Large language Models have revolutionized natural language processing tasks, by showcasing impressive capabilities in understanding and generating human-like text. However, the dynamic landscape of information poses challenges in adapting these models to new knowledge effectively. Two prominent approaches, Retrieval Augmented Generation (RAG) and Fine-Tuning, have emerged as contenders in addressing this challenge.
Let’s delve into the variances between these strategies, exploring their strengths, weaknesses, and implications for enhancing the knowledge base of LLMs.
Challenges Faced by LLMs
Before delving into the solutions, it's crucial to understand the challenges LLMs face. Factual errors often arise due to various factors such as domain knowledge deficits, outdated information, disremembering, forgetting, and reasoning failures. The pre-training phase, where models learn from vast datasets, plays a pivotal role in shaping their knowledge foundation. Despite the extensive training, these models may falter when faced with new or specific information that is not present in their training data.
Factual Errors: The Pitfalls of Imperfect Information
Factual errors in language models are inaccuracies or discrepancies between the information generated by the model and the facts. These errors can arise from various sources and contribute to the model's inability to provide reliable and accurate information. Understanding the nature of these errors is essential for mitigating their impact on model performance.
-
Domain Knowledge Deficits: Language models are trained on vast datasets that cover a broad range of topics. However, they may lack in-depth knowledge in specific domains, which leads to inaccuracies when generating content in those areas. For instance, a model trained on general knowledge may struggle with detailed medical or scientific information.
-
Outdated Information: Models may not be aware of recent developments or changes, especially if their training data has a cutoff date. This can result in the dissemination of outdated information, which affects the model's reliability in dynamic fields.
-
Disremembering: Despite extensive training, models may fail to memorize specific facts or details. This disremembering can manifest as the model could generate incorrect information or fail to recall essential details.
-
Forgetting: Over time, language models may forget certain information from their training data. This memory decay can lead to factual errors, especially when dealing with infrequently encountered facts.
-
Reasoning Failures: Language models may struggle with complex reasoning tasks that require a deep understanding of context and relationships between different pieces of information. This can result in errors when answering questions or providing explanations.
Knowledge Deficits: Addressing the Gaps in Information
Knowledge deficits go hand-in-hand with factual errors and refer to the areas where language models lack the necessary information. While models may exhibit general knowledge prowess, addressing these deficits is crucial for ensuring their adaptability to new and specialized knowledge domains.
-
Limited Training Data Coverage: Language models may not have encountered sufficient examples or instances related to specific topics during their training. This limited coverage can lead to knowledge deficits, particularly in niche or emerging fields.
-
Inadequate Pre-training: The quality of pre-training data significantly influences the knowledge base of language models. Inadequate pre-training on diverse and representative datasets may result in models with inherent knowledge gaps.
-
Lack of Exposure to Varied Contexts: Models trained on monolithic datasets may lack exposure to diverse contexts and perspectives. This narrow exposure can contribute to knowledge deficits, especially when dealing with multifaceted or culturally nuanced information.
-
Implicit Bias: Language models may inadvertently carry biases present in their training data. This bias can lead to skewed or incomplete representations of certain topics, which contributes to knowledge deficits and inaccuracies.
Knowledge Injection: Fine-Tuning vs. Retrieval Augmented Generation
Fine-Tuning
Fine-tuning is a process that involves adjusting a pre-trained language model on a more specific dataset or task to improve its performance within that particular domain. This approach is particularly useful when models need to be adapted to new or specialized knowledge areas. Fine-tuning can be classified into several types, each with its unique characteristics:
-
Supervised Fine-Tuning: In supervised fine-tuning, the model is trained on labeled input-output pairs. This method often involves presenting the model with task descriptions in natural language and corresponding examples of the desired behavior. While effective for improving overall model quality, supervised fine-tuning may not necessarily impart new knowledge to the model.
-
Reinforcement Learning Fine-Tuning: Another form of fine-tuning leverages reinforcement learning or RL-inspired optimization strategies. Techniques such as reinforcement learning from human feedback, direct preference optimization, and proximal policy optimization are examples of RL-based fine-tuning. These methods focus on improving the overall quality and expected behavior of the model but may not specifically address knowledge breadth.
