What Is LangGraph and Why Is It So Powerful?
LangGraph is a specialized library within the LangChain ecosystem, designed to enhance the development of stateful, multi-actor applications utilizing large language models (LLMs). It addresses common limitations faced by traditional LLM frameworks, particularly in maintaining context, memory, and state across interactions. This capability is crucial for creating more efficient AI applications, especially those that require complex decision-making processes and iterative workflows.
Key Features of LangGraph
- Stateful Workflows: LangGraph allows for the creation of applications that can remember past interactions and maintain context, which is essential for applications like conversational agents. This statefulness enables the system to provide personalized responses based on user history and preferences.
- Cyclic Graphs: Unlike traditional directed acyclic graphs (DAGs), LangGraph supports cyclic flows, allowing for more complex interactions and decision-making processes. This feature is particularly useful for applications that require agents to revisit previous states or information.
- Persistence and Control: The framework includes built-in persistence features that allow developers to save the state of applications after each step. This is beneficial for human-in-the-loop scenarios where human intervention may be needed to approve actions taken by the AI.
- Integration with Other Tools: LangGraph can be used independently or in conjunction with other tools in the LangChain ecosystem, such as LangSmith, enhancing its utility in various applications.
Applications of LangGraph
LangGraph is versatile and can be applied across various domains. Some notable applications include:
