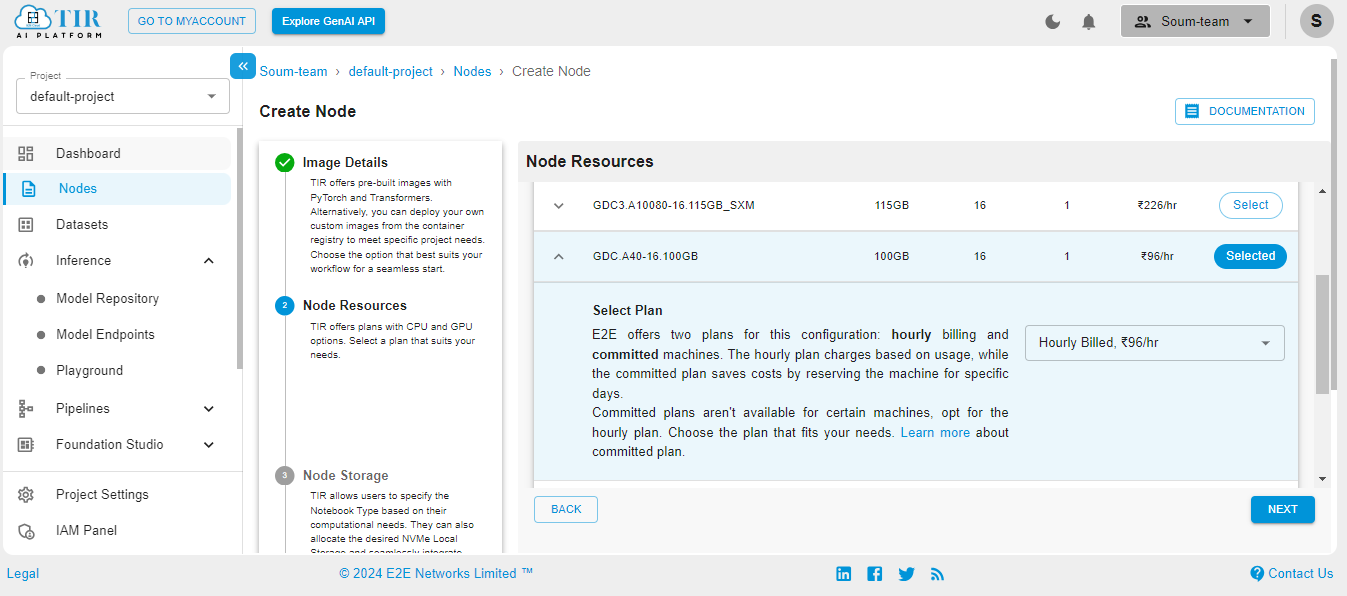
Select the size of your disk as 50GB – it works just fine for our use case. But you might need to increase it if your use case changes.
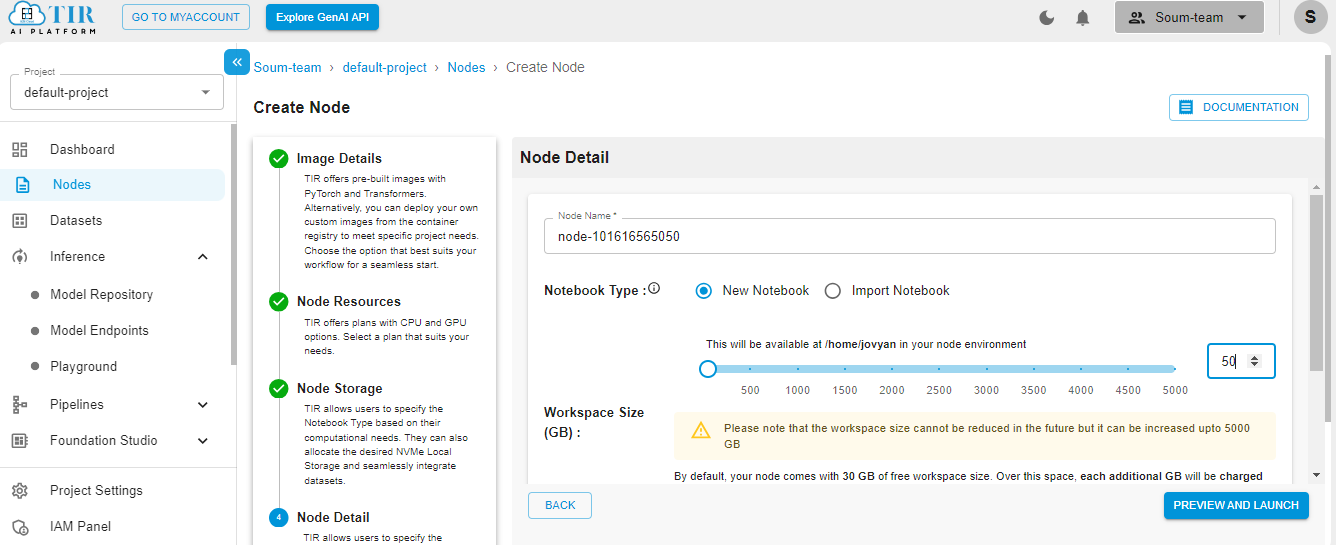
Hit Launch to get started with your TIR Node.
