For getting Large Language Models (LLMs) to do what you want, prompt engineering has become a sought-after and valuable skill. Knowledge of prompt engineering is useful for A.I researchers and developers. A wide range of common and complex tasks such as question answering and arithmetic reasoning are improved by prompt engineering. Using prompt engineering, developers design efficient and robust prompting methods that work with LLMs.
Prompt Engineering
Prompt Engineering refers to methods for how to communicate with LLM to steer its behavior for desired outcomes without updating the model weights. Prompt engineering is an empirical science that requires heavy experimentation and heuristics since the effect of prompt engineering methods varies widely between models.
Basic Prompting
Zero-shot and few-shot learning are two most basic approaches for prompting the model, pioneered by many LLM papers and commonly used for benchmarking LLM performance.
Zero-Shot
The goal of zero-shot learning is to simply feed the task text to the model and ask for results.
Example of Zero-Shot Prompting
What is the capital of France?
QA format
Q: What is the capital of France?
A:
Few-shot
The few-shot learning method involves a set of high-quality demonstrations that include both inputs and desired outputs. Once the model sees good examples, it can better understand human intentions and criteria for what kinds of answers are needed.
Example of Few-shot prompting
What is the capital of India?
New Delhi
What is the capital of Pakistan?
Islamabad
What is the capital of China?
QA Format:
Q: What is the capital of India?
A: New Delhi
Q: What is the capital of Pakistan?
A: Islamabad
Q: What is the capital of China?
Source:Source

A:
Choice of prompt format, training examples, and the order of the examples can lead to extreme performance difference ranging from a mediocre performance to State of the art (SoTA). Such a huge variance in performance is due to several biases in LLMs. These biases are: (1) Majority label bias (2) Recency bias (3) Common token bias.
- If there is an unbalanced distribution of labels among the examples, then there is a majority label bias
- Models may repeat the label at the end of the model due to recency bias
- Typically, LLM produces more common tokens than rare tokens due to its common token bias
Understanding Large Language Model Settings
We will discuss about two key settings to adjust outputs of LLMs according to requirement.
Temperature - The lower the temperature the more deterministic the results. Increasing the temperature could lead to more randomness.
For fact based QA lower temperature is better for example to multiply two numbers keep the temperature zero. For creative tasks such as writing a poem, higher temperature will results better.
Top_p
This method is also called Nucleus Sampling. We shortlists the top tokens whose sum of likelihoods does not exceed a certain value.
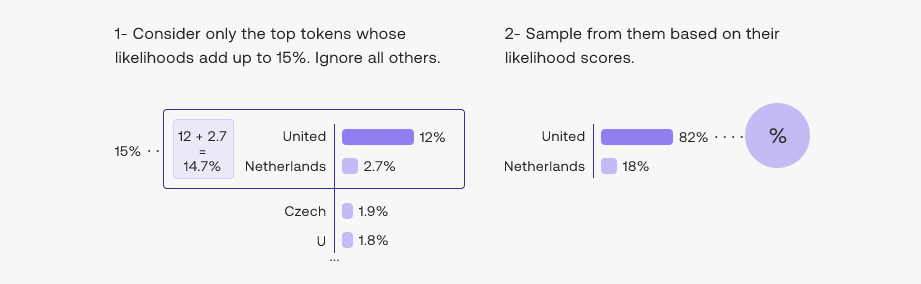
Source:Source
Elements of a Prompt
There are four components of a prompt in general, which are
Instruction - a specific task or instruction you want the model to perform
Context - can involve external information for better responses
Input Data - is the input or question for which we want to find a response
Output Indicator - indicates the type or format of the output.
General Tips for Designing Prompts
- Starting Simple
- Instruction prompting
- Specificity
- Avoid Impreciseness
Starting Simple
It is a good idea to start with simple prompts and then add more elements and context for improving results. To avoid the complexity in designing the prompts you can divide a big task into several smaller tasks and keep iterating to improve results.
Instruction Prompting
Various simple tasks can be achieved by using instruction commands. Some example of instruction commands are "Classify", "Summarize", "Translate" etc.
It is an iterative task and one need to try various instructions before achieving satisfactory results. It is recommend that instructions are placed at the beginning of the prompt, also that some clear separator like "###" is used to separate the instruction and context.
Instruction
Translate the text below to Hindi:
Text: "hello!"
Specificity
It is a good practice to use detailed and very specific prompts. THe details help to build context and improve quality of outputs, providing example is very effective.
Since there is limitation on length of prompt you should make language succinct. It is a heavily iterative process.
Another tip is to avoid saying what not to do but say what to do instead. This encourages more specificity and focuses on the details**.**
Resources to learn more about Prompt Engineering
dair-ai/Prompt-Engineering-Guide