Introduction to FLUX.1-dev
FLUX.1-dev is an advanced open-source text-to-image AI model developed by Black Forest Labs. It features a 12 billion parameter architecture designed for generating high-quality, diverse images based on textual prompts. This model is particularly noted for its exceptional adherence to prompts, advanced rendering capabilities, and suitability for non-commercial applications, making it a valuable tool for researchers, developers, and creatives.
Importance of FLUX.1-dev
FLUX.1-dev stands out in the field of AI image generation due to several key factors:
- Open-Source Accessibility: Its open-weight architecture allows researchers and developers to study, customize, and build upon the model, fostering innovation and collaboration within the AI community.
- High-Quality Output: The model produces images that rival commercial alternatives like Midjourney, particularly excelling in rendering human anatomy and maintaining detail across various prompts.
- Efficiency: Despite its complexity, FLUX.1-dev is optimized for speed and can generate images quickly while maintaining quality, making it suitable for various applications.
Applications of FLUX.1-dev
FLUX.1-dev has a wide array of applications across different fields:
- Creative Industries: It is particularly useful in gaming, film production, advertising, and artistic exploration where high-quality visuals are essential.
- Research and Education: The model serves as a powerful tool for academic projects and studies in AI image generation techniques.
- Product Design: Designers can utilize FLUX.1-dev to visualize concepts rapidly and accurately during the development process.
Our Aim in This Tutorial
In this guide, we'll walk you through the process of deploying and using the FLUX.1-dev model, starting with the installation of critical Python libraries like Diffusers and SentencePiece. These libraries are integral to handling diffusion models and tokenizing text, ensuring seamless integration with the FLUX architecture.
We’ll then dive into initializing the FLUX.1-dev model pipeline from the black-forest-labs repository, explaining how to configure it for optimal performance. You'll learn how to load pre-trained models, utilize bfloat16 for memory-efficient execution, and enable CPU offloading to handle environments with limited GPU resources.
Finally, we’ll cover the process of generating images with the FLUX pipeline. By breaking down the steps to fine-tune parameters such as resolution, guidance scale, and inference steps, this guide will show you how to create high-quality, reproducible images based on text prompts, all the while maintaining efficiency and performance. Whether you're working in a high-performance GPU setup or managing limited resources, this guide will provide the insight you need to make the most of the FLUX.1-dev model.
Let’s Code
Get started with TIR AI / ML Platform here. Here are some screenshots to help you navigate through the platform.
Go to the Nodes option on the left side of the screen and open the dropdown menu. In our case, 100GB will work.
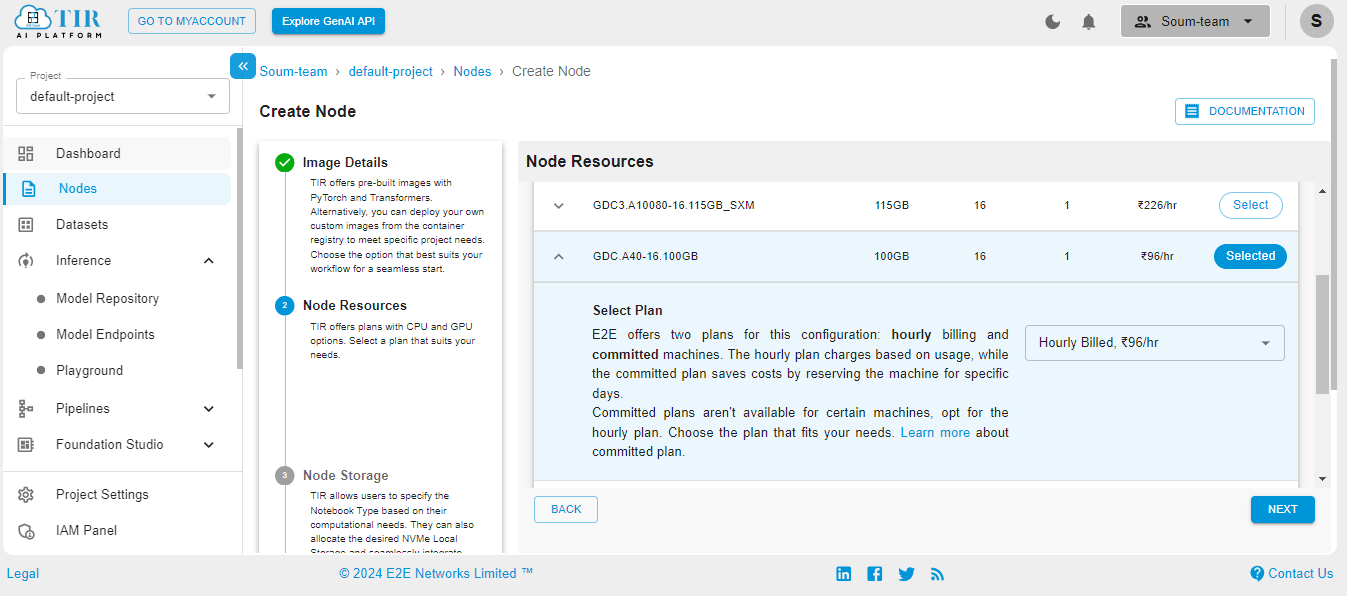
Select the size of your disk as 50GB – it works just fine for our use case. But you might need to increase it if your use case changes.
