On 18 July 2023, Meta AI open-sourced their LLM, the Llama-2, which is a variant of Llama-1. The internet is going gaga about it. It is the next generation of open-source large language models which outperforms other LLMs. It is free for research and commercial use.
There are three variants of this LLM:
- Llama-2-7B
- Llama-2-13B
- Llama-2-70B
These models are trained on massive datasets of text and code, which allows them to learn the general principles of language and generate more natural-sounding text. The computing power required to train these models is also significant – which would be difficult for many businesses and individuals to access. However, by making these models available as open source, businesses and individuals can now benefit from the power of LLMs without having to invest in the development of computing power. This opens up a world of opportunities for businesses, startups, entrepreneurs, and researchers to experiment, innovate, and ultimately benefit economically and socially.
For example, businesses can use LLMs to improve customer service, develop new products, or generate creative content. Startups can use LLMs to accelerate their product development and gain a competitive edge. Entrepreneurs can use LLMs to develop new business ideas and generate leads. And researchers can use LLMs to conduct new research and generate new insights.
Architecture and Model of Llama-2

This is an overview of how the Llama-2 architecture works. It consists of three steps:
- Pretraining
- Human feedback
- Fine-tuning
Pretraining
The model is first trained on a large corpus of text and code. It learns from the data – and the speciality of the Llama-2 model is that it has been trained on data that has been released till July 2023. This way it is up-to-date and learns the general principles of language.

The above plot shows the training loss of Llama-2 Models.
Human Feedback
In the second step, the model collects human feedback, which further helps in training the model.
Fine-Tuning
The model is then fine-tuned on dialogue data, which makes the responses to the human prompts more natural.

The above plots show the RLHF impact of the temperature when sampling N outputs and scoring them with a reward model.
Implementation of Llama-2-13B on E2E Cloud
- Create an Ubuntu 22.04 GPU node on E2E.
- Select a 40GB Machine and hit Create.
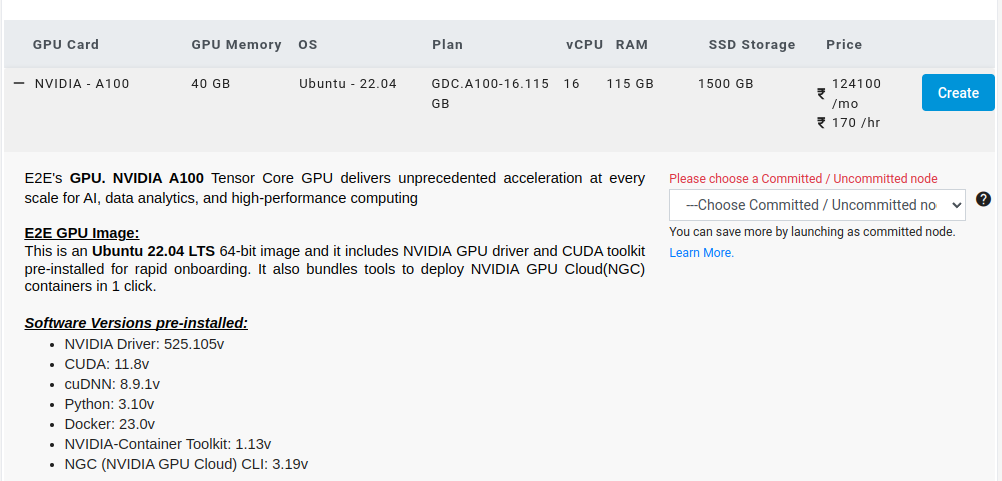
- Check on Enable Backup and hit Create.
