Five months ago, Mistral.AI published their strategic memo (see here) where they mentioned that they will become a key player in the generative AI industry, emphasizing on innovation, ethical deployment, and the ambition to rival large existing companies like OpenAI. Today, it’s LLM, the Mistral 7B stands amongst the topmost ranked 7 Billion parameter model there is. It even outperforms Meta’s LLaMa2 13B language model. So what’s all the hype about? Why is it so powerful? We will dive deeper in this interactive post where I have also illustrated a step-by-step guide on how we can implement it on E2E Networks’ TIR/AI platform.
E2E Networks is India’s largest hyperscaler equipped with state-of-the-art NVIDIA graphics card. They offer virtual machines for heavy AI/ML workloads.
What sets Mistral 7B Apart ?
Mistral 7-B is a lightweight large language model that is surprisingly robust and outperforms most of the best performing Language Models. It surpasses Meta’s LLaMa2 13B in text generation and LLaMa 34B in mathematical and code generation. It even approaches coding performance of Code-LLaMa 7B.
A high level overview of its architecture
It leverages Grouped Query Attention and Sliding Window Attention. Grouped Query Attention increases inference speed and reduces memory requirement during decoding allowing for higher batch sizes hence higher throughput. This helps in real time applications like building a conversational agent. In layman terms, it reduces both computational and time complexity.
Getting Started on E2E Networks’ TIR-AI
The TIR-AI platform on E2E Networks provides an interactive jupyter labs interface. TIR-AI is the built-in jupyter lab interface on E2E. What is unique about it is the fact that it comes with various python frameworks embedded in the notebooks as per your use case. Let’s get started:
Login to My Account and you will be directed to the dashboard.
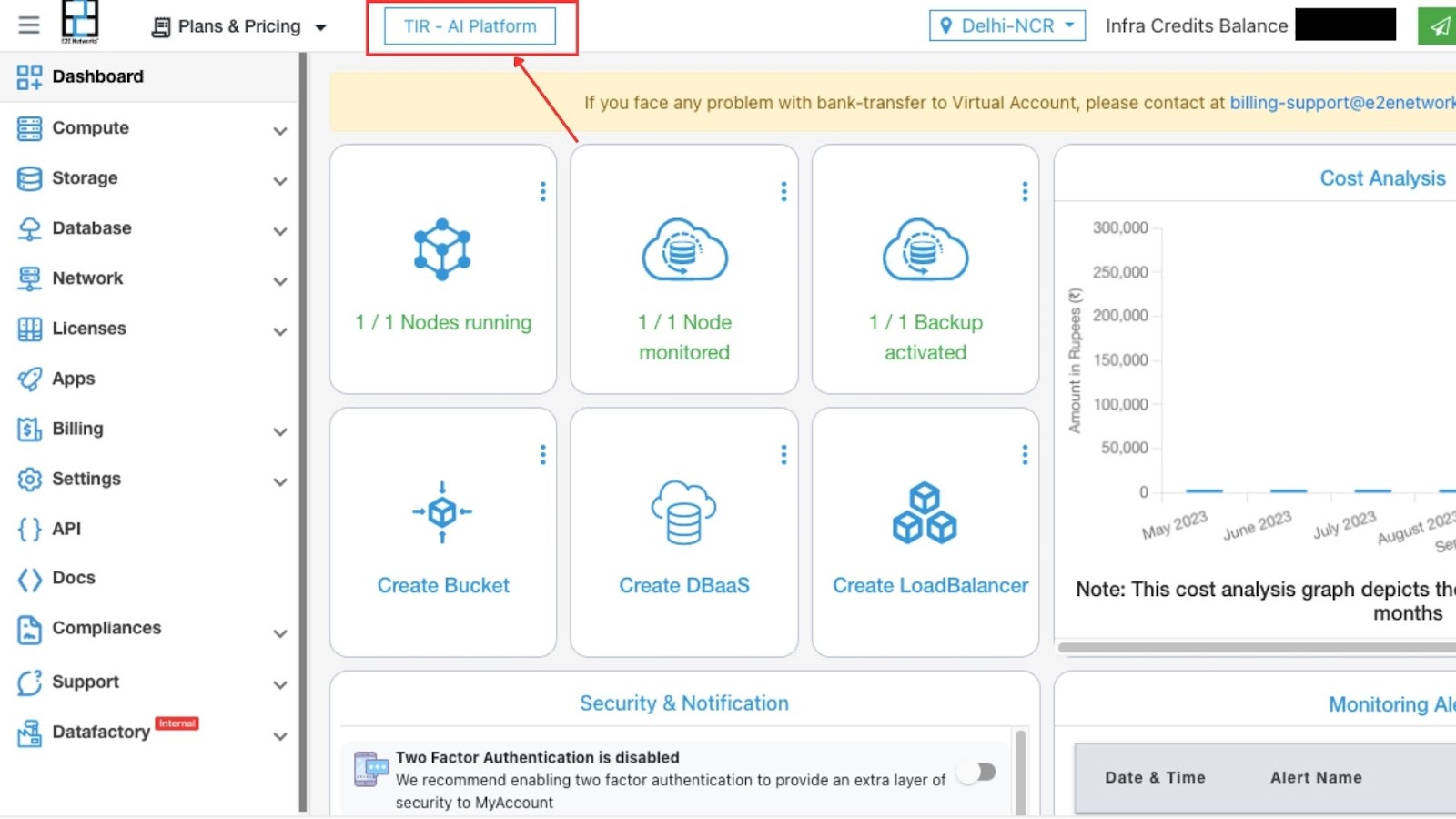
On clicking the TIR-AI Platform button we will be directed to the TIR-AI Platform

Hit on CREATE NOTEBOOK, and we will get the option to create a new jupyter notebook or import a notebook from an existing github repository.