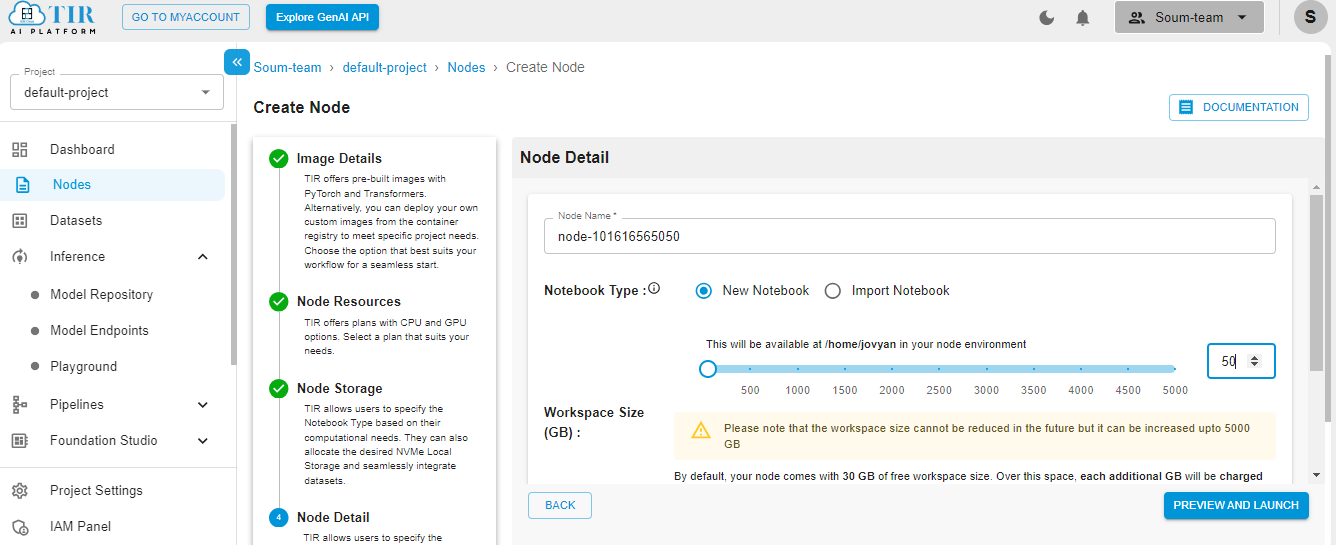
Hit Launch to get started with your TIR Node.