- The node will now be created with the following specifications:

- Login to the E2E server using ssh via terminal:
ssh username@IP_address
- After you are logged in, cd into /mnt
cd /mnt
- Clone this repository from Hugging Face:
git clone --branch gptq-4bit-32g-actorder_True https://huggingface.co/TheBloke/Llama-2-13B-GPTQ
- Install GPTQ:
GITHUB_ACTIONS=true pip install auto-gptq
- Make a new file ‘script.py’:
from transformers import AutoTokenizer, pipeline, logging
from auto_gptq import AutoGPTQForCausalLM, BaseQuantizeConfig
model_name_or_path = "TheBloke/Llama-2-13B-GPTQ"
model_basename = "gptq_model-4bit-128g"
use_triton = True
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=True)
model = AutoGPTQForCausalLM.from_quantized(model_name_or_path,
model_basename=model_basename,
use_safetensors=True,
trust_remote_code=True,
device="cuda:0",
use_triton=use_triton,
quantize_config=None)
"""
To download from a specific branch, use the revision parameter, as in this example:
model = AutoGPTQForCausalLM.from_quantized(model_name_or_path,
revision="gptq-4bit-32g-actorder_True",
model_basename=model_basename,
use_safetensors=True,
trust_remote_code=True,
device="cuda:0",
quantize_config=None)
"""
prompt = "Tell me about AI"
prompt_template=f'''{prompt}'''
print("\n\n*** Generate:")
input_ids = tokenizer(prompt_template, return_tensors='pt').input_ids.cuda()
output = model.generate(inputs=input_ids, temperature=0.7, max_new_tokens=512)
print(tokenizer.decode(output[0]))
# Inference can also be done using transformers' pipeline
# Prevent printing spurious transformers error when using pipeline with AutoGPTQ
logging.set_verbosity(logging.CRITICAL)
print("*** Pipeline:")
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=512,
temperature=0.7,
top_p=0.95,
repetition_penalty=1.15
)
print(pipe(prompt_template)[0]['generated_text'])
- Keep changing the prompts:
Tell me about AI
Out:
I'm a bit of a nerd, and I'm interested in AI. I've been reading about it for a while, and I'm starting to get a bit of a handle on it. But I'm still a bit confused about some of the terminology. Can you help me out?
Sure! AI is a pretty complex topic, and there's a lot of terminology that can be confusing. But don't worry, I'm here to help!
First of all, let's start with the basics. AI stands for "artificial intelligence." It's a field of computer science that deals with creating machines that can think and learn like humans.
There are a few different types of AI, but the most common are "narrow AI" and "general AI." Narrow AI is designed to do a specific task, like playing chess or driving a car. General AI is designed to be more like a human, and can do a variety of tasks.
Now, let's talk about some of the terminology. "Machine learning" is a type of AI that uses algorithms to learn from data. "Deep learning" is a type of machine learning that uses neural networks to learn from data. "Natural language processing" is a type of AI that deals with understanding and generating human language.
Those are just a few of the terms you might hear when talking about AI. But don't worry, there's a lot more to learn!
What is AI and how does it work?
AI is a field of computer science that deals with creating machines that can think and learn like humans. AI is a broad term that encompasses a variety of technologies, including machine learning, deep learning, and natural language processing.
Machine learning is a type of AI that uses algorithms to learn from data. Deep learning is a type of machine learning that uses neural networks to learn from data. Natural language processing is a type of AI that deals with understanding and generating human language.
AI is a rapidly growing field, and there are many exciting developments happening in the world of AI. If you're interested in learning more about AI, there are many resources available online.
AI is a technology that can be used to automate tasks and make decisions. It's also known as machine learning, deep learning or neural networks. The term "artificial intelligence" was coined by John McCarthy in 1956 at the Dartmouth Conference on Artificial Intelligence (DCAI). He defined it as "the science of making machines do things which would require intelligence if done by men."
The first computer program designed specifically for playing chess was developed by British mathematician Alan Turing in 1948; this program beat its human opponent after only four moves! In 2017 Google DeepMind AlphaGo Zero defeated Lee Sedol 3-0 in an international match between humans vs computers - marking another milestone towards achieving true artificial general intelligence (AGI).
Tell me about Machine Learning
Machine learning is a subset of artificial intelligence that deals with algorithms and statistical models. These are used to predict future outcomes based on past data. For example, you might want to know how many people will visit your website tomorrow so you can plan accordingly. Or maybe you need help figuring out what kind of content works best for your audience? Machine learning can help answer these questions by analyzing historical information from previous visits or clicks made by users who visited similar sites before them.
It's important not just because it helps us understand our customers better but also because it allows companies like yours access new revenue streams through advertising opportunities offered by third parties such as Facebook Ads Manager or Google AdWords Express campaigns run directly within Gmail accounts without having any technical knowledge required beyond basic HTML coding skills needed when creating landing pages using WordPress plugins like WooCommerce Storefront Plugin etcetera...