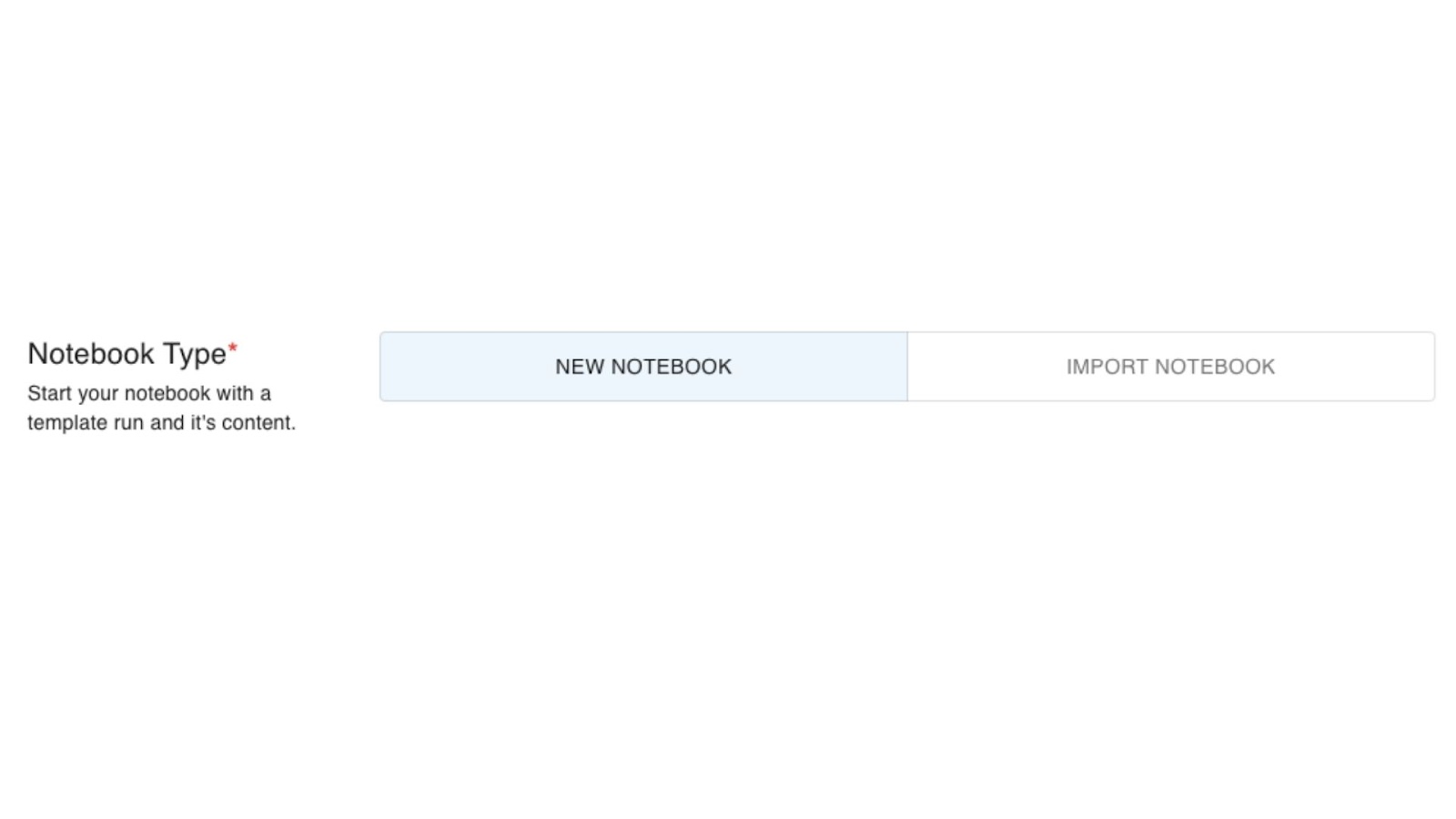
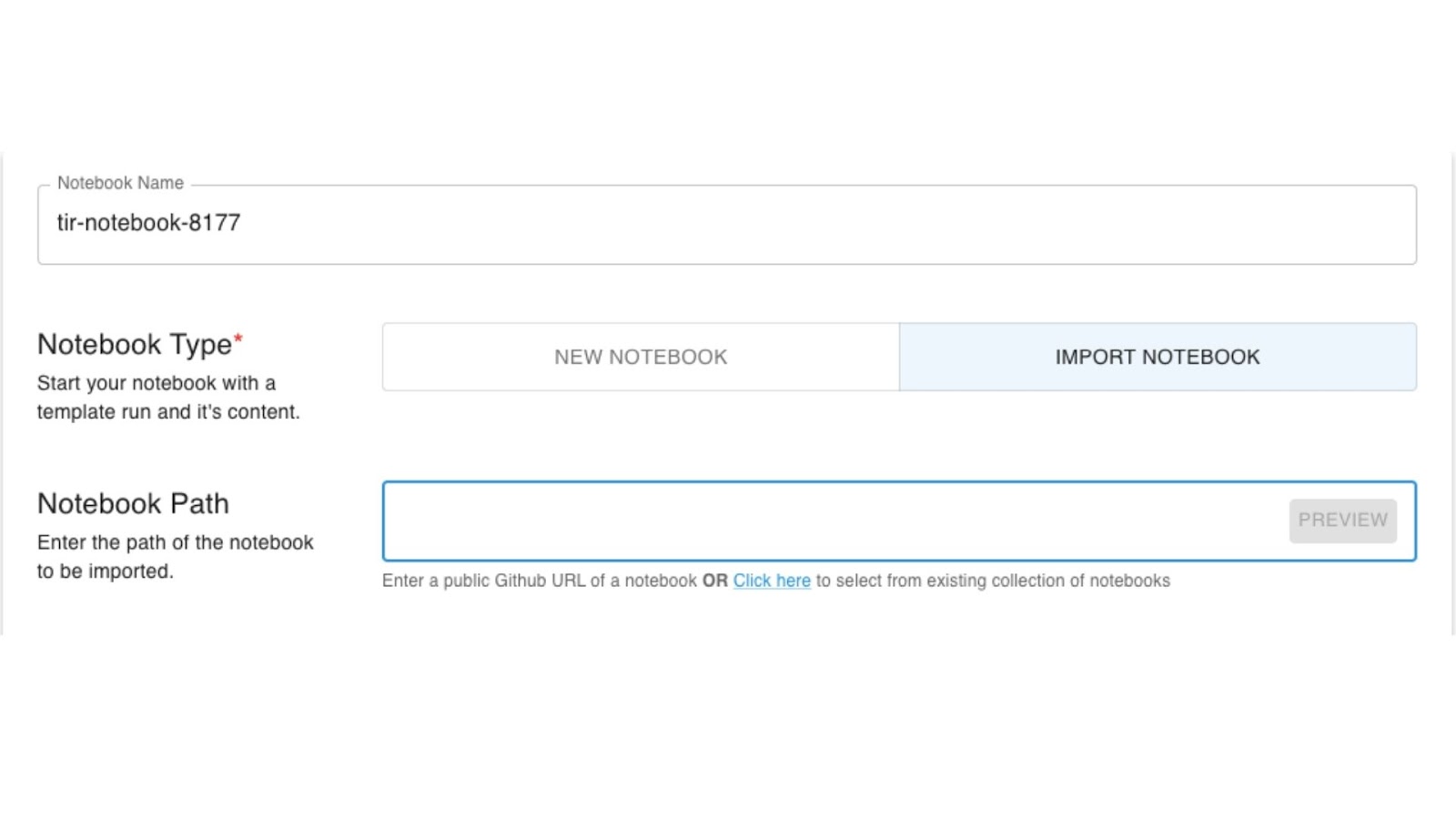
We can name the notebook anything of our choice. In this particular case the default name is ‘tir-notebook-8177’.