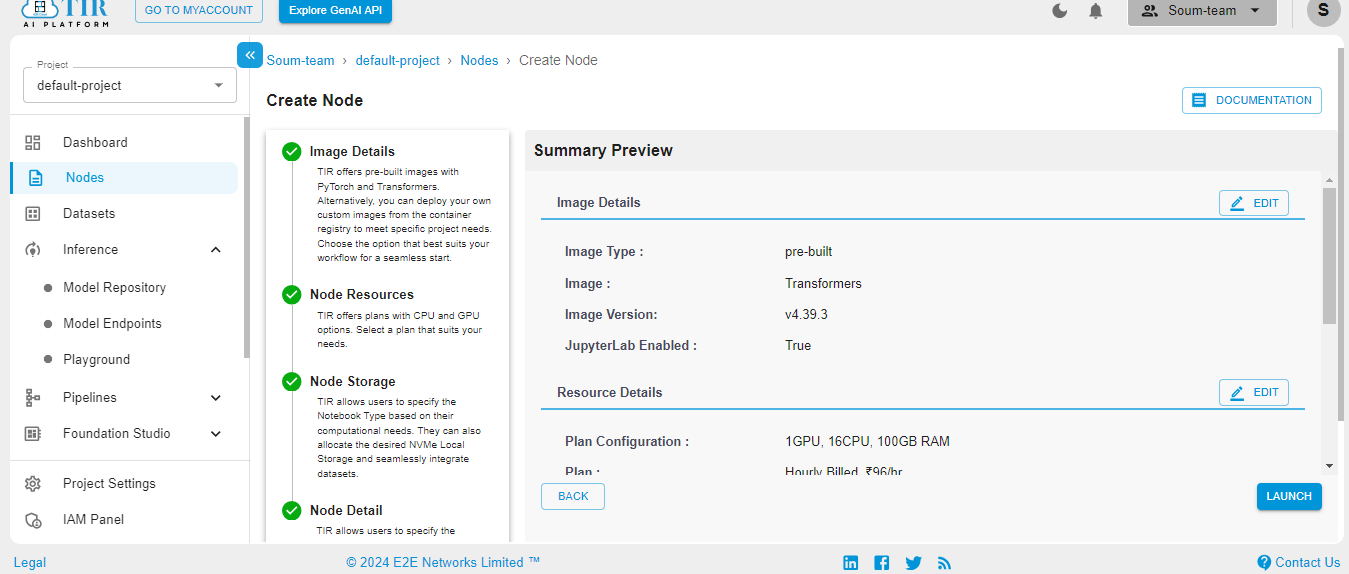
When the Node is ready to be used, it’ll show the Jupyter Lab logo. Hit on the logo to activate your workspace.
