As the AI landscape transforms, large models designed for specialized tasks like image parsing have become essential for industries ranging from autonomous driving to medical imaging. One such breakthrough model, Pixtral-12B, brings unprecedented precision and efficiency in understanding and extracting information from complex images.
In this blog, we will dive into how to deploy Pixtral-12B using the vLLM framework on the TIR AI platform. This guide will take you through the steps, including setting up the model, launching it in your environment, and using it for advanced image parsing tasks. Whether you're an AI enthusiast or a professional seeking to enhance your projects with cutting-edge technology, this blog will provide all the information you need to get started.
Get ₹2,000 free credits to test your AI workloads
Sign up and complete ID verification to unlock free credits. Deploy on NVIDIA H200, H100, and L40S GPUs—no commitment required.
Quick Overview of Pixtral-12B
Pixtral 12B is a cutting-edge multimodal language model developed by Mistral, featuring 12 billion parameters. This model is designed to process and understand both images and text, making it versatile for various applications in natural language processing and computer vision.
Key Features
- Multimodal Capabilities: Pixtral 12B can handle tasks involving both text and images, such as answering questions about images, captioning, and object recognition.
- Architecture: It includes a 400 million parameter vision encoder trained from scratch, allowing it to process images at their native resolution and aspect ratio. This flexibility supports a long context window of 128K tokens, enabling the model to analyze multiple images simultaneously.
- Performance: The model has demonstrated superior performance on various multimodal benchmarks, outperforming larger models while being significantly smaller in size. For instance, it achieved a score of 52.0% on the MMMU reasoning benchmark, surpassing many competitors.
Applications
Pixtral 12B excels in tasks such as:
- Image Captioning: Generating descriptive text based on visual input.
- Document Understanding: Interpreting charts, figures, and answering questions related to documents.
- Instruction Following: Effectively executing commands that involve both text and visual elements.
Availability
Pixtral 12B is open-source and available under the Apache 2.0 license, allowing users to download, fine-tune, and deploy the model without restrictions. It can be accessed via platforms like GitHub and Hugging Face.
Why Is vLLM Useful in Production Environments?
vLLM, or Virtual Large Language Model, is a specialized library designed to efficiently serve large language models (LLMs) in production environments. It addresses common challenges associated with deploying LLMs, such as high memory consumption and latency issues, by implementing advanced memory management and dynamic batching techniques.
Core Features
- Optimized Memory Management: vLLM employs sophisticated strategies for memory allocation, allowing it to maximize the use of available hardware resources and execute large models without encountering memory bottlenecks.
- Dynamic Batching: The library adjusts batch sizes and sequences dynamically, improving throughput and reducing latency during inference tasks. This flexibility enables better performance tailored to the specific capabilities of the hardware being used.
- Modular Design: Its architecture is modular, facilitating easy integration with various hardware accelerators and scaling across multiple devices or clusters. This adaptability makes it suitable for diverse deployment scenarios.
- High Throughput: vLLM is designed to provide high serving throughput, making it capable of handling numerous simultaneous requests efficiently.
Use Cases
vLLM can be utilized in various applications, including:
- Building API Servers: It can serve as an API server for LLMs, allowing users to interact with models via HTTP requests.
- Offline Inference: Users can run batched inference on datasets, generating outputs for multiple prompts simultaneously.
- Integration with Existing Frameworks: vLLM can be integrated into popular machine learning frameworks like PyTorch and TensorFlow, enhancing their capabilities for serving large models.
Get ₹2,000 free credits to test your AI workloads
Sign up and complete ID verification to unlock free credits. Deploy on NVIDIA H200, H100, and L40S GPUs—no commitment required.
Let’s Get Started with TIR
You can get started with the TIR AI / ML Platform here. Here are some screenshots to help you navigate through the platform.
Go to the Nodes option on the left side of the screen; you can choose VLLM Image from the options. This is needed for our use case.

You can choose a GPU option from here.