Then, most important, we can select the frameworks depending on our use case. For running Mistral-7B, we will be choosing PyTorch 2.

These are the various images available on TIR-AI.
Next, we choose the GPU/CPU Plan we wish to go with.
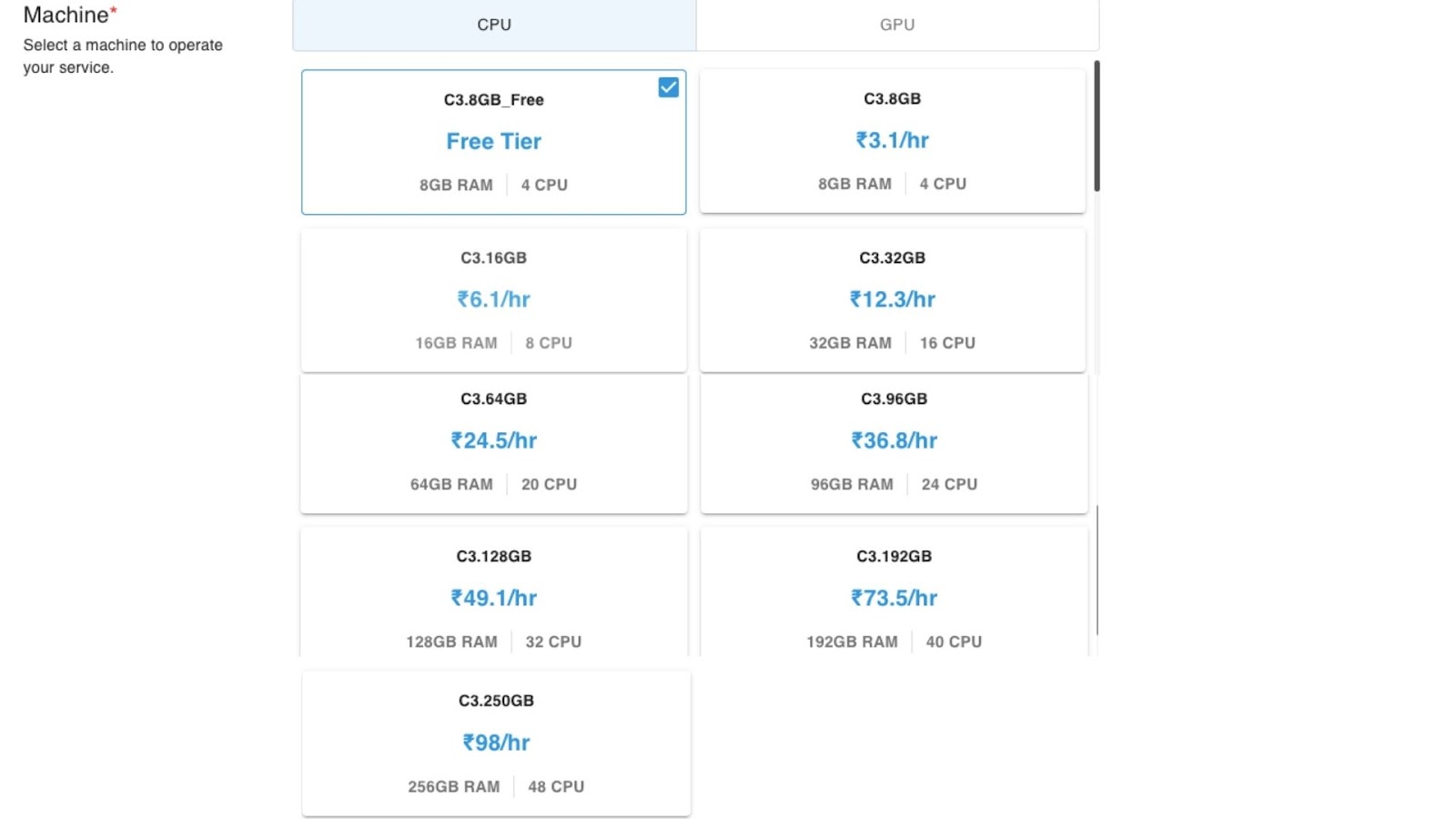
The above are the CPU Plans. The GPU Plans are listed below:
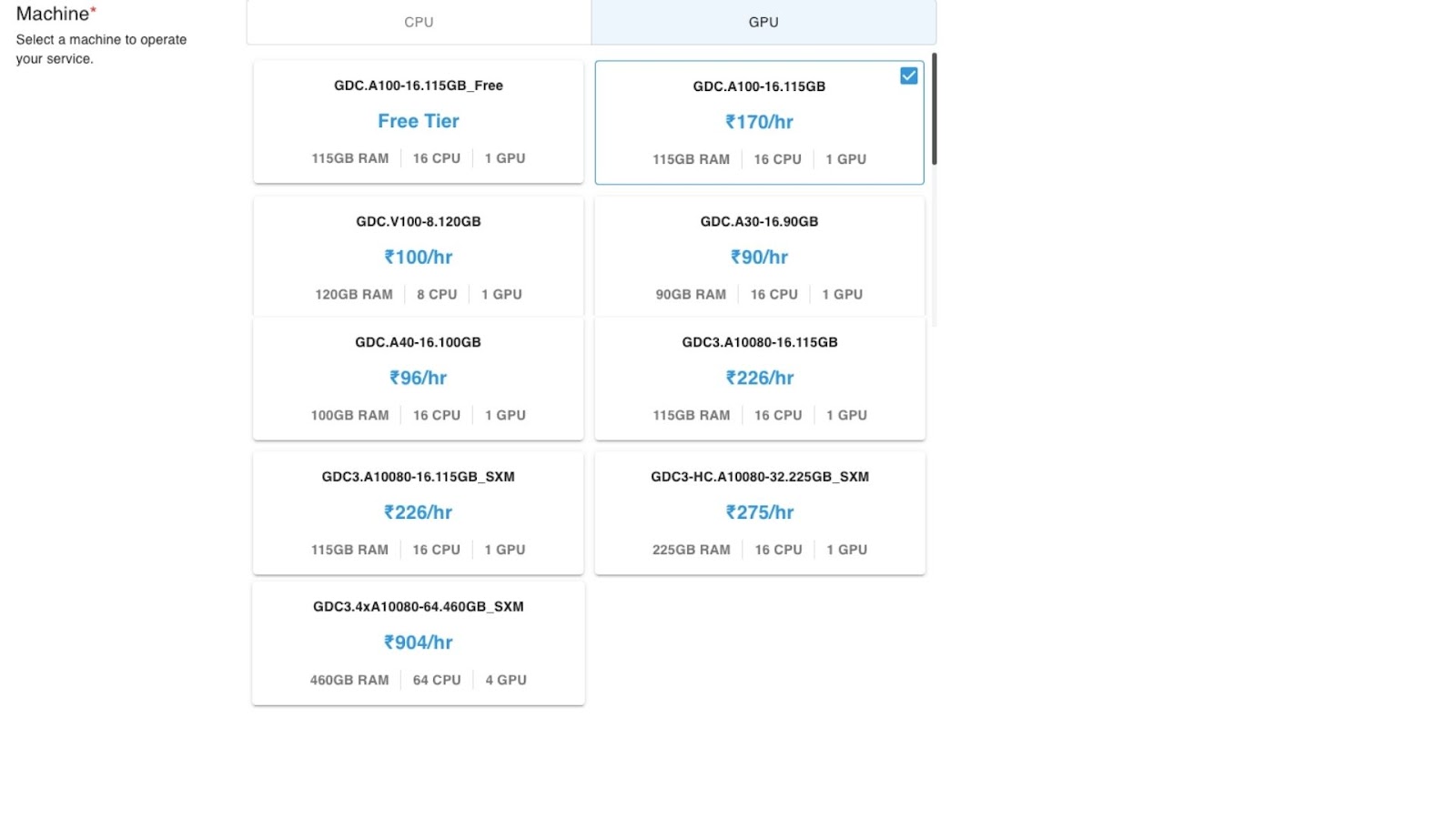
I went with the paid version of GDC.A100-16.115GB.
We also have the option to add our local system’s SSH keys.
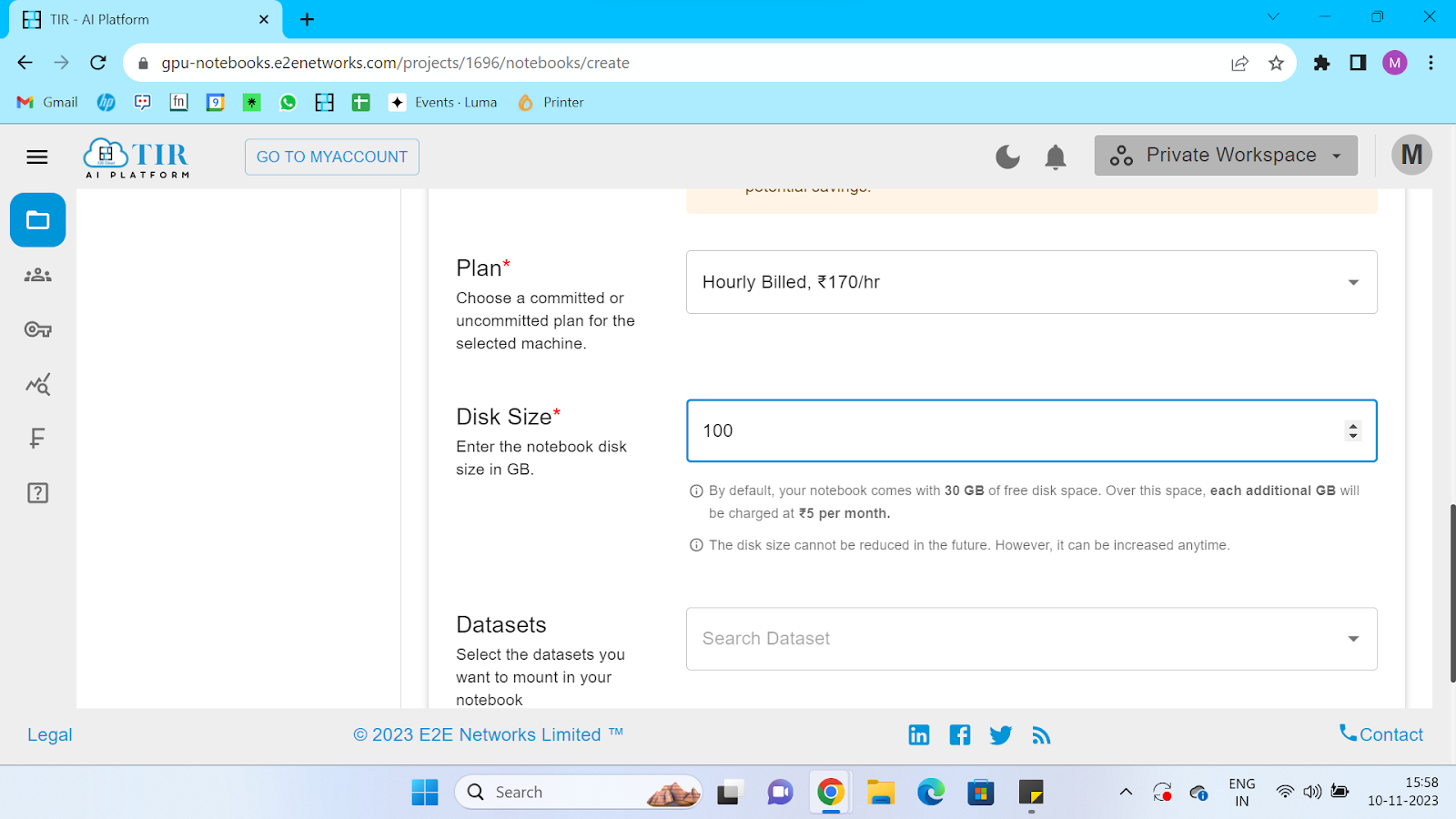
And then, we can create the notebook once all our options are selected. Select on the three dots when the notebook is running and click on Launch Notebook.