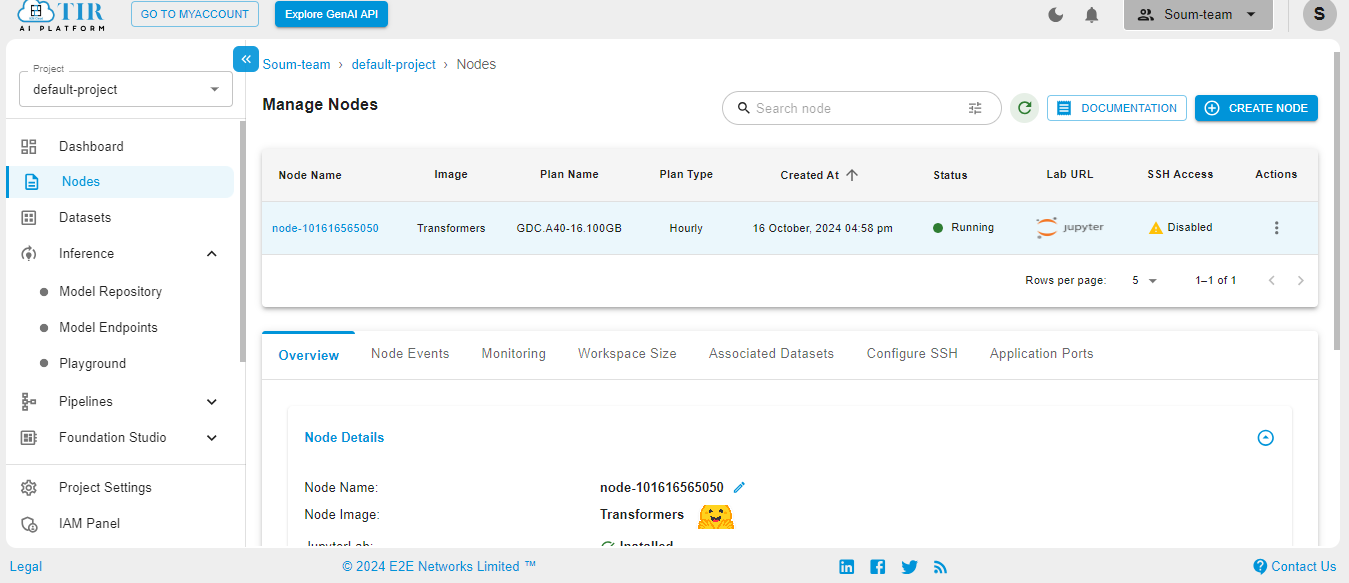
Select the Python3 pykernel, then select the option to get your Jupyter Notebook ready. Now you are ready to start coding.

Get ₹2,000 free credits to test your AI workloads
Sign up and complete ID verification to unlock free credits. Deploy on NVIDIA H200, H100, and L40S GPUs—no commitment required.
Let’s Code
Step 1: Install Required Libraries
Begin by installing the libraries needed for the project.
!pip install -q sentence-transformers transformers qdrant-client gradio PillowThese libraries include:
- sentence-transformers: For text embeddings.
- transformers: Provides pre-trained models for various NLP tasks.
- qdrant-client: Used for vector similarity search with Qdrant.
- gradio: For building web interfaces to interact with your models.
- Pillow: For handling image data.
Step 2: Import Required Libraries
Once the libraries are installed, import them into your environment:
import torch
from PIL import Image as PIL_Image
from transformers import MllamaForConditionalGeneration, MllamaProcessor
from sentence_transformers import SentenceTransformer
from qdrant_client import QdrantClient
from qdrant_client.http.models import PointStruct
import requests
import gradio as gr
from typing import Listfrom huggingface_hub import login
login(token="")Step 3: Initialize the Models and Services
This block of code is responsible for setting up and initializing the various models and services required for the bulk invoice processing system.
- Loading the Llama Model: The first part of the code initializes the core of the project, the Llama-3.2-11B Vision model. The MllamaForConditionalGeneration class is used to load the pre-trained Llama model. This model is capable of understanding and processing visual data (in this case, images of invoices) and can generate textual responses based on that input. The device_map="auto" ensures that the model is mapped to the available hardware (such as GPUs) for faster processing, while torch_dtype=torch.bfloat16 helps in optimizing memory usage without sacrificing precision.
- Setting Up the Processor: The MllamaProcessor is another key component, responsible for preparing the input data (invoices or images) for the model. It processes images, converts them into a format that the model can understand, and adds any necessary prompts or templates required for generating responses. This processor bridges the gap between the raw data and the Llama model, ensuring smooth communication.
- Initializing the Embedder: The SentenceTransformer from the sentence-transformers library is loaded next. Specifically, the "all-mpnet-base-v2" model is used to generate high-quality text embeddings. This model converts text into a fixed-size vector representation, making it easier to compare, search, and analyze the text in a mathematical way. These embeddings are critical for efficiently storing and retrieving relevant information from the Qdrant database.
- Setting Up Qdrant Client: The final part of the block initializes a Qdrant client in memory (:memory:). Qdrant is a vector database designed to handle the embeddings generated from the text. It allows the system to perform fast and efficient searches, making it possible to retrieve relevant data quickly. For the sake of this example, the database is stored in memory, but it can be configured to persist data for larger-scale operations.
