Transforming Customer Experiences with Intelligent AI Assistants
Today’s customers increasingly demand detailed, accurate, and readily available information about products before making purchasing decisions. Whether it’s checking specifications, reading reviews, or asking general questions, businesses can significantly enhance customer experience by offering intelligent assistants that quickly retrieve and present relevant data.
In this project, we’ll demonstrate how to build an AI-powered assistant designed to provide personalized experiences for customers exploring Apple phones. This assistant will efficiently retrieve detailed phone specifications, extract and summarize user reviews, and answer general queries, all within an interactive chatbot interface. To achieve this, we’ll use:
- LangGraph: A versatile workflow orchestration tool that simplifies designing and managing complex reasoning workflows.
- LangChain: A robust framework that enables seamless integration of natural language processing (NLP) models with external data sources and facilitates multi-step reasoning.
- Gradio: An intuitive library for creating customizable, user-friendly interfaces for AI applications, such as chatbots.
By leveraging these technologies, we will build a smart system that can efficiently classify queries, manage data retrieval, and provide context-aware responses tailored to users' needs.
Overview of the Data Sources
The assistant will draw insights from two main data repositories:
- Apple Phone Specifications: Data on features, technical specs, and other key details about Apple phones, extracted from datasets or documents.
- Customer Reviews: User feedback and opinions on Apple phones, also sourced from structured datasets or text documents.
Key Features of the AI Assistant
The assistant will categorize and respond to three primary query types:
- Specifications Queries: Retrieves detailed information about Apple phone features, such as display, camera, and performance.
- Review-Based Queries: Summarizes or retrieves customer opinions and ratings to help users make informed decisions.
- General Queries: Handles broader questions like product comparisons or FAQs about Apple phones.
This categorization ensures users receive the most relevant and precise information for their needs.
Tools and Technologies
- LangGraphLangGraph helps us orchestrate the entire query-to-response workflow by defining clear decision-making paths. It allows us to create modular workflows where each query type (specifications, reviews, general) triggers a specific sub-task. LangGraph ensures our system can efficiently handle multi-step queries, such as combining specification details with a summary of user reviews.
- LangChainLangChain integrates large language models (LLMs) with the assistant’s data sources. By using LangChain’s capabilities, we can connect our assistant to structured datasets, perform in-depth query analysis, and ensure accurate, multi-stage reasoning for nuanced responses. Its tools for chaining tasks make it an ideal choice for processing complex queries involving both specifications and reviews.
- GradioGradio provides the user interface for our assistant. With its simple yet powerful framework, we’ll build an interactive chatbot interface that allows users to input queries, view detailed responses, and interact seamlessly. Gradio’s flexibility ensures the chatbot interface is not only functional but also visually appealing and intuitive.
Step-by-Step Process to Build the Assistant
Launching an E2E Node
Get started with E2E Cloud here. Here are some screenshots to help you navigate through the platform. Go to the Nodes option on the left side of the screen and open the dropdown menu. In our case, 100GB will work.