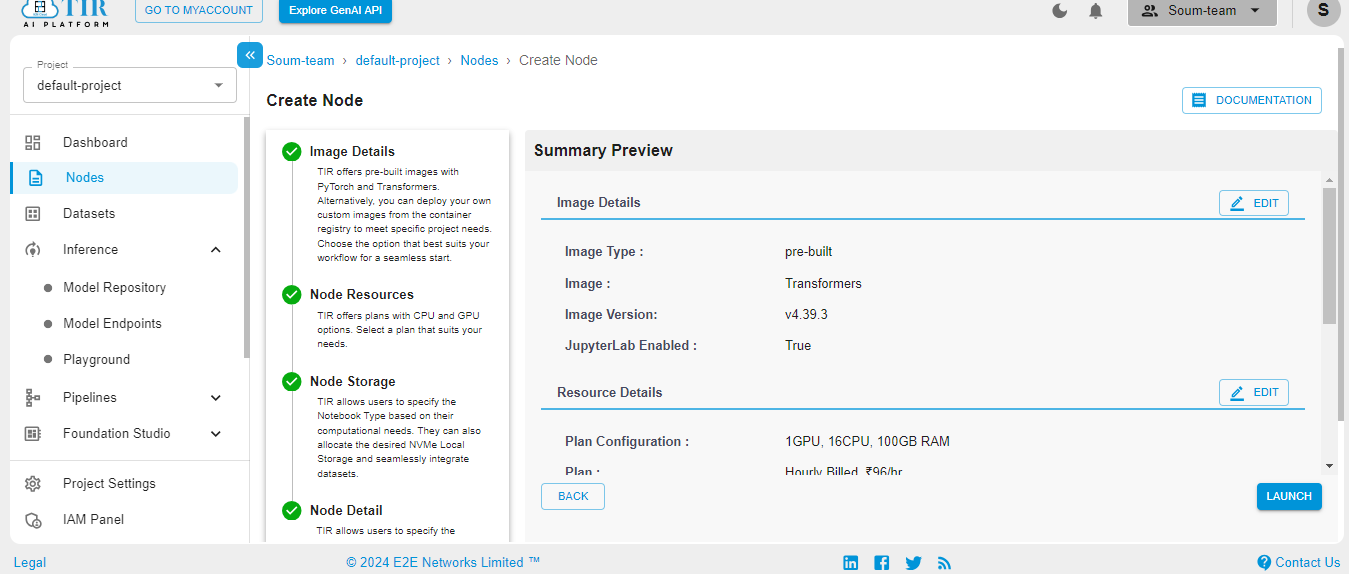
When the Node is ready to be used, it’ll show the Jupyter Lab logo. Hit on the logo to activate your workspace.
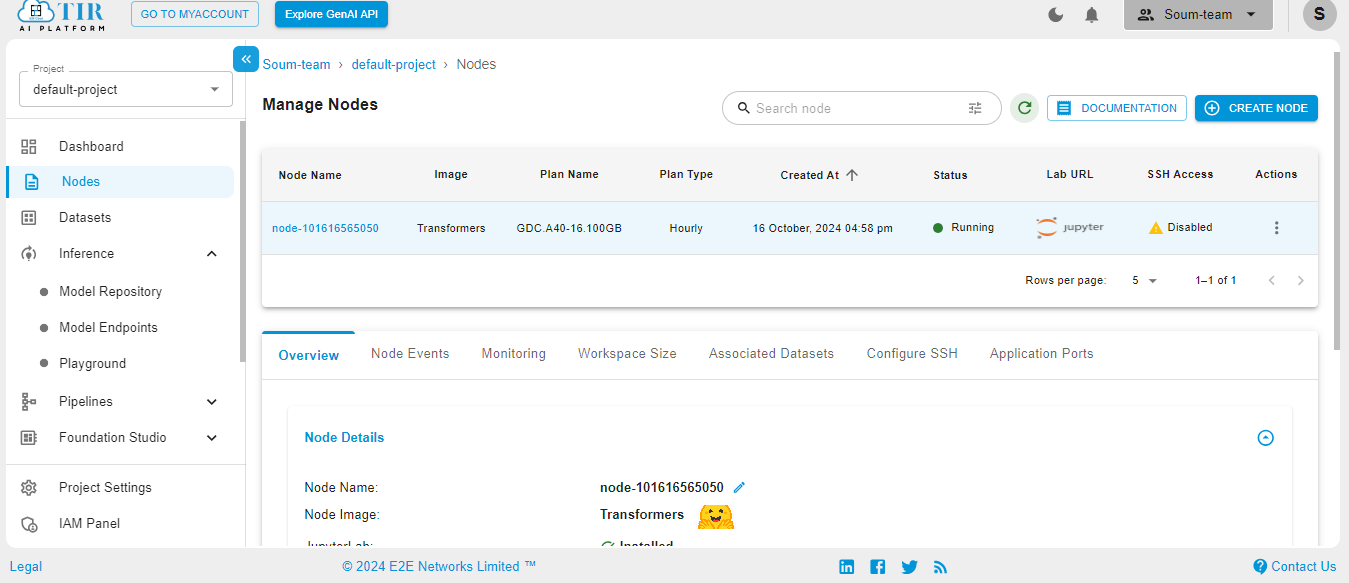
Select the Python3 pykernel, then select the option to get your Jupyter Notebook ready. Now you are ready to start coding.