# Initialize all models and services
model_id = "meta-llama/Llama-3.2-11B-Vision-Instruct"
model = MllamaForConditionalGeneration.from_pretrained(model_id, device_map="auto", torch_dtype=torch.bfloat16)
processor = MllamaProcessor.from_pretrained(model_id)
embedder = SentenceTransformer("sentence-transformers/all-mpnet-base-v2")
qdrant_client = QdrantClient(":memory:")Step 4: Extract Text from Images
The function convert_url_to_text(url) is designed to take an image URL and extract any text present in the image. It works by first fetching the image from the URL using the requests library and then opening it with the help of the Python Imaging Library (PIL). Once the image is loaded, it is passed through the Llama 3.2-11B model, which has been pre-trained to recognize and extract text from images. The text extracted is then returned for further use. This part of the code is vital because it serves as the foundation of the entire invoice processing pipeline—turning visual information into readable, machine-usable text.
def extract_text_from_image(image_path: str) -> str:
"""Extract text from a local image using LLama 3.2 Vision Model."""
# Open the image from the local path
raw_image = PIL_Image.open(image_path).convert("RGB")
# Simple message template to extract text
messages = [
{
"role": "user",
"content": [
{"type": "image"},
{"type": "text", "text": "Extract text from the image, respond with only the extracted text."}
]
}
]
# Apply the chat template and generate the prompt for the processor
input_text = processor.apply_chat_template(messages, add_generation_prompt=True)
# Prepare the inputs for the model (image and input text)
inputs = processor(images=raw_image, text=input_text, return_tensors="pt").to(model.device)
# Generate output using the model
output = model.generate(**inputs, max_new_tokens=512)
# Decode the output and remove the input prompt from the result
return processor.decode(output[0])[len(input_text):]Step 5: Generate Embeddings from Extracted Text
The generate_embeddings function plays a crucial role in converting the extracted text from images into a format that can be effectively processed by the system. It takes the raw text as input and generates embeddings, which are numerical representations (vectors) of the text.
The core of this function lies in the embedder.encode() method, where the actual transformation happens. The embedder is a pre-trained model that understands the meaning and context of the text, turning it into a vector that reflects its semantic content. By using these embeddings, the system can perform similarity searches, compare different texts, and retrieve related information much faster and more efficiently.
This embedding step is foundational for any advanced query-based system. It ensures that the extracted invoice text is stored in a way that the system can search and retrieve relevant information accurately, making the process of bulk invoice handling much more streamlined and scalable.
# 2. Generate embeddings from the extracted text
def generate_embeddings(text: str):
"""Generate embeddings for the extracted text."""
return embedder.encode(text)Step 6: Save Embeddings to the Qdrant Vector Database
This block of code is responsible for storing the text embeddings, along with the associated text, into the Qdrant vector database. Here's how it works:
- Function Purpose: The function save_embedding_to_qdrant takes three parameters:some text
- embedding: This is the vector representation of the extracted text (created by the embedding model).
- text: The original text that was processed from the image.
- vector_id: A unique identifier for the entry, which helps in distinguishing between different pieces of data in the Qdrant database.
- Upserting the Data: Inside the function, the qdrant_client.upsert() method is used to add or update data in the Qdrant vector database. The method ensures that the data is inserted into a specific collection, in this case, "image_text_collection". A collection in Qdrant is similar to a table in a traditional database — it stores related data points.
- Structuring the Data: The PointStruct object is used to organize the data before it’s inserted into the database. Each point has:some text
- An id (which is the vector_id in this case) to uniquely identify it.
- A vector, which is the embedding created from the extracted text. This vector is a fixed-size representation that allows for quick similarity searches.
- A payload, which contains the original text that was processed from the image, so that the text can be easily retrieved along with its embedding.
By saving the text embeddings in the Qdrant database, this function allows the system to later query and retrieve relevant data efficiently. Storing embeddings in this format enables the system to perform vector-based searches, which are crucial for comparing and retrieving similar texts when processing bulk invoices.