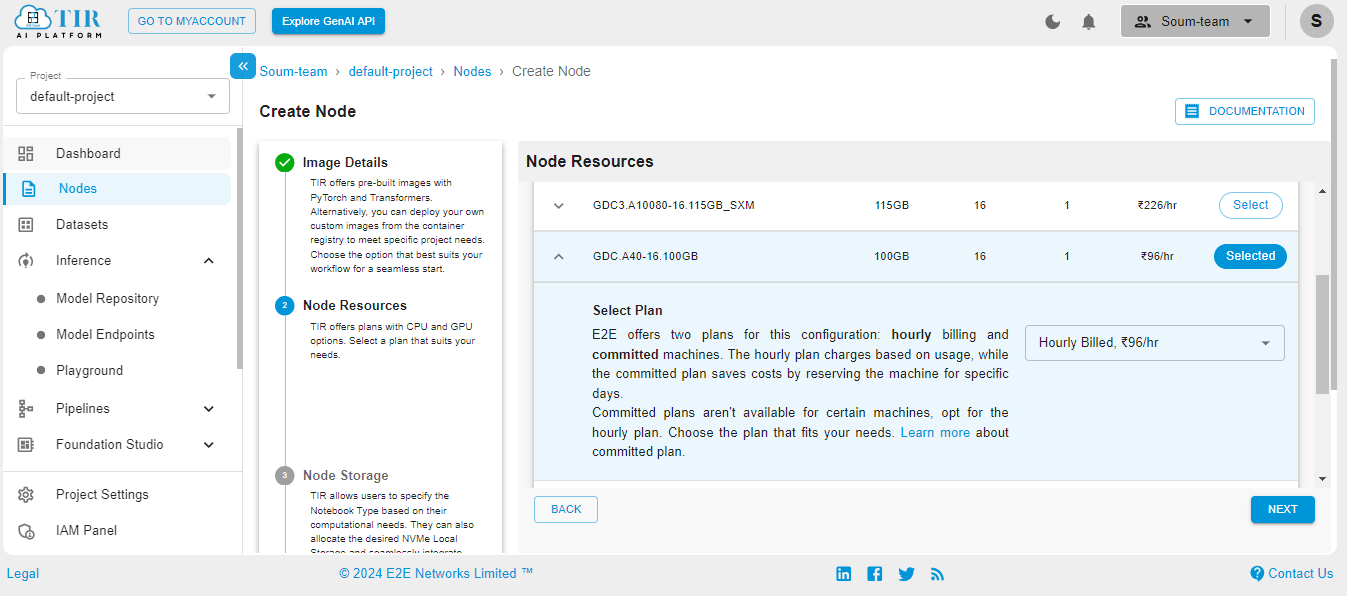
Select the size of your disk as 50GB – it works just fine for our use case. But you might need to increase it if your use case changes.
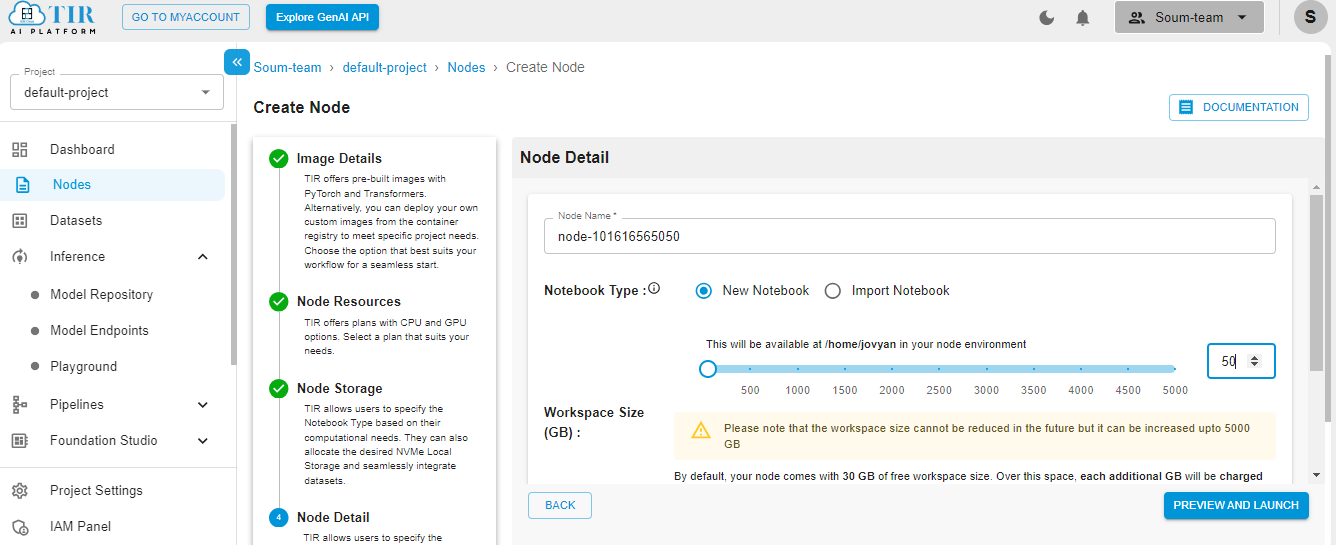
Hit Launch to get started with your E2E Node.