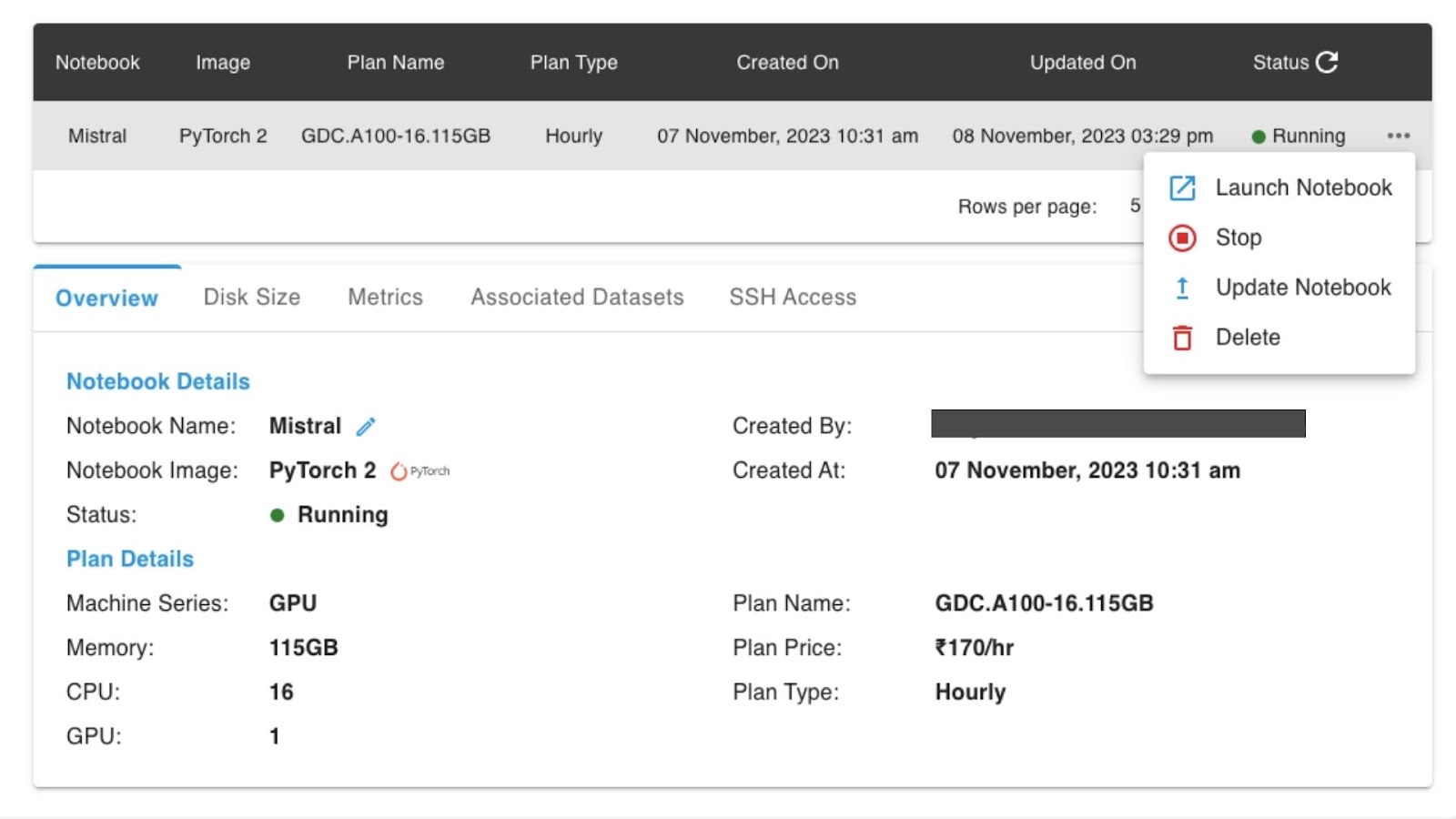
Now, the notebook is in the running stage.