# 3. Save the embedding in Qdrant vector database
def save_embedding_to_qdrant(embedding, text, vector_id: int):
"""Save embedding to Qdrant vector database."""
qdrant_client.upsert(
collection_name="image_text_collection",
points=[
PointStruct(
id=vector_id,
vector=embedding,
payload={"text": text}
)
]
)Step 7: Retrieve the Relevant Texts
Once the text is indexed, we need a way to retrieve relevant information based on a query. This is where the function retrieve_relevant_text(query) is used. Given a user’s query, it generates an embedding for the query text using the same Llama 3.2 model. Then, it searches through the Qdrant database to find similar vectors, i.e., the texts that are most relevant to the query. This allows for a fast and accurate way to find specific information within the large dataset of invoice text. It’s like using a search engine tailored for the specific data stored in Qdrant.
# 4. Query the Qdrant vector database for similar embeddings
def query_qdrant(query_embedding, top_k=5):
"""Query Qdrant vector database for the closest embeddings."""
response = qdrant_client.search(
collection_name="image_text_collection",
query_vector=query_embedding,
limit=top_k
)
return responseStep 8: Generate the Final Answer
The final step in the process is executed by the generate_answer(context, query) function. After the relevant texts have been retrieved, this function utilizes the Llama 3.2-11B Vision model to generate a coherent and detailed response. The function takes the retrieved context and the user's query as inputs and formulates a human-friendly answer. Using a structured message template, it prompts the model to provide a clear, readable response. The output is then decoded, refined, and returned to the user, offering a precise answer based on the uploaded invoices and the user’s query.
# 5. Use LLama 3.2-11B Vision model to generate human friendly answer for
def generate_answer(context, query):
messages = [
{
"role": "user",
"content": [
{"type": "text", "text": “From the following given context evaluate humans friendly readable answer for the given query},
{"type": "text", "text": " ".join(context)}, # Insert context
{"type": "text", "text": query} # Insert user query
]
}
]
# Generate input for the model
input_text = processor.apply_chat_template(messages, add_generation_prompt=True)
inputs = processor(text=input_text, return_tensors="pt").to(model.device)
# Generate response
output = model.generate(**inputs, max_new_tokens=512)
# Decode and return the response text
response = processor.decode(output[0])[len(input_text):]
return response Step 9: Main Function to Process Images and Query the System
This block of code is the core function that ties together the various components of the system, processing images, extracting text, generating embeddings, and querying the database to provide meaningful responses. Here's how it works:
- Function Overview: The process function takes in two inputs:some text
- images: A list of uploaded image files, which contain the data to be processed.
- query: A text-based query that will be used to search through the extracted text for relevant information.
- ID Tracking for Qdrant: The function starts by initializing a vector_id at 1, which is used to uniquely identify and store each embedding into the Qdrant database. Additionally, it maintains a list all_contexts to collect the extracted text from all the images.
- Processing Each Image: For every image in the uploaded list:some text
- The image.name is extracted to keep track of the image file being processed.
- Text Extraction: It calls the extract_text_from_image function to extract the text content from the image, which is then stored in all_contexts.
- Generate Embeddings: The extracted text is passed through the generate_embeddings function to create a vector representation.
- Save to Qdrant: The generated embedding, along with the extracted text and a unique ID (vector_id), is saved into the Qdrant vector database using the save_embedding_to_qdrant function.
- Combining Contexts: Once all the images are processed, the texts collected from each image are combined into a single string (combined_context). This is used to provide a more comprehensive context for generating answers.
- **Handling the Query:**some text
- Embedding the Query: The query text is also passed through the generate_embeddings function to create a vector representation, similar to the image text.
- Querying Qdrant: The function queries the Qdrant database using the query’s embedding to retrieve any matching or relevant text entries that were stored from the images.
- Formatting Retrieved Results: The retrieved results are structured in a readable format, showing the ID and text of each matching result.
- Generating a Final Answer: The generate_answer function is used to produce a final answer by using the combined context from all images and the provided query. This ensures that the response is relevant and detailed, based on all available information.
- Return Values: The function returns the combined context (the extracted text from all images) and the final answer to the query. These are displayed to the user via the Gradio interface.
This function acts as the main engine for processing images and generating responses, orchestrating the flow between extracting text, embedding data, querying the database, and providing a coherent answer based on the user’s input.