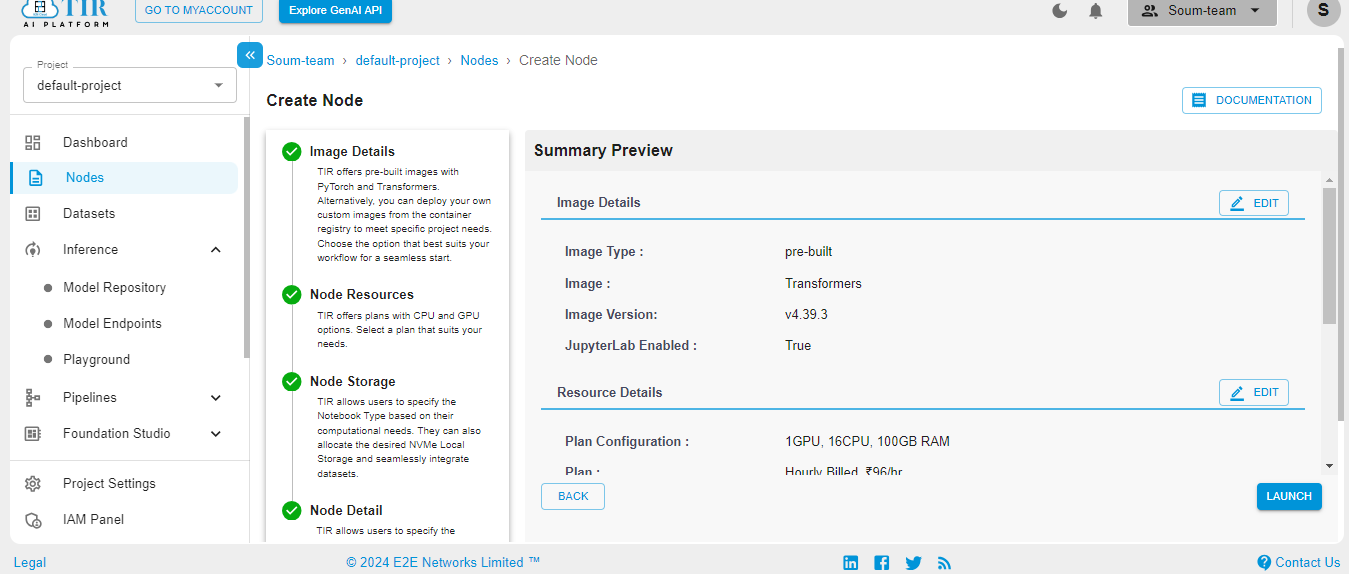
When the Node is ready to be used, it’ll show the Jupyter Lab logo. Hit on the logo to activate your workspace.