Then we will be directed to the jupyter lab interface:
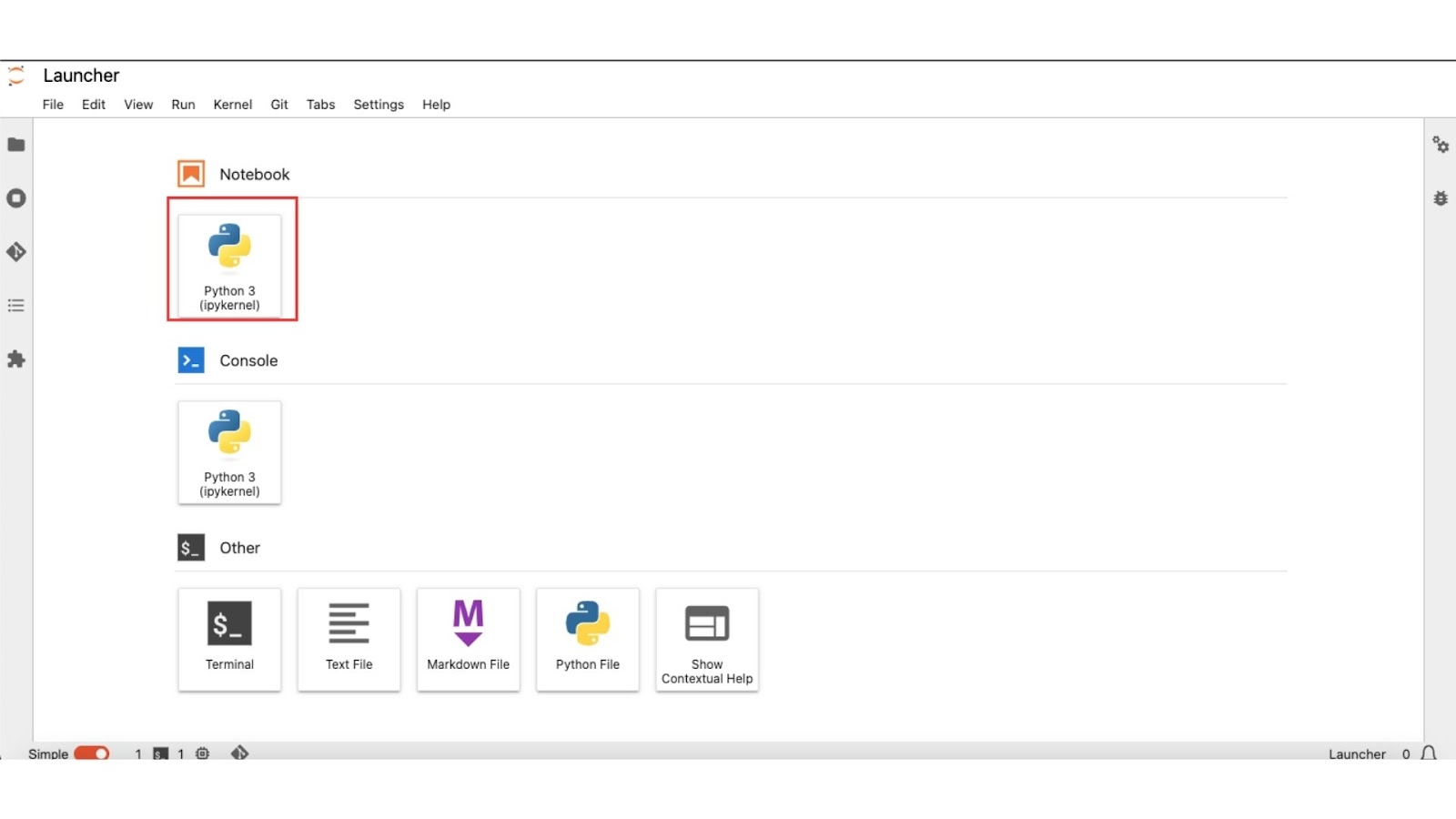
Click on Python 3 under Notebook. Now, we have finished setting up the jupyter lab. Now let us get into coding.
Problem Statement
We have already discussed the potentials of Mistral-7B. Now let us see what problem it can solve. I took a custom dataset of Sales-KRA from here. The problem most sales executives face when they are new to this field is, how to approach customers, how to generate leads, and many more. Here in this step-by-step guide, we will see a detailed walkthrough of how we can solve it by training the custom data with the Mistral 7B LLM.
Code Snippets
Step 1 : Install all the dependencies
!pip install -q -U bitsandbytes
!pip install -q -U git+https://github.com/huggingface/transformers.git
!pip install -q -U git+https://github.com/huggingface/peft.git
!pip install -q -U git+https://github.com/huggingface/accelerate.git
!pip install -q -U datasets scipy ipywidgets matplotlib
Press Shift + Enter
To get the sales KRA data run this command:
!git clone https://huggingface.co/datasets/AdiOO7/SalesKRA
Press Shift + Enter
Step 2 : Data Preparation
import json
import os
from sklearn.model_selection import train_test_split
# Path to your .jsonl file
file_path = 'SalesKRA/Dataset.jsonl'
# Directory to save the individual JSON files
train_dir = 'train_data'
val_dir = 'val_data'
# Make sure the directories exist
os.makedirs(train_dir, exist_ok=True)
os.makedirs(val_dir, exist_ok=True)
# Read the .jsonl file and collect the entries
entries = []
with open(file_path, 'r') as file:
for line in file:
# Parse the JSON object from each line
data = json.loads(line.strip())
entries.append(data)
# Split the entries into train and validation sets
train_entries, val_entries = train_test_split(entries, test_size=0.2, random_state=42)
# Function to save a list of entries to a specified directory
def save_entries(entries, directory):
for i, entry in enumerate(entries):
# Construct a file name
file_name = f"entry_{i+1}.json"
# Construct the full path
full_path = os.path.join(directory, file_name)
# Write the entry to the file in JSON format
with open(full_path, 'w') as f:
json.dump(entry, f, indent=4)
# Save the train and validation entries to their respective directories
save_entries(train_entries, train_dir)
save_entries(val_entries, val_dir)
print(f"Saved {len(train_entries)} entries to {train_dir}")
print(f"Saved {len(val_entries)} entries to {val_dir}")
Press Shift + Enter
The above code snippet will prepare the data in the format of a dictionary saved in each file that can be accessed for training.