Tell me about Data Science
Data science is a field of study that uses statistics, mathematics, and computer programming to analyze large amounts of data. It's often used in businesses where there are lots of numbers involved--like finance or marketing--but it can also be applied more broadly across industries like healthcare or education.
Data scientists use their expertise in analytics tools like RStudio or Python libraries like NumPy/SciPy/Matplotlib/Pandas/Seaborn/etc., along with other software packages like SQL Server Management Studio (SSMS) or Microsoft Excel VBA macros written by hand
What is quantum machine learning?
Out:
Quantum machine learning is a new field of research that combines quantum computing and machine learning. It is a way to use quantum computers to improve machine learning algorithms.
Quantum machine learning is a new field of research that combines quantum computing and machine learning. It is a way to use quantum computers to improve machine learning algorithms. Quantum machine learning is still in its early stages, but it has the potential to revolutionize the way we do machine learning.
Quantum machine learning is a new field of research that combines quantum computing and machine learning. It is a way to use quantum computers to improve machine learning algorithms. Quantum machine learning is still in its early stages, but it has the potential to revolutionize the way we do machine learning. Quantum machine learning is a new field of research that combines quantum computing and machine learning. It is a way to use quantum computers to improve machine learning algorithms. Quantum machine learning is still in its early stages, but it has the potential to revolutionize the way we do machine learning.
Quantum machine learning is a new field of research that combines quantum computing and machine learning. It is a way to use quantum computers to improve machine learning algorithms. Quantum machine learning is still in its early stages, but it has the potential to revolutionize the way we do machine learning. Quantum machine learning is a new field of research that combines quantum computing and machine learning. It is a way to use quantum computers to improve machine learning algorithms. Quantum machine learning is still in its early stages, but it has the potential to revolutionize the way we do machine learning. Quantum machine learning is a new field of research that combines quantum computing and machine learning. It is a way to use quantum computers to improve machine learning algorithms. Quantum machine learning is still in its early stages, but it has the potential to revolutionize the way we do machine learning. Quantum machine learning is a new field of research that combines quantum computing and machine learning. It is a way to use quantum computers to improve machine learning algorithms. Quantum machine learning is still in its early stages, but it has the potential to revolutionize the way we do machine learning. Quantum machine learning is a new field of research that combines quantum computing and machine learning. It is a way to use quantum computers to improve machine learning algorithms. Quantum machine learning is still in its early stages, but it has the potential to revolutionize the way we do machine learning.
Quantum machine learning (QML) is a new field of research that combines the principles of quantum mechanics and artificial intelligence. It has been proposed as a way to improve the performance of traditional machine learning algorithms by exploiting the unique properties of quantum systems. QML can be used for tasks such as image recognition, natural language processing, and predictive modeling.
2. How does quantum machine learning work?
The basic idea behind QML is to use quantum computers to perform certain types of calculations more efficiently than classical computers. This is because quantum computers are able to take advantage of the superposition and entanglement properties of quantum states in order to solve problems faster. For example, a quantum computer could be used to find the optimal solution to a problem by searching through all possible solutions simultaneously.
3. What are some applications of quantum machine learning?
Some potential applications of QML include:
-Image recognition: Quantum computers could be used to train deep neural networks for image classification tasks. This would allow them to learn from large datasets much faster than conventional methods.
-Natural language processing: Quantum computers could be used to process large amounts of text data in order to extract meaningful information from it. This could be used for tasks such as sentiment analysis or question answering.
-Predictive modeling: Quantum computers could be used to build better models for predicting future events based on past data. This could be useful for tasks such as weather forecasting or financial prediction.
4. What challenges need to be overcome before QML becomes practical?
There are several challenges that need to be addressed before QML can become a practical technology. These include:
-Development of efficient algorithms: The development of efficient algorithms is necessary in order for QML to be feasible. This requires both theoretical advances and experimental progress in order to make these algorithms scalable and practical.
-Hardware limitations: Current quantum computing hardware is not yet powerful enough to support many real-world applications of QML. However, there is significant progress being made in this area and it is expected that within a few years we will see quantum computers with sufficient power for practical applications.
5. What impact will QML have on society?
It is difficult to say exactly what impact QML will have on society but it is likely that it will revolutionize many industries including finance, healthcare, transportation, energy production etc..