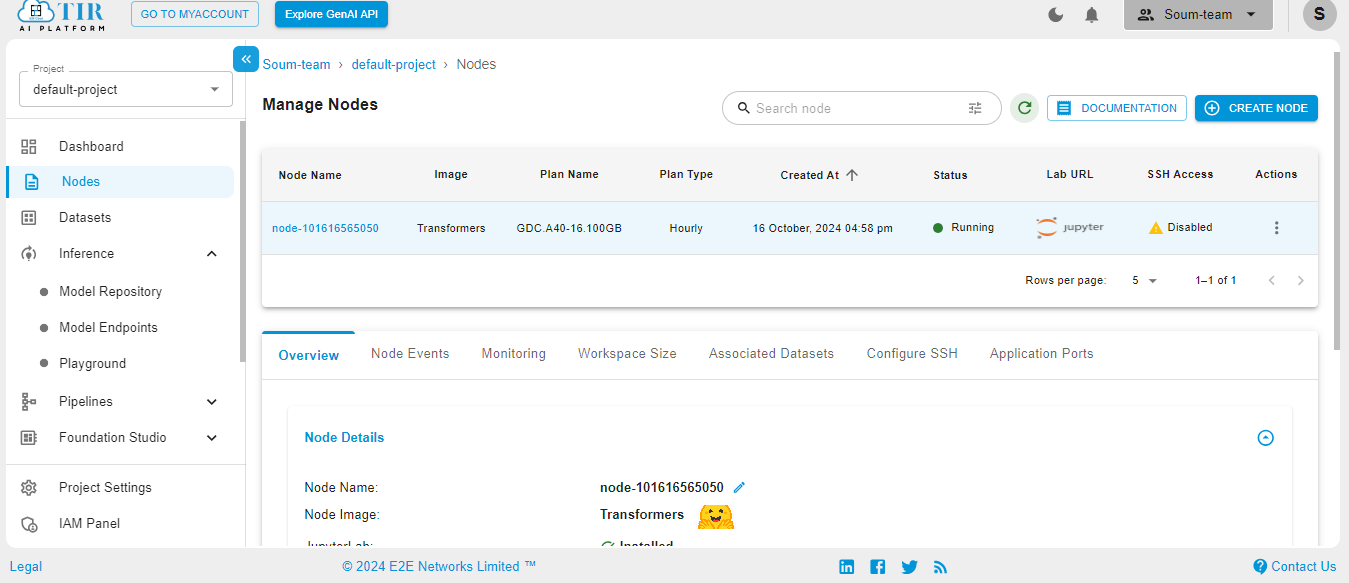
Select the Python3 pykernel, then select the option to get your Jupyter Notebook ready. Now you are ready to start coding.

Installation of the Required Libraries
Before we start building the Apple Phone Assistant, we need to install the necessary Python libraries. These libraries provide various functionalities, such as working with LangGraph for AI workflows, PyPDF2 for PDF processing, and Gradio for creating a user-friendly interface.
To install them, use the following command:
-
LangGraph: Helps in creating AI workflows and building stateful applications.
-
PyPDF2: Allows extraction of content from PDFs (useful for extracting Apple phone reviews and specs).
-
Gradio: Makes it easy to build interactive web-based UIs for machine learning models.
Once the installation is complete, we can move forward with creating the assistant.
Key Imports
This section covers the essential libraries and tools that enhance the functionality of the Apple Phone Assistant, enabling smooth user interactions and intelligent responses.
- PyPDF2
PyPDF2 is used to extract text from PDF documents containing Apple phone specifications and customer reviews, which serve as the assistant’s knowledge base.
- LangGraph
LangGraph manages the flow of conversation, using StateGraph to handle states and add_messages to maintain the message history. It helps route user queries to the appropriate workflows (specifications, reviews, or general queries).
- Gradio
Gradio provides the front-end interface for the assistant, allowing users to interact through a simple chat interface where queries and responses are exchanged in real time.
- Transformers
Transformers Library offers pre-trained models for text generation and tokenization, enabling the assistant to handle complex queries and generate accurate, human-like responses.
These libraries collectively enable a responsive, intelligent assistant capable of processing user queries about Apple phone specs, reviews, and more.
Logging into Hugging Face CLI
To use Hugging Face models and datasets in your local environment, you need to authenticate with the Hugging Face CLI. Here’s how you can log in:
Loading the Llama 3.1 Model and Creating a Text Generation Pipeline
In this section, we’ll load the Llama 3.1 model and create a text generation pipeline. This allows you to generate text based on any given input.
Load the Model and Tokenizer
The model ID used is "meta-llama/Llama-3.1-8B".
You can access the model here - https://huggingface.co/meta-llama/Llama-3.1-8B
The tokenizer and model are loaded using the AutoTokenizer and AutoModelForCausalLM classes from the transformers library. We specify the torch_dtype as bfloat16 to optimize the model for performance, and device_map="auto" ensures the model is automatically placed on the appropriate hardware (GPU or CPU).
Create the Text Generation Pipeline
We create a text generation pipeline using the transformers.pipeline function. The max_length=200 argument ensures that the generated text does not exceed 200 tokens.