def formatting_func(example):
text = f"### Question: {example['input']}\n ### Answer: {example['output']}"
return text
Press Shift + Enter
Step 3:Load Model and Dataset
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
base_model_id = "mistralai/Mistral-7B-v0.1"
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
model = AutoModelForCausalLM.from_pretrained(base_model_id, quantization_config=bnb_config)
Press Shift + Enter
Loading checkpoint shards: 100%
2/2 [00:09<00:00, 4.39s="" it]="" <="" pre="">
tokenizer = AutoTokenizer.from_pretrained(
base_model_id,
padding_side="left",
add_eos_token=True,
add_bos_token=True,
)
tokenizer.pad_token = tokenizer.eos_token
Press Shift + Enter
def generate_and_tokenize_prompt(prompt):
return tokenizer(formatting_func(prompt))
from datasets import load_dataset
# Define the function that will tokenize the data
def generate_and_tokenize_prompt(example):
# Assuming you have a tokenizer loaded, e.g., tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')
# Replace this with your actual tokenizer and tokenization logic
example['input_ids'] = tokenizer.encode(example['text'], truncation=True, padding='max_length')
return example
# Load the datasets from the JSON files in the directories
train_dataset = load_dataset('json', data_files={'train': f'{train_dir}/.json'})
val_dataset = load_dataset('json', data_files={'validation': f'{val_dir}/.json'})
# Tokenize the datasets
tokenized_train_dataset = train_dataset['train'].map(generate_and_tokenize_prompt)
tokenized_val_dataset = val_dataset['validation'].map(generate_and_tokenize_prompt)
Press Shift + Enter
Out:
Resolving data files: 100%
88/88 [00:00<00:00, 0="" 1="" 22="" 88="" 10323.86it="" s]="" downloading="" data="" files:="" 100%="" [00:00<00:00,="" 121.02it="" extracting="" 33.04it="" generating="" train="" split:="" 1546.61="" examples="" resolving="" 2862.38it="" 138.16it="" 67.14it="" validation="" 987.09="" map:="" 2257.64="" asking="" to="" pad="" max_length="" but="" no="" maximum="" length="" is="" provided="" and="" the="" model="" has="" predefined="" length.="" default padding.="" truncate="" truncation.="" 1434.22="" <="" code="">
import matplotlib.pyplot as plt
def plot_data_lengths(tokenize_train_dataset, tokenized_val_dataset):
lengths = [len(x['input_ids']) for x in tokenized_train_dataset]
lengths += [len(x['input_ids']) for x in tokenized_val_dataset]
print(len(lengths))
# Plotting the histogram
plt.figure(figsize=(10, 6))
plt.hist(lengths, bins=20, alpha=0.7, color='blue')
plt.xlabel('Length of input_ids')
plt.ylabel('Frequency')
plt.title('Distribution of Lengths of input_ids')
plt.show()
Press Shift + Enter
Out:
plot_data_lengths(tokenized_train_dataset, tokenized_val_dataset)
110
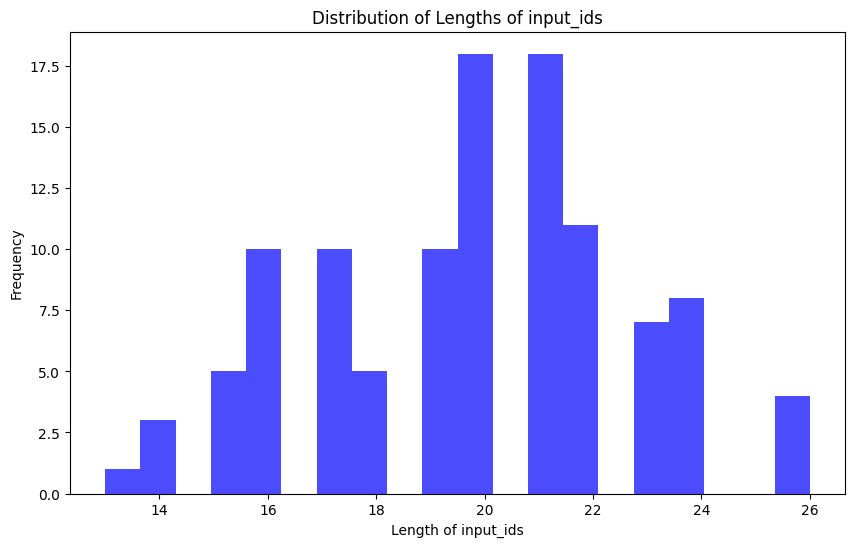
max_length = 512 # This was an appropriate max length for my dataset
def generate_and_tokenize_prompt2(prompt):
result = tokenizer(
formatting_func(prompt),
truncation=True,
max_length=max_length,
padding="max_length",
)
result["labels"] = result["input_ids"].copy()
return result
def formatting_func(example):
# Correct the keys according to your dataset format
text = f"### Question: {example['text']}\n### Answer: {example['response']}"
return text
def generate_and_tokenize_prompt2(example):
# Tokenize the formatted text
result = tokenizer(
formatting_func(example),
truncation=True,
max_length=max_length,
padding="max_length",
)
# Copy the input_ids to create labels for a language modeling task, if necessary
result["labels"] = result["input_ids"].copy()
return result
tokenized_train_dataset = train_dataset.map(generate_and_tokenize_prompt2)
tokenized_val_dataset = val_dataset.map(generate_and_tokenize_prompt2)
Press Shift + Enter
Out:
Map: 100%
88/88 [00:00<00:00, 22="" 1620.17="" examples="" s]="" map:="" 100%="" [00:00<00:00,="" 967.05="" <="" code="">
print(tokenized_train_dataset['train'][1]['input_ids'])
Press Shift + Enter
Out:
[2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 1, 774, 22478, 28747, 315, 11371, 395, 430, 3810, 529, 2235, 304, 506, 264, 524, 5244, 298, 4916, 586, 727, 5411, 6266, 28723, 1824, 1023, 315, 511, 28804, 13, 27332, 26307, 28747, 15102, 1060, 2032, 9796, 778, 7000, 5944, 28725, 2231, 6790, 28748, 14049, 346, 6400, 28725, 808, 8305, 404, 354, 3694, 8063, 28725, 26518, 1255, 520, 1308, 28725, 1149, 395, 2936, 9796, 298, 1813, 14019, 28725, 1388, 15667, 298, 312, 14978, 28723, 2]
eval_prompt = " The following is KRA of Sales Executive: # "
tokenizer = AutoTokenizer.from_pretrained(
base_model_id,
add_bos_token=True,
)
model_input = tokenizer(eval_prompt, return_tensors="pt").to("cuda")
model.eval()
with torch.no_grad():
print(tokenizer.decode(model.generate(**model_input, max_new_tokens=256, repetition_penalty=1.15)[0], skip_special_tokens=True))
Setting pad_token_id to eos_token_id:2 for open-end generation.
The following is KRA of Sales Executive: # 1023
* To identify and develop new business opportunities in the marketplace.
* To manage existing accounts to ensure that they are satisfied with our services, and to maximize their potential for growth.
* To work closely with other departments within the company to ensure that we provide a high level of service to all customers.
* To maintain accurate records of all sales activity, including customer contact details, orders placed, and payments received.
* To attend trade shows and exhibitions as required, in order to promote our products and services.
* To keep up to date with industry trends and developments, so that we can offer our customers the best possible advice and support.
* To be responsible for your own personal development, by attending training courses and keeping abreast of changes in legislation or technology which may affect your role.
from peft import prepare_model_for_kbit_training
model.gradient_checkpointing_enable()
model = prepare_model_for_kbit_training(model)
def print_trainable_parameters(model):
"""
Prints the number of trainable parameters in the model.