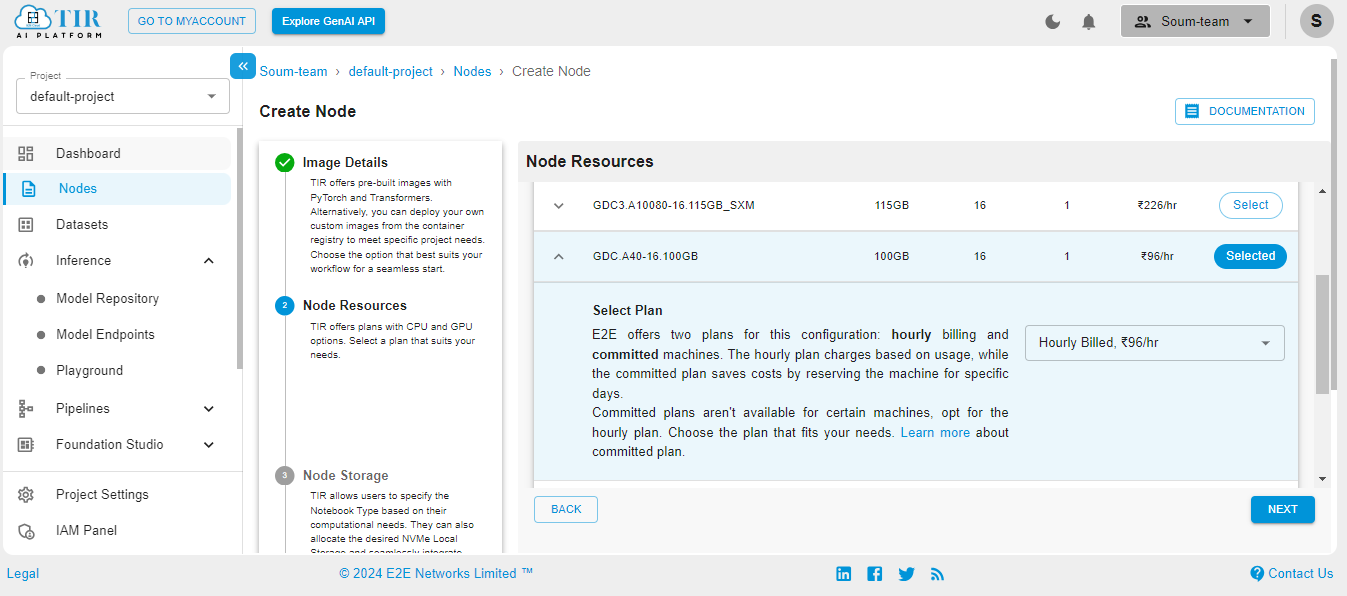
Select the size of your disk as 50GB – it works just fine for our use case. But you might need to increase it if your use case changes.
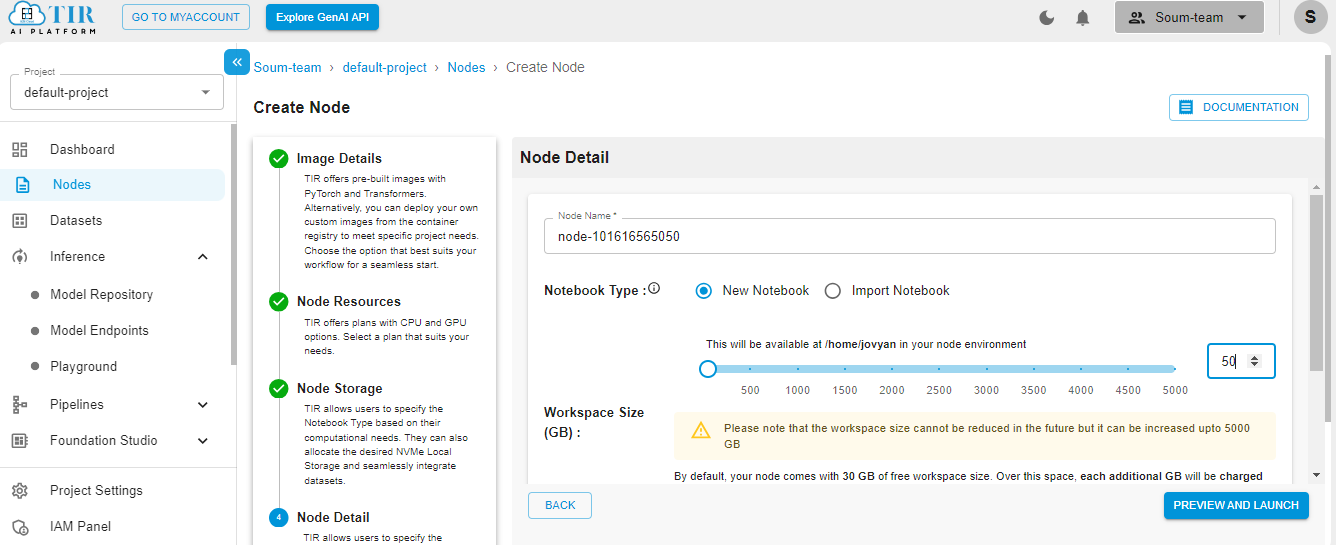
Hit Launch to get started with your TIR Node.