-
Unsupervised Fine-Tuning: Unsupervised fine-tuning, also known as continual pre-training or unstructured fine-tuning, involves continuing the pre-training phase of the language model in a causal auto-regressive manner. This method capitalizes on the vast knowledge stored during the initial pre-training. Unsupervised fine-tuning aims to inject new knowledge into the model and is often preferred for its efficacy in learning new information.
Fine-tuning, while a valuable tool, comes with challenges such as instability and potential impacts on the model's broader capabilities. Careful consideration of the fine-tuning strategy and its alignment with specific goals is crucial to achieving optimal results.
Retrieval Augmented Generation (RAG)
Retrieval Augmented Generation (RAG) represents a paradigm shift in enhancing language models by incorporating external knowledge sources. This technique is particularly beneficial for knowledge-intensive tasks and involves the following key steps:
-
Knowledge Base Creation: RAG begins with the creation of an auxiliary knowledge base. Relevant information is gathered from the data provided to create a knowledge base. This knowledge base serves as a repository of information that can augment the model's understanding.
-
Embedding and Retrieval: Given an input query, RAG employs an embedding model to represent both the query and the documents in the knowledge base. Retrieval involves finding documents within the knowledge base that resemble the input query. This process is typically facilitated by vector representations of documents.
-
Context Enrichment: Retrieved documents are added to the input query, which enriches the model's context about the subject. This augmented context enhances the model's ability to generate more informed and contextually relevant responses.
RAG has proven effective in addressing both factual errors and knowledge deficits. It allows language models to go beyond their pre-training knowledge and leverage external information for improved performance in various tasks.
Choosing between Fine-Tuning and RAG: Considerations and Trade-Offs
The decision to employ fine-tuning or RAG depends on the specific goals of a task and the nature of the knowledge required. Here are some considerations and trade-offs:
-
Fine-tuning Considerations: Fine-tuning is suitable for tasks where specific, task-oriented improvements are needed. It is effective for refining a model's performance in a particular domain. However, fine-tuning may exhibit instability and might not be the optimal choice for addressing broad knowledge deficits.
-
RAG Considerations: RAG excels in knowledge-intensive tasks where external information is valuable which is provided by feeding data to the knowledge base. It can address both knowledge deficits and factual errors by incorporating diverse knowledge from external sources. RAG's effectiveness relies on the quality and coverage of the knowledge base.
-
Trade-offs: Fine-tuning may provide more control over specific task-related improvements, but it might struggle with broader knowledge adaptation. RAG, while powerful in leveraging external knowledge, depends on the availability and reliability of the knowledge base.
Utilizing E2E Cloud GPU for Implementing Knowledge Injection
Knowledge Injection is a process that enhances machine learning models by integrating external knowledge which is advantageous while dealing with limited or unrepresentative training data. There are several benefits when we use Cloud GPUs. Firstly, the scalability of cloud GPUs allows for a seamless transition from a single GPU for development to multiple GPUs for training larger models or handling extensive datasets. Additionally, the cost-effectiveness of cloud GPUs offers a more economical alternative to maintaining dedicated hardware, especially for irregular usage patterns where charges are incurred only for the resources utilized.
Let’s walk through an example of fine-tuning an LLM vs. the RAG approach and compare their performance with evaluation metrics. To perform this, I used E2E Cloud GPU A100 80 GB with CUDA 11. To learn more about E2E Cloud GPUs, visit the website.
To get started, add your SSH keys by going into Settings.
After creating SSH keys, create a node by going into ‘Compute’.
Now, open your Visual Studio Code and download the extension ‘Remote Explorer’ as well as ‘Remote SSH’. Open a new terminal and login into your local system.
ssh root@
You’ll be logged in remotely with SSH on your local system.
Fine-Tuning LLM Example: Code Implementation
Let’s understand the scenario by code implementation with the same dataset for both approaches.
First, install the dependencies that we are going to use in this implementation.