- Conversational Agents: It excels in building chatbots that require a deep understanding of user context over multiple interactions, improving user experience through personalized dialogue.
- Task Automation: The framework can automate complex tasks by managing workflows that involve multiple steps and decision points, making it suitable for business process automation.
- Data Enrichment: LangGraph can be employed to create agents that enrich data by interacting with users or external systems to gather additional information, thereby enhancing data quality and relevance.
- Long-running Processes: The ability to handle persistent states makes it ideal for applications that need to maintain context over extended periods or across sessions, such as customer support systems or interactive learning environments.
Here, we’ll guide you step-by-step through building an AI agent designed to answer questions about weather, travel, and general information. We’ll harness the capabilities of LangGraph to structure the agent, paired with the advanced Llama 3.1 language model to deliver intelligent and accurate responses. The entire project will be developed and deployed on the E2E Cloud platform, offering a streamlined environment tailored for AI application development in the cloud.
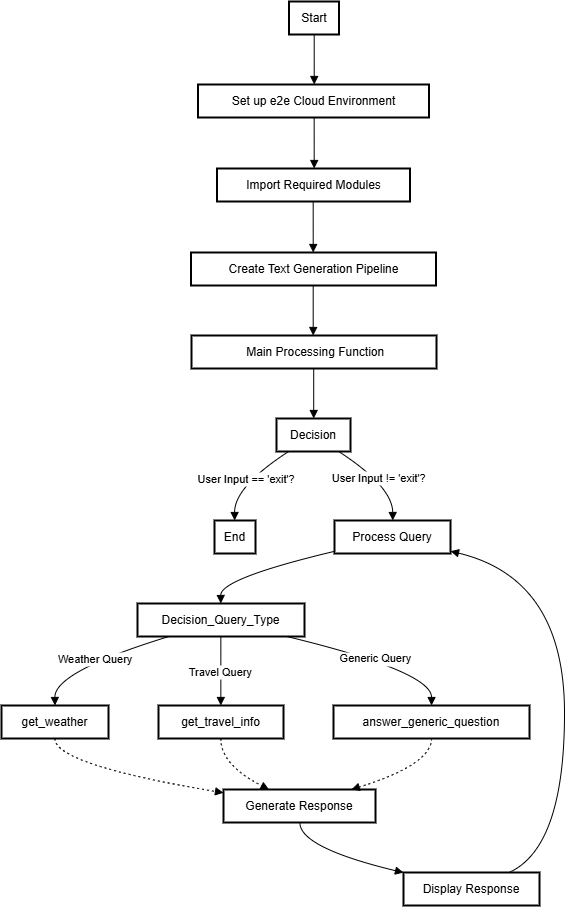
Let’s Code
Launching E2E Node
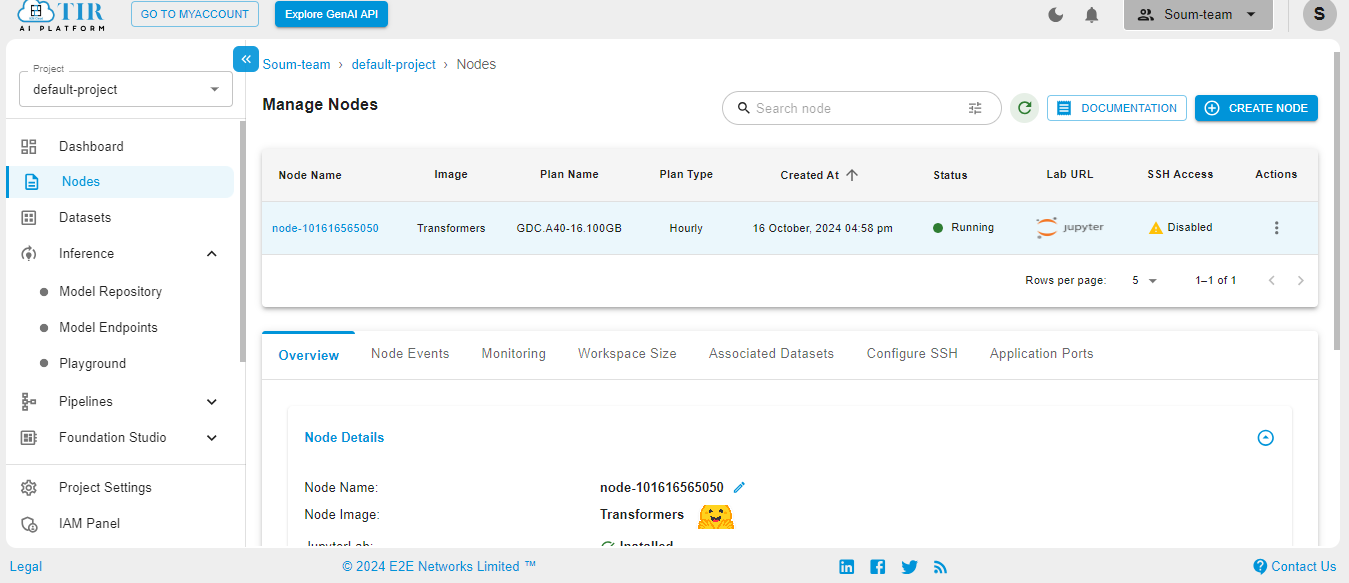
Get started with E2E AI / ML Platform here. Here are some screenshots to help you navigate through the platform.
Go to the Nodes option on the left side of the screen and open the dropdown menu. In our case, 100GB will work.
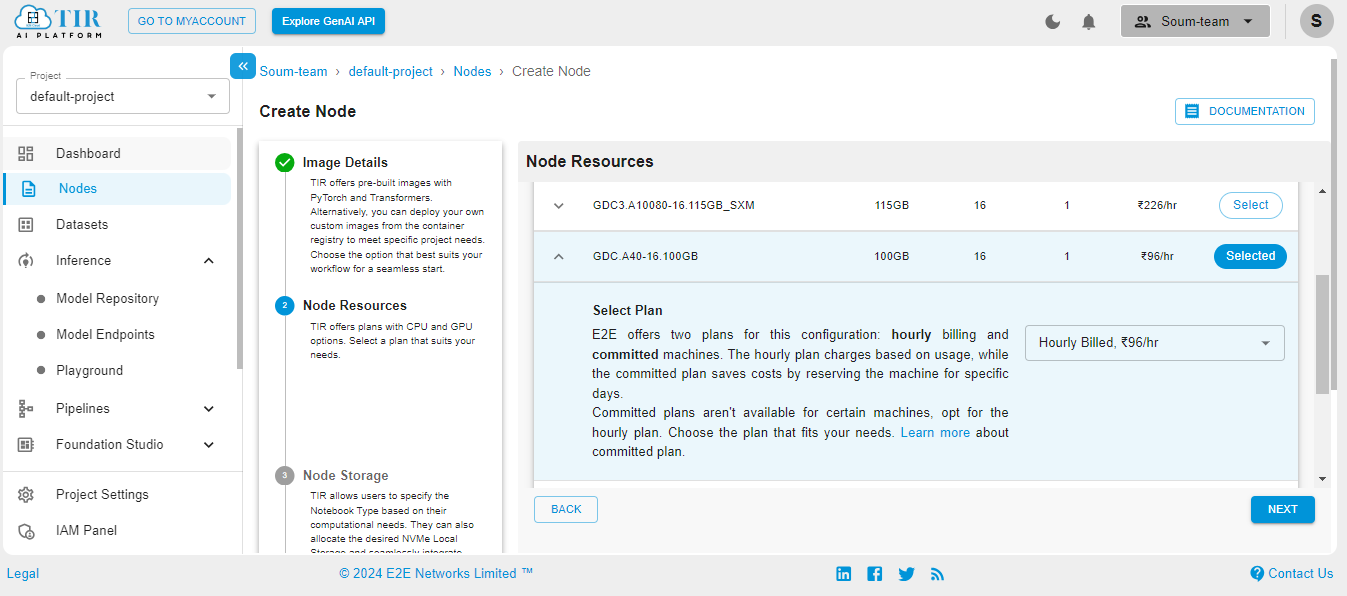
Select the size of your disk as 50GB – it works just fine for our use case. But you might need to increase it if your use case changes.