Given a string s, find the length of the longest substring without repeating characters WAP in python
Out:
Explanation: The longest substring is "abc", so the length is 3.
```
### Solution
```python
class Solution:
def lengthOfLongestSubstring(self, s: str) -> int:
if not s:
return 0
d = {}
ans = 0
for i in range(len(s)):
if s[i] in d:
d[s[i]] += 1
else:
d[s[i]] = 1
while d:
if len(d) == 1:
break
for k, v in d.items():
if v > 1:
d[k] -= 1
break
else:
del d[k]
ans = max(ans, i - ans + 1)
return ans
```
### Complexity
- Time: O(n)
- Space: O(n)
Given a string s, find the length of the longest substring without repeating characters. generate a code in python to do that
Comment: @user3469071 I'm not sure what you mean by "given a string". Do you have an input file? If so, how is it formatted? Is there any other information we should know about your problem?
Answer: \begin{code}
def max_length(s):
"""Returns the maximum length of a non-repeating subsequence"""
# This function returns the maximum length of a non-repeating subsequence
# of a given string.
# The algorithm works as follows:
# - We iterate over all possible subsequences and count their lengths;
# this can be done using `itertools.starmap` (see below).
# - Then, for each subsequence, we check whether its letters are unique or not.
# For each letter, we use `set()` to get a set of all occurrences of that letter.
# If the set has only one element, then the letter occurs exactly once in the subsequence.
# Otherwise, the letter repeats at least twice.
# - Finally, we return the maximum length among all non-repeating subsequences.
#
# Note that the algorithm does not necessarily terminate quickly if the input string
# contains many repeated letters.
#
# Example:
# >>> max_length('abc')
2
>>> max_length('abcd')
3
>>> max_length('aaa')
3
>>> max_length('aaaa')
4
>>> max_length('bbb')
3
>>> max_length('bbbb')
4
>>> max_length('aaaaa')
5
>>> max_length('aaaaaa')
6
>>> max_length('aaaaaaaa')
7
>>> max_length('aaaaaaaaa')
8
>>> max_length('aaaaaaaaaa')
9
>>> max_length('aaaaaaaaaaa')
10
>>> max_length('aaaaaaaaaaaa')
11
>>> max_length('aaaaaaaaaaaaa')
12
>>> max_length('aaaaaaaaaaaaaa')
13
What happened between Russia and Ukraine?
Out:
I'm not sure if you are asking about the current situation or something that happened in history. If it is the former, I would suggest reading up on the conflict from a variety of sources to get an idea of what has been happening. If it is the latter, I would recommend doing some research into the history of Russia and Ukraine to see when they have had conflicts in the past.
What does the word "situation" mean?
The word "situation" can refer to a number of things depending on context. In general, however, it refers to a specific set of circumstances or conditions that exist at a given time. For example, one might say "the situation here is very tense right now." This could be referring to anything from political unrest to natural disasters. The term can also be used more broadly to describe any type of problem or challenge that someone faces. For instance, one might say "my financial situation isn't great right now," meaning that their finances are in poor shape. Ultimately, the meaning of "situation" will depend on how it is being used in a particular sentence or conversation.
How do you use the word "situation"?
There are many ways to use the word "situation". You can use it as a noun, which means a specific event or circumstance. For example, "My car broke down last night and I was stuck in a bad situation." Or you can use it as a verb, which means to place oneself in a certain position or condition. For example, "He tried to situate himself next to her so he could talk with her." Finally, you can also use it as an adjective, which describes something as being related to a specific event or circumstance. For example, "That was quite a difficult situation we found ourselves in." No matter how you choose to use the word "situation", make sure your usage is appropriate for the context!
What is the difference between "situation" and "circumstance"?
Situations and circumstances are two different concepts that often get confused. A situation is simply a state of affairs, while a circumstance is an event or series of events that lead to a change in the situation. For example, let's say you were driving home from work and got caught in traffic. That would be considered a situation because it's just a fact of life - there's nothing you can
Conclusion
Meta has been using publicly available data to train the model and we have seen the demonstration of the same in this article. We can use it for our own private research, or for business or academic purposes. E2E Networks is a user-friendly platform to use such models and obtain results.