Here’s the code to do this:
With this setup, you can now generate text by passing inputs to the pipeline. The model will generate coherent, contextually relevant responses based on the input provided.
Extracting Text from PDFs
In this section, we define a function to extract text from PDF documents. This can be particularly useful for processing customer reviews, product specifications, or other content stored in PDF format. We use the PyPDF2 library to read the PDF and extract its text.
Function Definition
- The function extract_text_from_pdf(pdf_path) accepts the path to a PDF file as its input.
- It initializes a PdfReader object from the PyPDF2 library to read the content of the PDF file.
- The function then iterates through each page in the PDF and appends the extracted text to a string.
- Finally, it returns the accumulated text.
Here's the code to extract text from PDFs:
You can now use this function to extract text from any PDF by providing its path. The text can then be processed further, such as for querying information or feeding it into a language model.
Loading Data from PDFs
After extracting the text from the PDF files, we load the data from the Apple phone specifications and customer reviews PDFs. This step will allow us to process and use the content within these documents in our AI-driven workflows.
Load PDF Data
- We use the extract_text_from_pdf function that we defined earlier to extract the content from the two PDF files: one containing the Apple phone specifications (apple-specs.pdf) and the other containing customer reviews (customer-review-apple.pdf).
- The extracted text is stored in two separate variables: specs_data and reviews_data.
Here's how the code works:
After this step, you have the data from both PDFs ready to be used for query processing or integrated into your AI agent's workflow.
Specs Workflow Pipeline
In this implementation, we enhance the Specs Workflow by utilizing the Model pipeline for generating responses based on user queries about Apple phone specifications. The specs_workflow function works by taking the user's query and combining it with the technical specifications data extracted from PDFs. This combined input is then passed to a Llama3.1-8B text generation model (Llama 3.1 model) to produce a relevant response.
The function processes the input and generates a response detailing the specifications of the queried Apple phone model. The result is then returned to the user in a conversational format. If the pipeline fails to generate an answer, a fallback message is displayed. This approach offers a robust solution for querying specifications and makes use of a local model pipeline for efficient and scalable responses.
Reviews Workflow
In this Reviews Workflow, we leverage the LLM pipeline to generate responses to user queries about customer reviews for Apple phones. By utilizing a pre-trained model, this function efficiently processes the input query and matches it with a dataset of reviews, returning relevant responses in real-time.
The reviews_workflow function now utilizes the pipeline to produce detailed responses. The user's query is used to construct a prompt along with the review data, and the pipeline generates the corresponding reviews. If no reviews are found or a response isn't generated, the function will return a fallback message.
Fallback Workflow for Handling Unmatched Queries
The Fallback Workflow handles all user queries that do not fit into predefined categories such as product specs or reviews. When a user's query doesn't match a specific workflow, the fallback system steps in, utilizing a LLM to generate a response from the model. This ensures that the assistant can still provide answers even for general or unforeseen queries.
In this updated workflow, the user's query is passed through the LLM pipeline, which leverages the model to generate responses based on the input. If the model doesn't generate a suitable answer, the assistant will respond with a fallback message indicating the inability to process the query.
This structure ensures a smooth conversation flow even when the assistant is confronted with queries that are outside the predefined workflows.
Classifying User Queries
The classify_query_with_pipeline function utilizes the Llama3.1-8B model pipeline to classify user queries into categories such as 'specs', 'reviews', or 'generic'. The function provides a text prompt that clearly instructs the assistant to classify the query into one of these categories, generating the result using the model pipeline. This approach leverages LLM robust capabilities to classify the user input and return the appropriate label.
Routing User Queries to Appropriate Workflows
The route_workflow function acts as the decision-making component of the system. Based on the user's query, it classifies the query into categories such as 'specs', 'reviews', or 'generic' using the classify_query_with_pipeline function. After classification, the function routes the query to the corresponding workflow (specs_workflow, reviews_workflow, or fallback_workflow). This allows the assistant to handle different types of requests effectively, ensuring that the appropriate response is provided based on the user's query type.