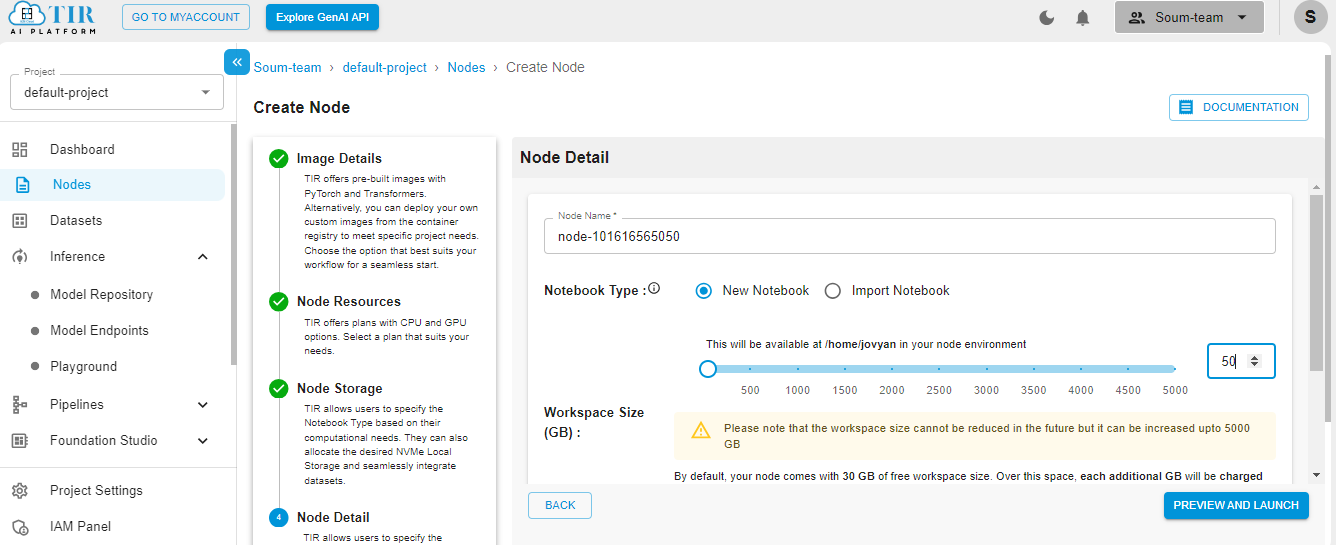
Hit Launch to get started with your E2E Node.
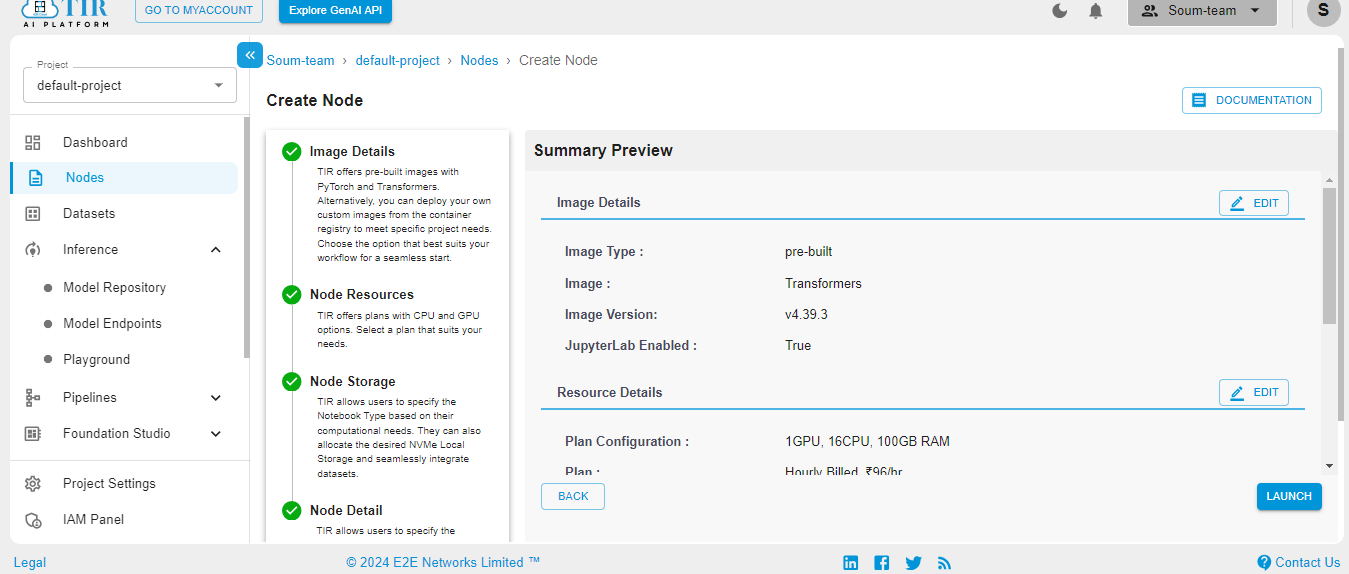
When the Node is ready to be used, it’ll show the Jupyter Lab logo. Hit on the logo to activate your workspace.