%pip install -q peft==0.4.0
%pip install -q transformers
%pip install -q datasets
%pip install -q huggingface_hub
%pip install -q evaluate
%pip install -q seqeval
%pip install -q langchain
%pip install -q cohere
%pip install -q pinecone-client
%pip install -q ragas
Import the classes and functions that we are going to need in this implementation.
from transformers import AutoTokenizer
from datasets import load_dataset
from peft import get_peft_model, PromptTuningConfig, TaskType, PromptTuningInit, PeftModel, LoraConfig
from huggingface_hub import notebook_login
from langchain_community.embeddings import CohereEmbeddings
from langchain.vectorstores import Pinecone
from langchain_community.document_loaders import HuggingFaceDatasetLoader
from tqdm import tqdm
from seqeval.metrics import classification_report, f1_score
import pinecone
from pipeline import HuggingFacePipeline
from huggingface_hub import notebook_login
from datasets import load_dataset
from transformers import pipeline
from transformers.pipelines import Processor, QuestionAnsweringPipeline
from sklearn.metrics import average_precision_score, recall_score
import getpass
In this implementation, we will use Flan T5 XXL, which you can find here. We’ll tokenize the model and make it our foundation model.
# Specify the pre-trained model name you want to use
model_name = "google/flan-t5-xxl"
# Load the tokenizer associated with the pre-trained model
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Load the pre-trained causal language model using the specified model name
foundation_model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
Load the dataset, which can be found here. We’ll map the dataset to the tokenizer for one of the columns named system_prompt. We’ll select a range of datasets to work with.
# Load the "OpenOrca" dataset using the load_dataset function from the datasets library
data = load_dataset("Open-Orca/OpenOrca")
# Tokenize the dataset using the specified tokenizer
data = data.map(lambda samples: tokenizer(samples["system_prompt"]), batched=True)
# Select a subset of the training samples (first 50 samples in this case)
train_sample = data["train"].select(range(50))
# Display the selected subset of training samples
display(train_sample)
Let’s set the LoRA configuration for fine-tuning the foundation model.
lora_config = LoraConfig(
r=16,
lora_alpha=32,
target_modules=["q", "v"],
lora_dropout=0.05,
bias="none",
task_type=TaskType.SEQ_2_SEQ_LM
)
Using LoRA configuration, we will set the final PEFT model from the foundation model, and see the trainable parameters, all parameters, and the trainable percentage.
peft_model = get_peft_model(foundation_model, lora_config)
print(peft_model.print_trainable_parameters())
The following will be the result:
trainable params: 18,874,368 || all params: 11,154,206,720 || trainable%: 0.16921300163961817
Now, we will make a directory to store the PEFT model outputs.
%mkdir /root/working_dir
We’ll set the training arguments for our new fine-tuned model.
# Define the output directory for storing Peft model outputs
output_directory = os.path.join("/root/working_dir", "lora_outputs")
# Create the working directory if it doesn't exist
if not os.path.exists("/root/working_dir"):
os.mkdir("/root/working_dir")
# Create the output directory if it doesn't exist
if not os.path.exists(output_directory):
os.mkdir(output_directory)
# Define training arguments for the Peft model
training_args = TrainingArguments(
output_dir=output_directory, # Where the model predictions and checkpoints will be written
no_cuda=True, # This is necessary for CPU clusters.
auto_find_batch_size=True, # Find a suitable batch size that will fit into memory automatically
learning_rate=1e-3, # Higher learning rate than full fine-tuning
num_train_epochs=5 # Number of passes to go through the entire fine-tuning dataset
)
Then, we’ll train the model using the sample data and the Data Collator.
# Enable gradient checkpointing in the Peft model's configuration
peft_model.config.gradient_checkpointing = True
# Create a Trainer instance for training the Peft model
trainer = Trainer(
model=peft_model, # We pass in the PEFT version of the foundation model,
args=training_args, # Training arguments specifying output directory, GPU usage, batch size, etc.
train_dataset=train_sample, # Training dataset
data_collator=DataCollatorForLanguageModeling(tokenizer, mlm=False) # mlm=False indicates not to use masked language modeling
)
# Start the training process
trainer.train()
We’ll save the fine-tuned model using the output directory and the timestamp.
# Record the current time for creating a unique Peft model path
time_now = time.time()
# Create a path for saving the Peft model using the output directory and timestamp
peft_model_path = os.path.join(output_directory, f"peft_model_{time_now}")
# Save the trained Peft model to the specified path
trainer.model.save_pretrained(peft_model_path)
Now, we'll load the trained PEFT model and use the foundation model for prompt tuning.