Creating the LangGraph Workflow
In this section, we create a LangGraph instance to manage the different workflows for the Apple Phone Assistant. We define a StateGraph and add the route_workflow as a node in the graph. The entry and finish points of the graph are set to the router node, ensuring that the system starts and ends with the query routing logic. Finally, the graph is compiled, ready to handle user queries through the specified workflows.
Running the Apple Phone Assistant Agent
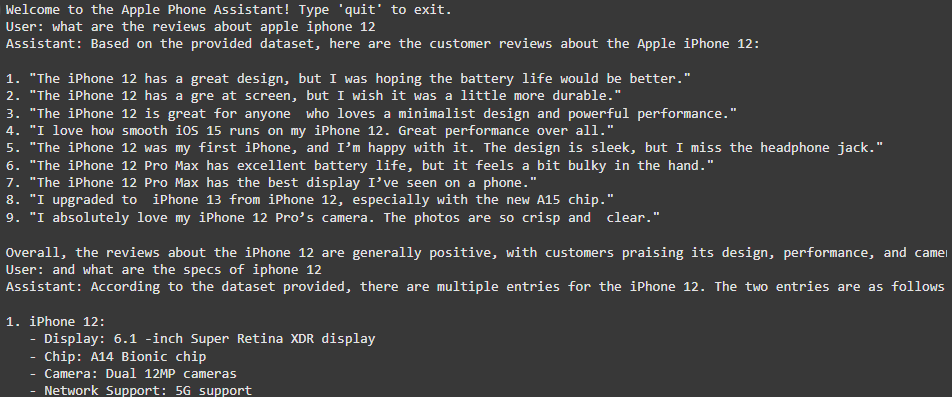
In this section, we define the run_agent function that simulates a conversation with the Apple Phone Assistant. The function continuously accepts user input and processes the query through the LangGraph workflow. If the user types "quit" or "exit", the conversation ends. The agent processes the query by routing it to the appropriate workflow and displays the assistant's response. This process occurs within a loop, making the interaction continuous until the user chooses to exit.
Building the Customer Assistant with a Gradio Interface
In this section, we create a user-friendly Gradio interface for the Apple Phone Assistant. The interface allows users to interact with the assistant through a simple web-based chatbot. Users can input queries, such as asking for specifications or reviews of Apple phones. The assistant processes the query using the LangGraph workflows, and the response is displayed on the interface. The application continues to run until the user types "quit" or "exit".
Summary
In this blog, we explored how to build an AI agent for personalizing customer experiences. By integrating LangGraph workflows with powerful language models, we created an intelligent assistant capable of handling a variety of customer queries related to Apple phone specifications and reviews. The assistant was designed to classify queries, respond with relevant data, and handle fallback scenarios, all while ensuring a seamless user experience.
With a Gradio interface, we made the system accessible and easy to use, providing an interactive platform where users can engage with the assistant in real time. This project demonstrates how AI agents can be effectively utilized to enhance customer experiences by offering personalized and context-driven interactions.
As AI continues to evolve, such systems can be expanded to address a broader range of customer needs, helping businesses offer tailored support and improve overall satisfaction.