# Existing functions should be defined here
# Ensure these functions are available:
# extract_text_from_image, generate_embeddings, save_embedding_to_qdrant,
# query_qdrant, generate_answer
# Main function to handle the Gradio inputs
def process(images, query):
vector_id = 1 # ID tracker for Qdrant storage
all_contexts = [] # Collect all contexts (texts) extracted from images
# Process each uploaded image
for image in images:
image_path = image.name
print(f"Processing image: {image_path}")
# Extract text from the image
image_text = extract_text_from_image(image_path)
print(f"Extracted Text: {image_text}")
# Store the extracted text as context
all_contexts.append(image_text)
# Generate embeddings from the extracted text
embedding = generate_embeddings(image_text)
# Save embedding into Qdrant
save_embedding_to_qdrant(embedding, image_text, vector_id)
vector_id += 1
# Combine all contexts for final answer generation
combined_context = " ".join(all_contexts)
# Generate embeddings for the query
query_embedding = generate_embeddings(query)
# Query the Qdrant database for similar results
retrieved_results = query_qdrant(query_embedding)
# Prepare retrieved results for output
results_output = "\n".join([f"ID: {result.id}, Text: {result.payload['text']}" for result in retrieved_results])
# Use the Llama 3.2-11B LLM to generate a final answer based on the combined context and the query
final_answer = generate_answer(combined_context, query)
return combined_context ,final_answerStep 10: Gradio Interface for User Interaction
Finally, the gradio_interface() function brings everything together into a user-friendly interface using Gradio. It allows users to upload images (invoices) and ask queries about the content. When the user provides a query, the interface calls the process() function, which processes the images, extracts the text, stores it in Qdrant, and generates the final answer. The Gradio interface simplifies interaction by allowing users to directly upload files and input queries through a web-based UI, making the bulk invoice processing workflow accessible to non-technical users.
# Define the Gradio interface
interface = gr.Interface(
fn=process,
inputs=[gr.Image(type="filepath", label="Upload Images"),
gr.Textbox(label="Query", placeholder="Enter your query here...")],
outputs=[gr.Textbox(label="Retrieved Results"),
gr.Textbox(label="Final Answer")],
title="Image Processing and Query System",
description="Upload images to extract text and ask queries about the content."
)
# Launch the Gradio app
interface.launch(share=True)Results
Let’s take a look at the results:
- First result:


image_list = ["invoice1.png", "invoice2.png"] # List of image paths
query_text = "what is the final billing of both the bills combined?"
process_images_and_query_system(image_list, query_text)
Processing image: invoice1.png
Processing image: invoice2.png
Final Answer: To find the final billing of both bills combined, I will add the invoices together:
Bill 1: $154.06
Bill 2: $154.06
Total Bill: $308.12
So the final billing would be:
Total Bill # US-001
East Repair Inc.
1912 Harvest Lane
New York, NY 12210
FINAL BILLING # US-002
East Repair Inc.
1912 Harvest Lane
New York, NY 12210
Bill To
John Smith
2 Court Square
New York, NY 12210
Ship To
John Smith
3787 Pineview Drive
Cambridge, MA 12210
Invoice # US-002
Invoice Date 11/017019
P.O.#
2312/2019
Due Date 26/02/2019
QTY DESCRIPTION UNIT.Price AMOUNT
1 Front and rear brake cables
100.00
100.00
2 New set of pedal arms
15.00
30.00
3 Labor 3hrs
5.00
15.00
Subtotal
145.00
Sales Tax 6.25 %
9.06
TOTAL
$154.00- Here’s the second one:

# Example usage
image_list = ["invoice1.png", "invoice2.png"] # List of image paths
query_text = "How many bills are there?"
process_images_and_query_system(image_list, query_text)
Processing image: invoice1.png
Processing image: invoice2.png
'There are 2 bills in the given context:\n\n1. US-001\n2. US-001 (invoice description only, same amount, but different dates)'- The third:

# Example usage
image_list = ["invoice1.png", "invoice2.png"] # List of image paths
query_text = "Give me both address?"
process_images_and_query_system(image_list, query_text)
Processing image: invoice1.png
Processing image: invoice2.png
[45]:
'The addresses are:\n\nEast Repair Inc.\n1912 Harvest Lane\nNew York, NY 12210\n\nShip To\n2 Court Square, New York, NY 12210\n\n2 Court Square is the address where the bill is being sent to, but it seems that the bill is also being sent to a different address using the zip code 3787 Pineview Drive, Cambridge, MA 02210.'- The fourth and final result:
undefinedSummary
In conclusion, this guide provides a streamlined approach to using Llama 3.2-11B for bulk invoice processing. Whether you're new to AI or looking to integrate it into your workflow, we've covered the essential steps, from system setup to data extraction and result generation. By following this guide, you’ll be equipped to automate invoice processing efficiently, reducing manual errors and saving valuable time.