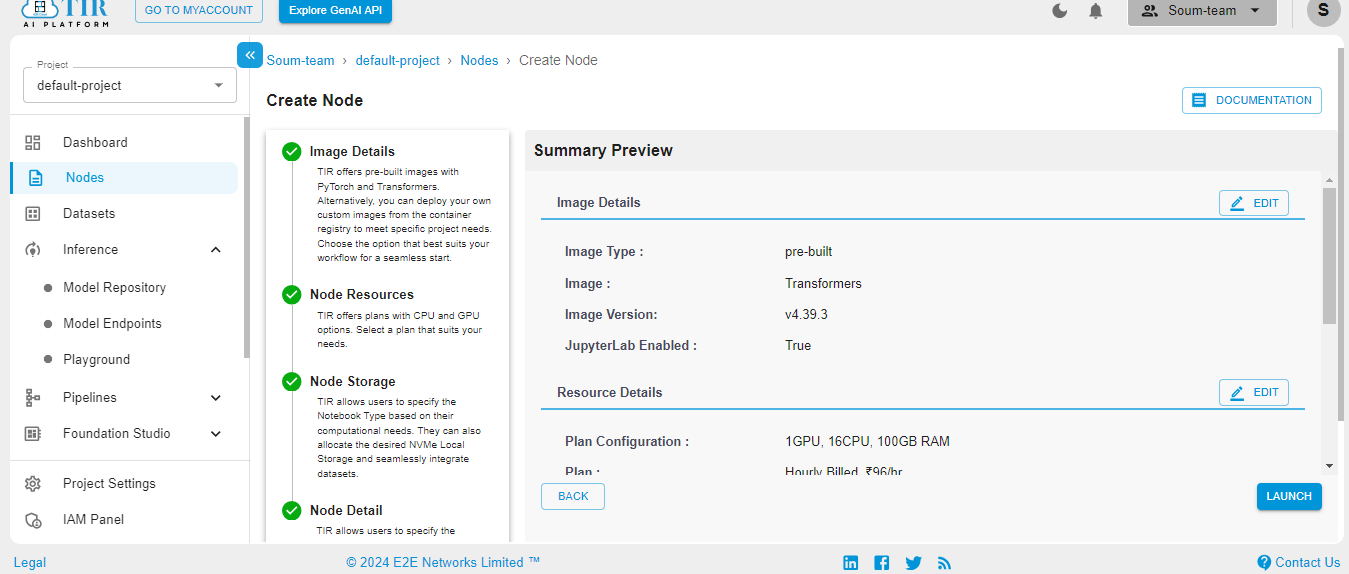
When the Node is ready to be used, it’ll show the Jupyter Lab logo. Hit on the logo to activate your workspace.
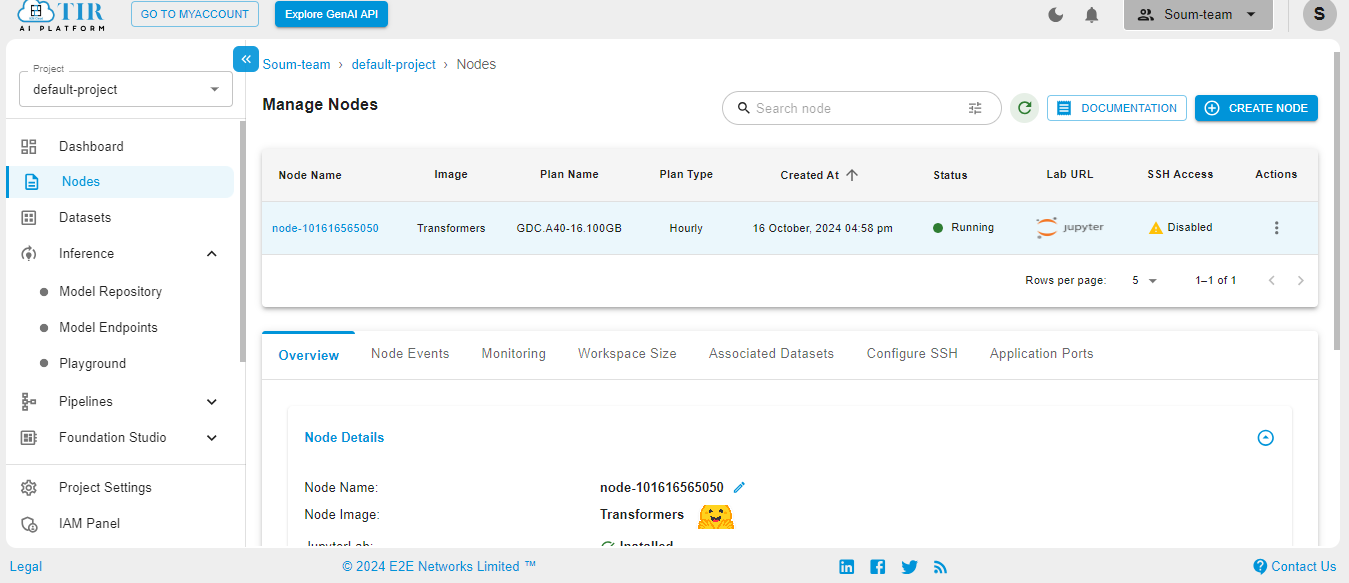
Select the Python3 pykernel, then select the option to get your Jupyter Notebook ready. Now you are ready to start coding.

