Image processing technologies are classified into two types: analogue image processing and digital image processing. Hard copies, such as prints and pictures, can benefit from analogue image processing. Digital image processing techniques aid in the alteration of digital pictures through the use of computers.
The scope of this blog is limited to digital image processing only but still, let's see a little history of image processing. One of the early uses of images was in the newspaper industry when images were transmitted by undersea cable between London and New York. In the early 1920s, the introduction of the Bartlane cable image transmission system lowered the time necessary to convey a picture over the Atlantic from more than a week to less than three hours. Images were coded for cable transmission and recreated at the receiving end using specialized printing equipment.
Since then image processing has been a constantly growing field. Over the last five years, there has been a considerable surge in interest in picture morphology, neural networks, full-color image processing, image data compression, image recognition, and knowledge-based image analysis systems.
In this blog, we are going to cover the basics as well as advanced concepts related to image processing.
The blog will touch on the following topics:
- What is an Image?
- What is an Image processing
- Why we need Image processing
- Real World Applications of Image Processing
- Conclusion
What is an Image?
An image is defined as a two-dimensional function, F(x,y), where x and y are spatial coordinates, and the amplitude of F at any pair of coordinates (x,y) is referred to as the image's intensity at that location. In other words, a picture may be characterized as a two-dimensional array specially structured in rows and columns.
We call it a digital picture when the x,y, and amplitude values of F are finite. The digital image is made up of a finite number of elements, each with its own location and set of values. These elements are known as picture elements, image elements, and pixels. Pixels are the elements of a computer picture.
What is an Image processing?
Digital Image Processing is the process of obtaining a picture of the region containing the text, preprocessing that image, extracting the individual characters, describing the character in a form appropriate for computer processing, and identifying those individual characters.
The basic phases in image processing are as follows:
- Importing the picture using an image capturing software
- Image analysis and manipulation
- Creating an output, which might be an edited image or a report based on the image analysis.
Computers are used to edit digital photographs using digital image processing techniques. Any form of data must go through three main steps while being processed digitally. These include pre-processing, display and enhancement, and extraction of data.
Why do we need Image processing?
Image processing is commonly thought to be the arbitrary manipulation of pictures for the sake of aesthetics or to promote the desired reality. However, a more true description would be a method of translating between the human visual system and digital imaging sensors, because the human visual system does not experience the environment in the same way as digital detectors do.
Image processing is commonly used for the following purposes:
- Picture sharpening and restoration.
- Visualizing and observing items that are difficult to see.
- Image retrieval for searching high-resolution images.
- For identifying patterns and numerous other things in a picture.
The following example may help you understand why we employ and need image processing:
We all know that satellites are the most powerful and useful tool for gathering information about the universe and the earth. Many decisions that are not taken directly with assumptions are made using images provided by satellites. However, images provided by satellites are in the form of RGB combinations, and thus we must convert them into their appropriate color combination as well as a format at the time image processing is performed. Satellites transmit images or data as digital signals, which computers process. Additional noise and bandwidth constraints are imposed by digital detectors.

Figure: Steps in satellite image processing
picture-source: researchgate.net
Real World Applications of Image Processing
Although there are many real-world applications for Image processing. A few of the prominent and the most commonly known are listed below:
- For Traffic Sensing: A video image processing system, or VIPS, is used in the situation of traffic sensors. This is made up of three parts: a) an image capture system, b) a communications system, and c) an image processing system. When collecting video, a VIPS has many detecting zones that emit an "on" signal when a vehicle enters the zone and an "off" signal when the vehicle departs the zone. This helps in detecting any irregularities in the vehicle and in the traffic as well.

Figure: Traffic control using Image Processing
- Medical Field: Image processing has several medicinal uses, including ultraviolet imaging, CT Scanners, MRI, PET scanning, X-ray examination, and Imaging using gamma rays.
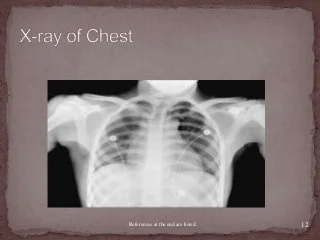

Figure: Use of Image Processing for X-ray and MRI.
- Facial Recognition: Image processing is often used for facial recognition. The computer is initially taught the characteristics of human faces. It learns descriptive features such as the distance between the two eyes and the average human face shape, which are used as metrics to form the face shape.

Figure: General schema for face recognition using image recognition
picture-source: researchgate.net
- Image Restoration: Picture processing can be used to restore and fill in missing or corrupted image components. Image processing algorithms that have been thoroughly trained with existing picture datasets are used to build newer copies of old and damaged photographs.

Figure: Use of Image Processing for Restoring a degraded image.
Apart from the above-listed applications, image processing has wide use in various other fields such as heart disease identification, lung disease identification, and for analyzing mammograms to detect breast tumors.
Conclusion
With the introduction of fast and inexpensive equipment, image processing has become an extremely popular topic of research and practice. It offers cost-effective solutions to a wide range of real-world applications. Various strategies for developing intelligent systems have been created, and many of them are currently in use at various research institutions throughout the world. The future of digital image processing is likely to contribute to the creation of a smart and intelligent world in areas such as health, education, defense, traffic, residences, offices, cities, and so on.
We hope that this blog was able to give you some basic information on image processing, including its history, needs, methodology, duties, and applications. The primary goal addressed here is to provide anyone interested in this field with some deep knowledge of image processing.