Select the Python3 pykernel, then select the option to get your Jupyter Notebook ready. Now you are ready to start coding.

Step 1: Setting Up the Environment
First, we need to install the necessary libraries. In your E2E environment, run the following command:
Step 2: Importing Required Modules
- transformers: A library by Hugging Face that provides tools to easily integrate state-of-the-art transformer models like Llama 3.1 for tasks such as text generation and NLP.
- torch: A framework for deep learning and tensor computations, used here to optimize model execution and handle large language models efficiently.
- langgraph.graph: A library to structure and manage tasks in a graph format, enabling logical flow and modular functionality for building intelligent agents.
- AutoTokenizer: A class from transformers to load pre-trained tokenizers for processing and converting text into token IDs for the model.
- AutoModelForCausalLM: A class from transformers to load pre-trained causal language models like Llama 3.1 for generating coherent and context-aware text.
Step 3: Loading the Llama 3.1 Model
Now, we'll load the Llama 3.1 model and tokenizer. E2E provides efficient access to large models like Llama 3.1:
Step 4: Creating a Text Generation Pipeline
We'll create a text generation pipeline using the loaded model. This pipeline will be the core of our AI agent's response generation:
Step 5: Defining Agent Functions
Now, let's define three functions for our agent: one for weather, one for travel, and one for generic questions.
Step 6: Creating the Graph Structure with LangGraph
LangGraph allows us to create a structured flow for our agent's decision-making process.
This graph structure enables our agent to route queries to the appropriate specialized function.
Step 7: Defining the Main Processing Function
This function acts as the brain of our AI agent, routing queries to the appropriate node based on their content.
Step 8: Setting Up the Conversation Loop
Finally, we'll create an interactive loop to handle user inputs and generate responses.
Example Usage
- Travel Query: Ask about weather or travel: what time will it take to travel from Delhi to Mumbai by road?
Response: From Delhi to Mumbai by road it will take you 20 hours to reach. The best route to travel from Delhi to Mumbai is via the NH 8 and NH 3. The total distance is 1,350 kms. The cost of traveling from Delhi to Mumbai by road will be approximately Rs. 1,500. You can also take the train or fly to Mumbai from Delhi. It is recommended to take the train or fly to Mumbai from Delhi if you are on a tight schedule. 2. **Weather Query:**Ask about weather or travel: what is the current weather in Delhi?
Response: Delhi, the capital city of India, experiences a wide range of weather conditions throughout the year. The current weather conditions in Delhi can be described as warm and humid with occasional rainfall. The temperature in Delhi is currently around 30°C (86°F), and the humidity is relatively high at around 60%. The wind speed is moderate, with a gentle breeze blowing from the south-west. The sky is mostly clear, with a few scattered clouds. Overall, the weather in Delhi is pleasant and comfortable, making it an ideal destination for tourists and locals alike.
To Summarize
In this blog post, we've created an AI agent using LangGraph and Llama 3.1 that can answer questions about weather, travel, and general information related to India. This agent demonstrates the power of combining structured graph-based approaches with large language models to create informative and context-aware conversational systems. Remember that the responses generated by this AI agent are based on the Llama 3.1 model's training data and may not always reflect real-time or completely accurate information.
Why Choose E2E Cloud?
You can see more Llama 3.1 applications on E2E’s premium TIR AI/ML Platform here and here.
What E2E Cloud offers are the following:
- Unbeatable GPU Performance: Access top-tier GPUs like H200, H100, and A100—ideal for state-of-the-art AI and big data projects.
- India’s Best Price-to-Performance Cloud: Whether you’re a developer, data scientist, or AI enthusiast, E2E Cloud delivers affordable, high-performance solutions tailored to your needs.
Get Started Today
Ready to supercharge your projects with cutting-edge GPU technology?
- Launch a cloud GPU node tailored to your project needs.
E2E Cloud is your partner for bringing ambitious ideas to life, offering unmatched speed, efficiency, and scalability. Don’t wait—start your journey today and harness the power of GPUs to elevate your projects.