"""
trainable_params = 0
all_param = 0
for _, param in model.named_parameters():
all_param += param.numel()
if param.requires_grad:
trainable_params += param.numel()
print(
f"trainable params: {trainable_params} || all params: {all_param} || trainable%: {100 * trainable_params / all_param}"
)
print(model)
Press Shift + Enter
Out:
MistralForCausalLM(
(model): MistralModel(
(embed_tokens): Embedding(32000, 4096)
(layers): ModuleList(
(0-31): 32 x MistralDecoderLayer(
(self_attn): MistralAttention(
(q_proj): Linear4bit(in_features=4096, out_features=4096, bias=False)
(k_proj): Linear4bit(in_features=4096, out_features=1024, bias=False)
(v_proj): Linear4bit(in_features=4096, out_features=1024, bias=False)
(o_proj): Linear4bit(in_features=4096, out_features=4096, bias=False)
(rotary_emb): MistralRotaryEmbedding()
)
(mlp): MistralMLP(
(gate_proj): Linear4bit(in_features=4096, out_features=14336, bias=False)
(up_proj): Linear4bit(in_features=4096, out_features=14336, bias=False)
(down_proj): Linear4bit(in_features=14336, out_features=4096, bias=False)
(act_fn): SiLU()
)
(input_layernorm): MistralRMSNorm()
(post_attention_layernorm): MistralRMSNorm()
)
)
(norm): MistralRMSNorm()
)
(lm_head): Linear(in_features=4096, out_features=32000, bias=False)
)
from peft import LoraConfig, get_peft_model
config = LoraConfig(
r=32,
lora_alpha=64,
target_modules=[
"q_proj",
"k_proj",
"v_proj",
"o_proj",
"gate_proj",
"up_proj",
"down_proj",
"lm_head",
],
bias="none",
lora_dropout=0.05, # Conventional
task_type="CAUSAL_LM",
)
model = get_peft_model(model, config)
print_trainable_parameters(model)
Press Shift + Enter
out:
trainable params: 85041152 || all params: 3837112320 || trainable%: 2.2162799758751914
print(model)
Press Shift + Enter
Out:
PeftModelForCausalLM(
(base_model): LoraModel(
(model): MistralForCausalLM(
(model): MistralModel(
(embed_tokens): Embedding(32000, 4096)
(layers): ModuleList(
(0-31): 32 x MistralDecoderLayer(
(self_attn): MistralAttention(
(q_proj): Linear4bit(
(lora_dropout): ModuleDict(
(default): Dropout(p=0.05, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=4096, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(base_layer): Linear4bit(in_features=4096, out_features=4096, bias=False)
)
(k_proj): Linear4bit(
(lora_dropout): ModuleDict(
(default): Dropout(p=0.05, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=1024, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(base_layer): Linear4bit(in_features=4096, out_features=1024, bias=False)
)
(v_proj): Linear4bit(
(lora_dropout): ModuleDict(
(default): Dropout(p=0.05, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=1024, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(base_layer): Linear4bit(in_features=4096, out_features=1024, bias=False)
)
(o_proj): Linear4bit(
(lora_dropout): ModuleDict(
(default): Dropout(p=0.05, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=4096, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(base_layer): Linear4bit(in_features=4096, out_features=4096, bias=False)
)
(rotary_emb): MistralRotaryEmbedding()
)
(mlp): MistralMLP(
(gate_proj): Linear4bit(
(lora_dropout): ModuleDict(
(default): Dropout(p=0.05, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=14336, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(base_layer): Linear4bit(in_features=4096, out_features=14336, bias=False)
)
(up_proj): Linear4bit(
(lora_dropout): ModuleDict(
(default): Dropout(p=0.05, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=14336, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(base_layer): Linear4bit(in_features=4096, out_features=14336, bias=False)
)
(down_proj): Linear4bit(
(lora_dropout): ModuleDict(
(default): Dropout(p=0.05, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=14336, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=4096, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(base_layer): Linear4bit(in_features=14336, out_features=4096, bias=False)
)
(act_fn): SiLU()
)
(input_layernorm): MistralRMSNorm()
(post_attention_layernorm): MistralRMSNorm()
)
)
(norm): MistralRMSNorm()
)
(lm_head): Linear(
in_features=4096, out_features=32000, bias=False
(lora_dropout): ModuleDict(
(default): Dropout(p=0.05, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=32000, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
)
)
)
)
from accelerate import FullyShardedDataParallelPlugin, Accelerator
from torch.distributed.fsdp.fully_sharded_data_parallel import FullOptimStateDictConfig, FullStateDictConfig
fsdp_plugin = FullyShardedDataParallelPlugin(
state_dict_config=FullStateDictConfig(offload_to_cpu=True, rank0_only=False),
optim_state_dict_config=FullOptimStateDictConfig(offload_to_cpu=True, rank0_only=False),
)
accelerator = Accelerator(fsdp_plugin=fsdp_plugin)
Press Shift + Enter
Out:
Detected kernel version 5.4.242, which is below the recommended minimum of 5.5.0; this can cause the process to hang. It is recommended to upgrade the kernel to the minimum version or higher.
model = accelerator.prepare_model(model)
Press Shift + Enter
!pip install -q wandb -U
import wandb, os
wandb.login()
wandb_project = "journal-finetune"
if len(wandb_project) > 0:
os.environ["WANDB_PROJECT"] = wandb_project
Press Shift + Enter
Out:
huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...
To disable this warning, you can either:
- Avoid using tokenizers before the fork if possible
- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)
Out:
WARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv
WARNING: You are using pip version 21.2.4; however, version 23.3.1 is available.
You should consider upgrading via the '/usr/bin/python -m pip install --upgrade pip' command.
wandb: Logging into wandb.ai. (Learn how to deploy a W&B server locally: https://wandb.me/wandb-server)
wandb: You can find your API key in your browser here: https://wandb.ai/authorize
wandb: Paste an API key from your profile and hit enter, or press ctrl+c to quit:
········
wandb: Appending key for api.wandb.ai to your netrc file: /home/jovyan/.netrc
if torch.cuda.device_count() > 1: # If more than 1 GPU
model.is_parallelizable = True
model.model_parallel = True
Press Shift+Enter
Step 4: Training the model
import transformers
from datetime import datetime
project = "kra-finetune"
base_model_name = "mistral"
run_name = base_model_name + "-" + project
output_dir = "./" + run_name
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
# You might need to resize the token embeddings in your model if you added a new token
model.resize_token_embeddings(len(tokenizer))
trainer = transformers.Trainer(
model=model