This command installs or updates two Python libraries: Diffusers and SentencePiece.
- Diffusers: This library, developed by Hugging Face, is designed for working with diffusion models, which are a class of generative models that can produce high-quality images from noise. It provides tools and pre-trained models for various tasks, including image generation and manipulation.
- SentencePiece: This library is a text tokenizer and detokenizer that is often used in natural language processing (NLP) tasks. It helps convert text into a format suitable for model training by breaking sentences into smaller units (subwords), which can improve the performance of NLP models, particularly when dealing with languages with rich morphology or limited training data.
!pip install -U diffusers sentencepiece
import torch
from diffusers import FluxPipeline
from huggingface_hub import notebook_login
notebook_login()
Initializing the FLUX.1-dev Model Pipeline
This code snippet initializes a pipeline for a model using the FLUX.1-dev architecture from the black-forest-labs repository. Here’s a brief overview of what it does:
- Loading the Model:some text
- FluxPipeline.from_pretrained("black-forest-labs/FLUX.1-dev", torch_dtype=torch.bfloat16) loads a pre-trained FLUX model. The torch_dtype=torch.bfloat16 argument specifies that the model should use the bfloat16 data type, which is beneficial for saving memory and improving performance on compatible hardware.
- CPU Offloading:some text
- pipe.enable_model_cpu_offload() enables the model to offload to the CPU when it is not in active use. This can help save GPU memory (VRAM), making it suitable for environments with limited GPU resources. If the hardware has sufficient GPU power, this line can be omitted to keep the model entirely on the GPU for potentially faster inference.
pipe = FluxPipeline.from_pretrained("black-forest-labs/FLUX.1-dev", torch_dtype=torch.bfloat16)
pipe.enable_model_cpu_offload() #save some VRAM by offloading the model to CPU. Remove this if you have enough GPU power
Generating the Images
The generate_image function utilizes the FLUX model pipeline to create an image based on a provided text prompt. It accepts a single input parameter, prompt, which guides the image generation process. Inside the function, the pipe() method is called with specific parameters, including a resolution of 1024x1024 pixels, a guidance scale of 3.5 to control how closely the generated image aligns with the prompt, and a set number of inference steps (50) to improve image quality.
Additionally, it sets a maximum sequence length of 512 for processing the prompt and initializes a random number generator with a fixed seed to ensure reproducibility of the results. After generating the image, the function saves the first image from the output as "flux-dev.png." This encapsulated approach allows users to efficiently create and save images derived from textual descriptions using the powerful capabilities of the FLUX model.
def generate_image(prompt):
image = pipe(
prompt,
height=1024,
width=1024,
guidance_scale=3.5,
num_inference_steps=50,
max_sequence_length=512,
generator=torch.Generator("cpu").manual_seed(0)
).images[0]
image.save("flux-dev.png")
prompt = "A cat holding a sign that says hello world"
generate_image(prompt)

prompt = "A man on beach looking to moon"
generate_image(prompt)

prompt = "a Crocodile riding a bicycle"
generate_image(prompt)

Conclusion
In this tutorial, you learnt how to deploy the FLUX.1-dev model. You can use this to generate your own custom images. If you are a media company, or building a media AI SaaS application, you should leverage the power of the Flux.1-dev model.
To get started with Flux.1-dev, sign up to E2E Cloud today, and launch a cloud GPU node, or head to TIR. E2E Cloud offers the most price-performant cloud GPUs in the Indian market, and enables developers to use advanced GPUs like H200, H100, A100 for application development.