Since we have our notebooks ready, let’s code.
Let’s Code
Step 1 - Prerequisites
Our first step is to create a virtual environment, then install the required libraries. We will assume that you have done so, and launched a Jupyter Notebook on your chosen cloud or your laptop.
!pip install vllm
!pip install --upgrade mistral_commonPixtral requires the mistral_common library, so let’s install that.
Next, let’s import the modules.
from vllm import LLM
from vllm.sampling_params import SamplingParams
from dotenv import load_dotenv
import os
import gradio as grWhat’s the use of the following imports?
- from vllm import LLM Imports the LLM class for interacting with the VLLM language model.
- from vllm.sampling_params import SamplingParams Imports SamplingParams for configuring sampling options when generating text.
- from dotenv import load_dotenv Imports the load_dotenv function to load environment variables from an .env file.
- import os Imports the os module for interacting with the operating system, such as handling file paths.
- import gradio as gr Imports Gradio as gr for creating user interfaces for machine learning models.
Now let’s load the environment variables for each use case.
load_dotenv()To install Pixtral-12B locally, we will use vLLM. Also, let’s import the libraries.
from huggingface_hub import notebook_login
notebook_login()
llm=LLM(
model="mistral-community/pixtral-12b-240910",
tokenizer_mode="mistral",
max_model_len=4000
)Step 2 - Context Extraction from the Given Image URL
Let’s write a function that will invoke the Pixtral-12B model with a prompt where we pass the image URL. Yes, you can either directly pass the image URL, or encode your image in Base64 format. Let’s do the former.
def generate_context(url, prompt = "Extract Text from the given image url precisely"):
messages = [
{
"role": "user",
"content": [
{"type": "text", "text": prompt},
{"type": "image_url", "image_url": {"url": url}}
]
}
]
outputs = llm.chat(
messages,
sampling_params=SamplingParams(max_tokens=8192)
)
return outputs[0].outputs[0].textThat’s all that’s needed!
Now, let’s try this out with a few images of bills (or invoices).
Step 3 - Bill Parsing
Here’s the first bill image we experimented with.

This is the extracted text using Pixtral-12B.
DOD FORM 1289
1 NOV 71
DOD PRESCRIPTION
FOR (Full name, address, & phone number) (If under 12, give age)
John R Doe, HM3, USN
U.S.S. Neverforgotten (DD 178)
MEDICAL FACILITY
U.S.S. Neverforgotten (DD 178) DATE 23 Jan 99
R (Superscription)
(Inscription)
Tm Belladonna 15 ml
Amphogel goat 120 ml
(Subscription)
M & FT Solution
(Signs)
Sig: 5 ml t.d. a.c.
MFGR: Wyeth EXP DATE: 12/02 LOT NO: P39X186 FILLED BY: RWT
Jack R Frost LCDR MD USNR
B NUMBER 10072 SIGNATURE RANK AND DEGREE
EDITION OF 1 JAN 60 MAY BE USED FOR S/N 0102 LF 012 8201
Extracted JSON using Pixtral-12B:
{
"DD": "1289",
"Form": "1289",
"Date": "1 NOV 71",
"Title": "DOD PRESCRIPTION",
"Patient": {
"Name": "John R Doe",
"Military Rank": "HM3",
"Military Service": "USN"
},
"Facility": {
"Name": "U.S.S. Neverforgotten",
"Code": "DD 178"
},
"Medical Facility": {
"Name": "U.S.S. Neverforgotten",
"Code": "OO 178",
"Date": "23 Jan 99"
},
"Prescription": {
"Superscription": "B",
"Incription": [
"Tm Belledonna - 15 ml",
"Amphogel hors 120ml"
],
"Subscription": "M + FT Solution",
"Signa": "Seq. 5 ml t.i.d a.c."
},
"Pharmacy Additional Info": {
"MFGR": "Wyeth",
"Lot No": "P39X106",
"Exp Date": "12/02",
"Filled By": "RMT"
},
"Prescriber": {
"Name": "Jack R Frost",
"Military Rank": "LCDR",
"Medical Degree": "MD",
"Military Service": "USNR",
"BN": "10072"
}
}As you can see, the extraction is quite accurate.
Join E2E Cloud Today
This project showed us how to deploy Pixtral-12B on the TIR AI platform using the vLLM framework. Whether you're an AI enthusiast or a professional aiming to elevate your projects with state-of-the-art technology, this guide will provide everything you need to get started.