# Load the trained Peft model from the specified path using the PeftModel class
loaded_model = PeftModel.from_pretrained(
foundation_model, # The base model to be used for prompt tuning
peft_model_path, # The path where the trained Peft model is saved
is_trainable=False # Indicates that the loaded model should not be trainable
)
We’ll take a test set, and set a metric to evaluate the fine-tuned model.
test_dataset = data['train'].train_test_split(test_size=0.2)['test']
# Metric
metric = f1_score # Replace with the actual metric you want to use
# Assuming 'loaded_model' and 'tokenizer' are already defined in your code
def get_labels_from_dataset(sample):
if 'labels' in sample:
# Replace -100 in the labels as we can't decode them.
labels = np.where(sample['labels'] != -100, sample['labels'], tokenizer.pad_token_id)
return tokenizer.decode(labels, skip_special_tokens=True).split()
else:
# Handle the case where 'labels' key is not present in the sample
# You may need to adjust this based on your dataset structure
return []
def evaluate_peft_model(sample, max_target_length=50):
# Generate summary
input_ids_tensor = torch.tensor([sample["input_ids"]]) # Add a batch dimension
outputs = loaded_model.generate(input_ids=input_ids_tensor, do_sample=True, top_p=0.9, max_length=max_target_length)
prediction = tokenizer.decode(outputs[0], skip_special_tokens=True).split()
# Get labels from the dataset
labels = get_labels_from_dataset(sample)
# Some simple post-processing
return prediction, labels
# Run predictions
# This can take some time
test_sample = test_dataset.select(range(10))
predictions, references = [], []
for sample in tqdm(test_sample):
p, l = evaluate_peft_model(sample)
if p and l: # Skip empty predictions and references
predictions.append(p)
references.append([l]) # Wrap the reference in a list
# Check if there are non-empty predictions and references with the same length
if all(predictions) and all(references) and len(predictions) == len(references):
# Compute metric
results = metric(references, predictions)
# Print results
print(f"seqeval F1 score: {results*100:.2f}%")
else:
print("Inconsistent number of samples in predictions and references.")
From the evaluation we get the following results:
seqeval F1 score: 67.70%
The evaluation F1 score is 67.7%, which is not much good as we can see.
RAG Example: Code Implementation
For implementing the evaluation of the RAG approach, let’s start with the setting of the Cohere API key, which we’ll be using for the embeddings.
os.environ["COHERE_API_KEY"] = "your-api-key"
Let’s load the dataset again.
dataset_name = "Open-Orca/OpenOrca"
page_content_column = "system_prompt"
loader = HuggingFaceDatasetLoader(dataset_name, page_content_column)
data = loader.load()
We’ll take a sample of the data.
data_sample = data[:15]
We’ll split the data into chunks using the text splitter.
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=150)
docs = text_splitter.split_documents(data_sample)
Then, we’ll create the embeddings using the model “embed-english-light-v3.0”. Cohere has many models for different purposes, but here we are using this one.
embeddings = CohereEmbeddings(model="embed-english-light-v3.0")
Now, we’ll set the Pinecone API key and the environment.
os.environ["PINECONE_API_KEY"] = getpass.getpass("Pinecone API Key:")
os.environ["PINECONE_ENV"] = getpass.getpass("Pinecone Environment:")
After that, we’ll initialize the Pinecone set up.
# initialize pinecone
pinecone.init(
api_key=os.getenv("PINECONE_API_KEY"), # find at app.pinecone.io
environment=os.getenv("PINECONE_ENV"), # next to api key in console
)
index_name = "my_index"
We’ll create an index to store the embeddings.
# First, check if our index already exists. If it doesn't, we create it
if index_name not in pinecone.list_indexes():
# we create a new index
pinecone.create_index(name=index_name, metric="cosine", dimension=384)
Then, we will initiate the Pinecone with docs, embeddings, and index.
docsearch = Pinecone.from_documents(docs, embeddings, index_name=index_name)
We’ll load the model to pass the query.