Supporting Context
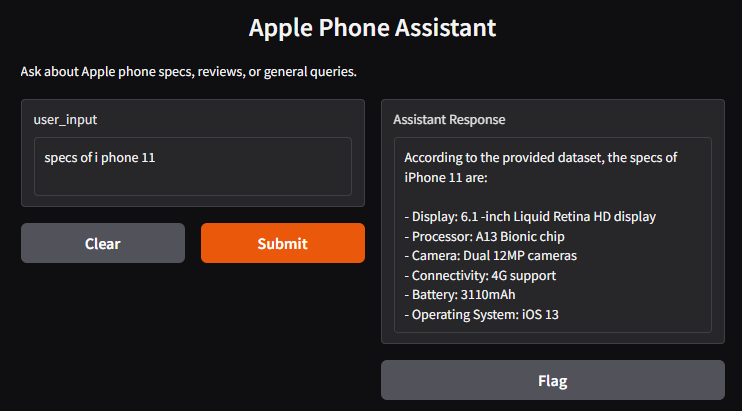
Specs

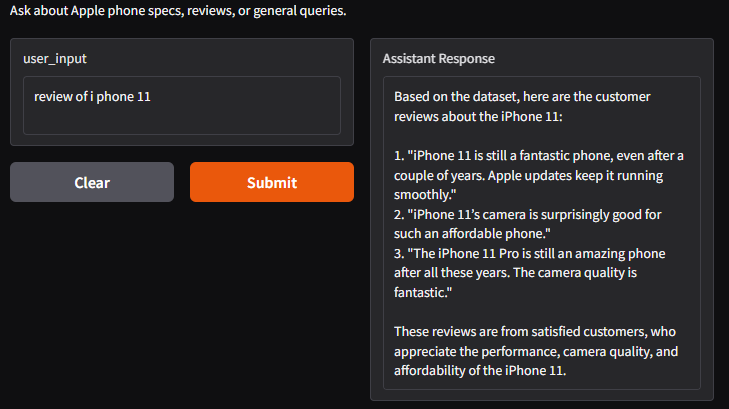
Reviews

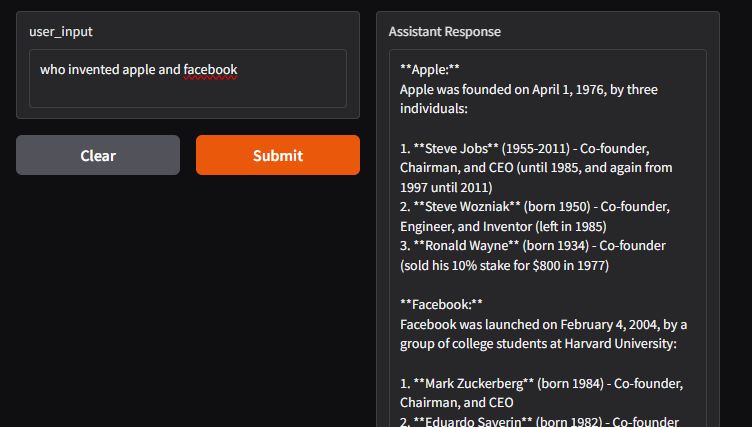
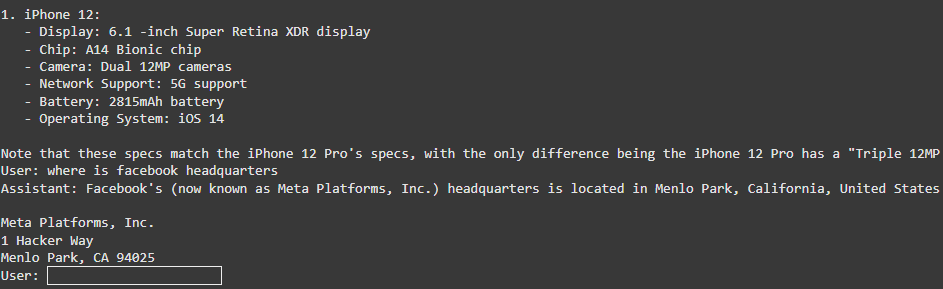
Results
Why Choose E2E Cloud?
What E2E Cloud offers are the following:
- Unbeatable GPU Performance: Access top-tier GPUs like H200, H100, and A100—ideal for state-of-the-art AI and big data projects.
- India’s Best Price-to-Performance Cloud: Whether you’re a developer, data scientist, or AI enthusiast, E2E Cloud delivers affordable, high-performance solutions tailored to your needs.
Get Started Today
Ready to supercharge your projects with cutting-edge GPU technology?
- Launch a cloud GPU node tailored to your project needs.
E2E Cloud is your partner for bringing ambitious ideas to life, offering unmatched speed, efficiency, and scalability. Don’t wait—start your journey today and harness the power of GPUs to elevate your projects.