# Specify the model name you want to use
model_name = "google/flan-t5-xxl"
# Load the tokenizer associated with the specified model
tokenizer = AutoTokenizer.from_pretrained(model_name, padding=True, truncation=True, max_length=512)
# Define a question-answering pipeline using the model and tokenizer
question_answerer = pipeline(
"question-answering",
model=model_name,
tokenizer=tokenizer,
return_tensors='pt'
)
# Create an instance of the HuggingFacePipeline, which wraps the question-answering pipeline
# with additional model-specific arguments (temperature and max_length)
llm = HuggingFacePipeline(
pipeline=question_answerer,
model_kwargs={"temperature": 0.7, "max_length": 512},
)
Then, we’ll create a retriever object, and pass the model in the RetrievalQA chain.
retriever = docsearch.as_retriever(search_kwargs={"k": 4})
# Create a question-answering instance (qa) using the RetrievalQA class.
# It's configured with a language model (llm), a chain type "refine," the retriever we created, and an option to not return source documents.
qa = RetrievalQA.from_chain_type(llm=llm, chain_type="refine", retriever=retriever, return_source_documents=False)
Now, we’ll evaluate our RAG approach using RAGAS.
def map_to_squad_features(example):
return {
'question': example['question'],
'contexts': example['system_prompt'],
'answer': example['response'],
# 'ground_truths' might need to be filled with appropriate data
'ground_truths': None
}
# Apply the function to the dataset
squad_like_data = data_sample.map(map_to_squad_features)
result = evaluate(
dataset = squad_like_data ,
metrics=[
context_precision,
context_recall,
faithfulness,
answer_relevancy,
],
)
df = result.to_pandas()
df
The following is the result:

The following will be the RAGAS score for each question:
You can see from the results that the ragas_score for each question is performing better than the fine-tuned model.
Comparative Knowledge Injection Observations
As we compared the evaluation metrics of the fine-tuned LLM model and the RAG model on the text classification use case, we saw that the ragas_score is performing better than the score of the fine-tuned model. Let’s see how the fine-tuned model and RAG perform with other use cases.
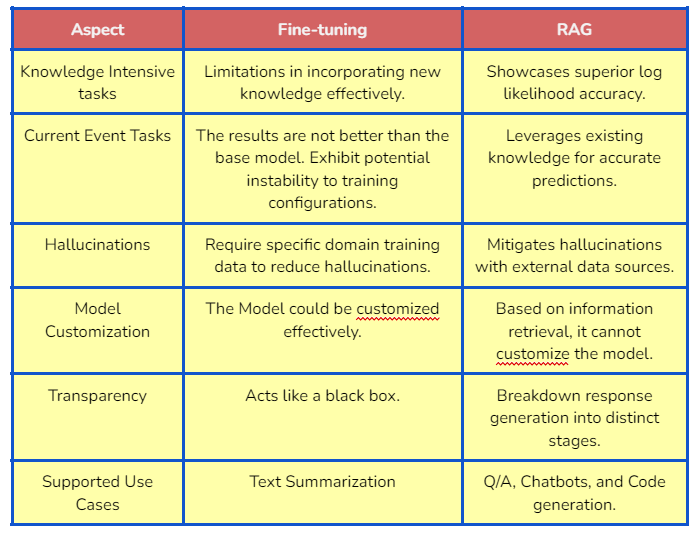
However, RAG use cases can be more powerful if we incorporate the fine-tuned model with it.
Conclusion
In the quest to enhance LLMs' knowledge bases, understanding the variances between retrieval augmented generation and fine-tuning is pivotal. While fine-tuning shows promise, especially when combined with RAG, the latter emerges as a more reliable choice for knowledge injection, as we saw in the examples.
Fine-tuning and Retrieval Augmented Generation represent powerful tools for refining language models, each with its unique strengths and considerations. The choice between these approaches often involves a balance between task specificity, model stability, and the need for external knowledge integration.
In many cases, a synergistic approach that combines aspects of both fine-tuning and RAG may offer a comprehensive solution as we saw in the comparative observations. Leveraging the strengths of fine-tuned models along with the context enrichment provided by external knowledge through RAG can contribute to the development of more robust and adaptable language models.